Baidu And PCL Team Introduce ERNIE 3.0 Titan: A Pre-Training Language Model With 260 Billion Parameters

With recent breakthroughs in AI, humans have become more reliant on AI to address real-world problems. This makes humans’ ability to learn and act on knowledge just as essential as a computer’s. Humans learn and gather information through learning and experience to understand everything from their immediate surroundings. The ability to comprehend and solve issues, and separate facts from absurdities, increases as the knowledge base grows. However, such knowledge is lacking in AI systems, restricting their ability to adapt to atypical problem data.
Previous studies show that pre-trained language models improve performance on various natural language interpretation and generating tasks.
A recent work of researchers at Baidu, in collaboration with Peng Cheng Laboratory (PCL), release PCL-BAIDU Wenxin (or “ERNIE 3.0 Titan”), a pre-training language model with 260 billion parameters. It is the world’s first knowledge-enhanced multi-hundred billion parameter model and its largest Chinese singleton model.
Titan has a dense model structure different from the sparse Mixture of Experts (MoE) system. The model is trained on a vast knowledge graph and massive unstructured data, excelling at natural language understanding (NLU) and generation (NLG). Titan has achieved SOTA outcomes in over 60 NLP tasks, including machine reading comprehension, text categorization, and semantic similarity, among others. The model also performs well in 30 few-shot and zero-shot benchmarks. This shows that it can generalize across various downstream tasks with a small quantity of labeled data and decrease the threshold of recognition.

Controllable and credible learning algorithms
Self-supervised pre-training allows AI to grow the number of parameters and tap into larger, unlabeled datasets. Recent breakthroughs have been made as a result of the growing popularity of the technique, particularly in natural language processing (NLP). To ensure that the model can generate fair and cohesive messages, the team has proposed a controllable learning algorithm and a credible learning algorithm. With this, the model can compose the provided genre, sentiment, duration, topic, and keywords in a targeted, controllable manner. This approach uses a self-supervised adversarial learning framework to train the model to identify bogus, synthesized language from real-world human language.
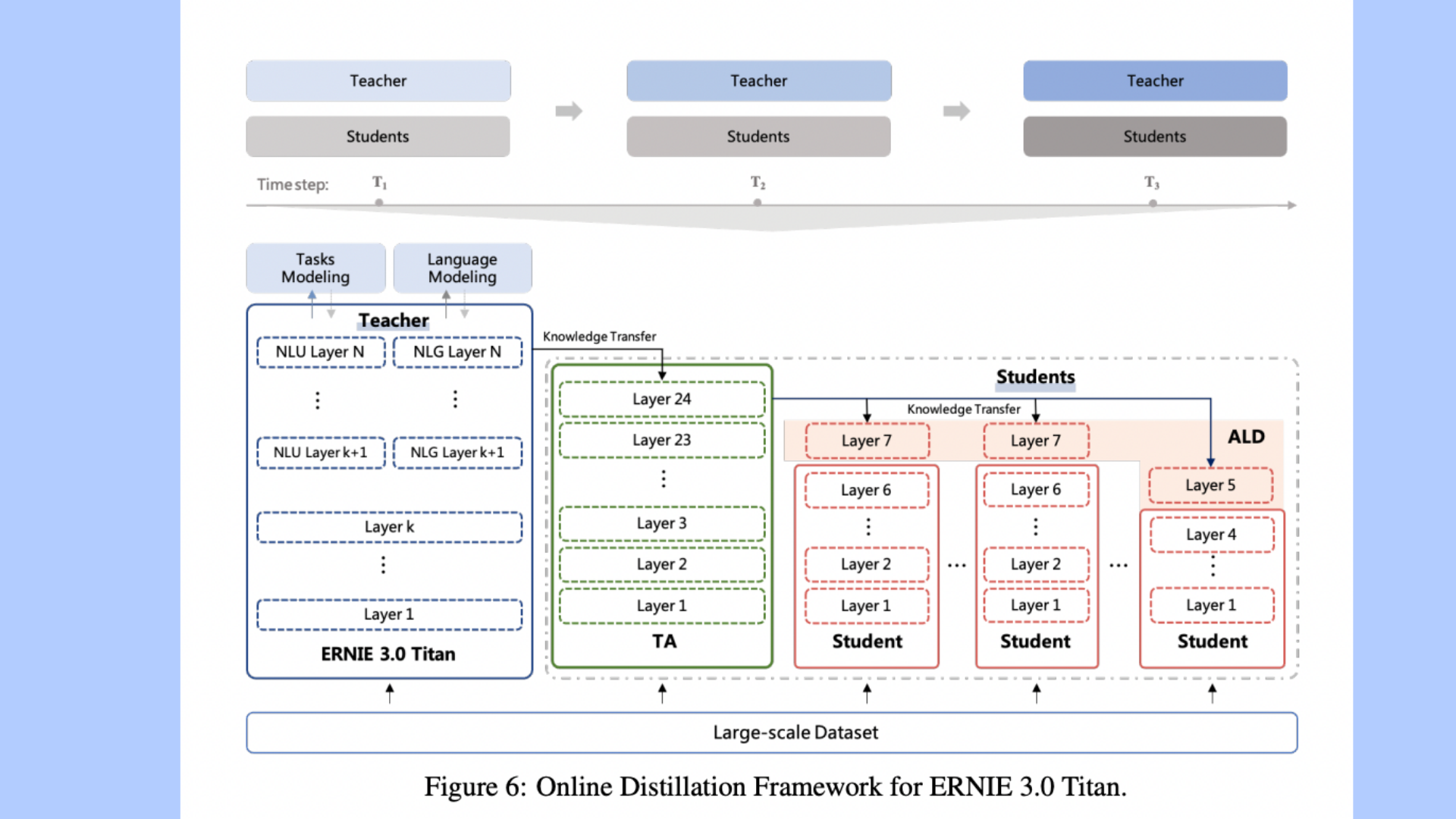
Online distillation for environment-friendly AI models
Large-scale models require a lot of resources for training and inference. To that end, the team employed a teacher-student compression (TSC) strategy to build ERNIE 3.0 Titan, a less expensive student model that mimics the teacher model. This technique sends knowledge signals from the instructor model to several student models of various sizes on a regular basis. Unlike traditional distillation, this method can save a large amount of energy due to the instructor model’s extra distillation computations and the repetitive information transmission of several student models.
The researchers also discovered that the diameters of ERNIE 3.0 Titan and the student model varied by a factor of a thousand. This makes model distillation extremely difficult. To bridge this knowledge gap, they used the so-called teacher-assistant paradigm. The student version of ERNIE 3.0 Titan improved the accuracy of 5 tasks by 2.5 percent compared to the BERT Base model, which has twice as many parameters as the student model. The accuracy is enhanced by 3.4 percent compared to the RoBERTa Base of the same scale.
End-to-end adaptive distributed training
Because the performance of large-scale language models (LLMs) may be continually enhanced by increasing the model’s scale, the number of parameters has expanded exponentially. However, training and inferencing a model with over a hundred billion parameters is extremely difficult and puts a lot of strain on the infrastructure.
On PaddlePaddle, they created an end-to-end distributed training architecture to meet flexible and adaptive needs. It includes resource allocation, model partition, task placement, and distributed execution. With all this, the framework is geared to industrial applications and production situations.
Experiments reveal that ERNIE 3.0 Titan can be efficiently trained in parallel across thousands of AI processors using this framework. Furthermore, by employing resource-aware allocation, the model’s training performance was improved by up to 2.1 times.
Paper: https://arxiv.org/pdf/2112.12731.pdf
Source: http://research.baidu.com/Blog/index-view?id=165
Suggested
Credit: Source link
Comments are closed.