Baidu AI Researchers Introduce SE-MoE That Proposes Elastic MoE Training With 2D Prefetch And Fusion Communication Over Hierarchical Storage
Machine learning and deep learning have gained popularity in domains, like computer vision (CV) and natural language processing (NLP), which require analyzing large amounts of data such as images and text. As a result, many computational resources are needed for data processing. Thus, to address the above concern, sparsely activated neural networks based on Mixture-of-Experts (MoE) have been utilized for training the larger models with low or no supplementary computational resources while achieving improved training results.
Besides the benefits of using MoE, there are still various challenges faced by MOE models, as described below.
- Computational challenges: Because of the mismatch in the expert selection, the MoE models make training less effective. Various solutions, such as introducing supplementary loss, stochastic experts, and so on, are used to avoid this. However, this leads to a greater emphasis on scheduling than computing, putting more significant pressure on CPUs than GPUs.
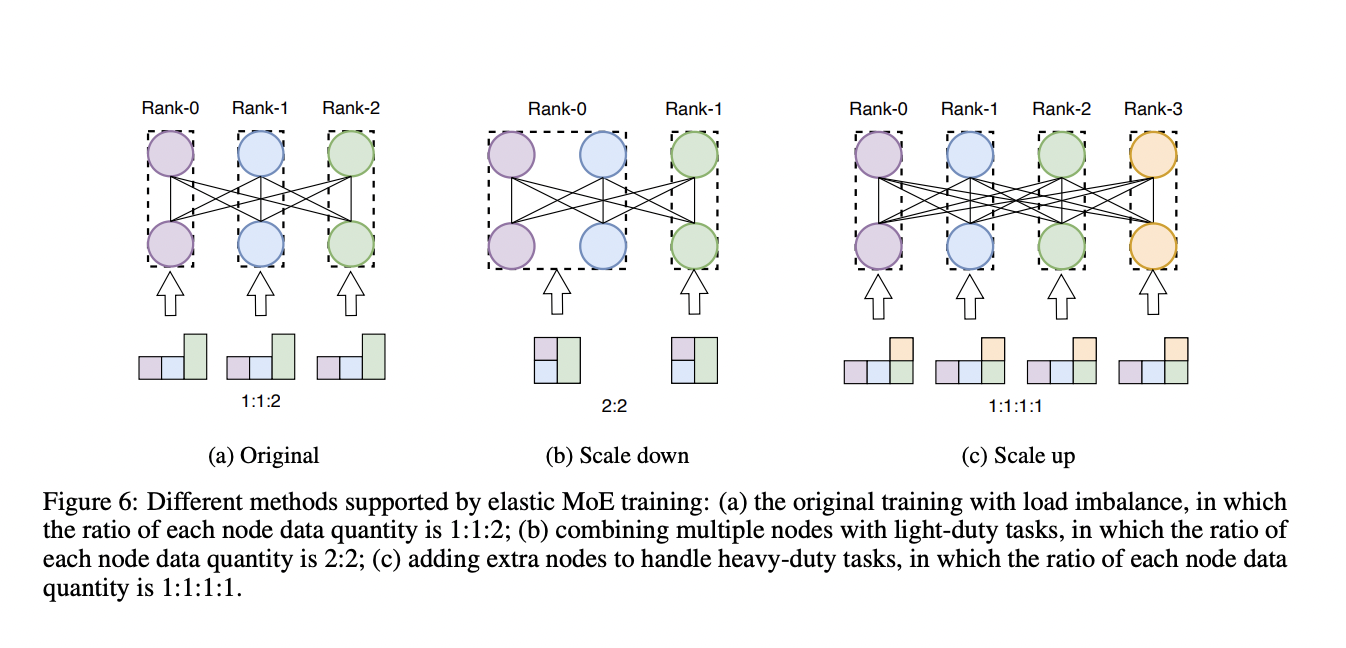
- Communicational challenges: The parameter activation in MoE is intimately linked to the input data. This results in the dreaded load imbalance when the data is unbalanced, even though the routing methods are efficient. When multi-task training is necessary for cross-device communication, the load imbalance can cause the devices’ stride to change, prompting mutual waiting for synchronous communication. However, this results in performance degradation.
- Storage limitations: Memory storage in computing devices limits MoE models significantly. The performance of dense activated models is frequently determined by training time than the memory required. All the storage contains the same type of memory, but it varies in I/O latency, resulting in different waiting times for the parameters. Hence, the challenge is to develop a unified and effective storage management system to facilitate sparsely activated networks.
Accordingly, to overcome the challenges faced by the MoE, this paper proposes an innovative amalgamated framework for MoE training and inference. The paper’s significant contribution includes a novel SE-MoE, a distributed system capable of scaling MoE models to trillions of parameters and completely exploiting the clusters, including High Bandwidth Memory, CPU memory, and SSDs in achieving effective training scheduling. Dynamic graph scheduling utilizes an innovative inference approach based on ring memory to overlap computation and communication as much as feasible, resulting in more efficient inference performance without extra machines for larger-scale MoE models. Additionally, various methods like load balancing are utilized by the SE-MoE to advance the performance without any additional resources.
The MoE training is depicted in Figure 1.
The experiments are divided into two parts: evaluation of training efficiency and inference performance. The results show that the training efficiency of the SE-MoE outperforms the standard MoE system DeepSpeed by achieving nearly 28 % acceleration in single-node training and a minimum of 33% speedup in multiple-node training for the MoE models having over 100-billions parameters. Furthermore, SE-MoE reduces each rank’s GPU memory use by roughly 12 GB. While for the inference performance on MoE models with more than 200 billion parameters, SE-MoE achieves a nearly 13 % speedup over DeepSpeed.
Also, the experimentations are performed to evaluate the elastic MoE training and to check the effect of embedded partitions on MoE architecture. The results proved that implementing the embedding partition method in a single system may effectively minimize the GPU memory usage. However, the proposed solution decreases GPU memory by 22.4 %, 24.2 %, and 26.3 % while enhancing throughput by 4.2 %, 11.2 %, and 15.6 %, respectively, when the hidden size increases.
Hence, this paper proposed the SE-MoE model, MoE training, and an inference system that can necessitate well for NLP and CV domains. The study may be expanded to find a unified spare training and inference system that considers parameter severity and scheduling in several dimensions. Besides, the unified system will successfully overcome communication, processing, and storage limitations in sparse training.
This Article is written as a summay by Marktechpost Staff based on the Research Paper 'SE-MOE: A SCALABLE AND EFFICIENT MIXTURE-OF-EXPERTS DISTRIBUTED TRAINING AND INFERENCE SYSTEM'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper, and Github. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.