Baidu Researchers Introduce PP-Matting: A Trimap-Free Architecture That Can Achieve High-Accuracy Natural Image Matting
This Article Is Based On The Research Paper 'PP-Matting: High-Accuracy Natural Image Matting'. All Credit For This Research Goes To The Researchers Of This Paper 👏👏👏 Please Don't Forget To Join Our ML Subreddit
One of the most significant challenges in computer vision is natural image matting, a process of precisely predicting the target foreground’s per-pixel opacity from an image. This task has many uses in image editing and composition. Basic segmentation methods that rely on a binary pixel classification system ignore the shifting opacity of foreground/background edge pixels, resulting in harsh, excessively contrastive margins surrounding the foreground subject.
Recent deep learning-based natural picture matting techniques have been proven to improve fine-grained detail in these areas by estimating the per-pixel opacity of the target foreground. However, these techniques rely on user-supplied trimaps as an auxiliary input, limiting their real-world application. Trimap is a crude image segmentation into three parts: foreground, background, and transition (regions with unknown opacity). The majority of users struggle to create a trimap. In some circumstances, such as live video, it is not possible to offer the trimap.
Trimap-free techniques have recently been developed, which do not require a user-supplied trimap as an auxiliary input. Trimap is replaced with a more accessible background image. Performance suffers considerably when the given background image is significantly different from the real background, such as in a dynamic setting. As a result, utilizing the background image as input is still inflexible, but using a single image as input would be more practical.

The methods divide the trimap-free prediction into two tasks: semantic segmentation and matting. The segmentation task automatically uses a single image to build a three-class mask. It is then concatenated with the original image as input to the matting task. However, if the first segmentation task produces an inaccurate mask, the multi-stage techniques may present the problem of accumulative error. Furthermore, the multi-stage model’s training is complex.
Previously developed single-stage approaches overcome the multi-stage limitation by allowing the model to be trained from start to finish without intermediate results generation. However, they have trouble aggregating semantic and detail information, and they cannot perform high-accuracy image matting.
Researchers at Baidu Inc. recently published a study titled “PP-Matting: High-Accuracy Natural Image Matting,” which offers a semantic-aware architecture called PP-Matting that delivers high-accuracy image matting. PP-Matting uses a single image as input and does not require any auxiliary data. This makes end-to-end training of the entire network simple.

The two-branch architecture efficiently extracts both detail and semantic information simultaneously. The appropriate interaction of the two branches enables the network to accomplish improved semantic-aware detail prediction with a guidance flow mechanism.
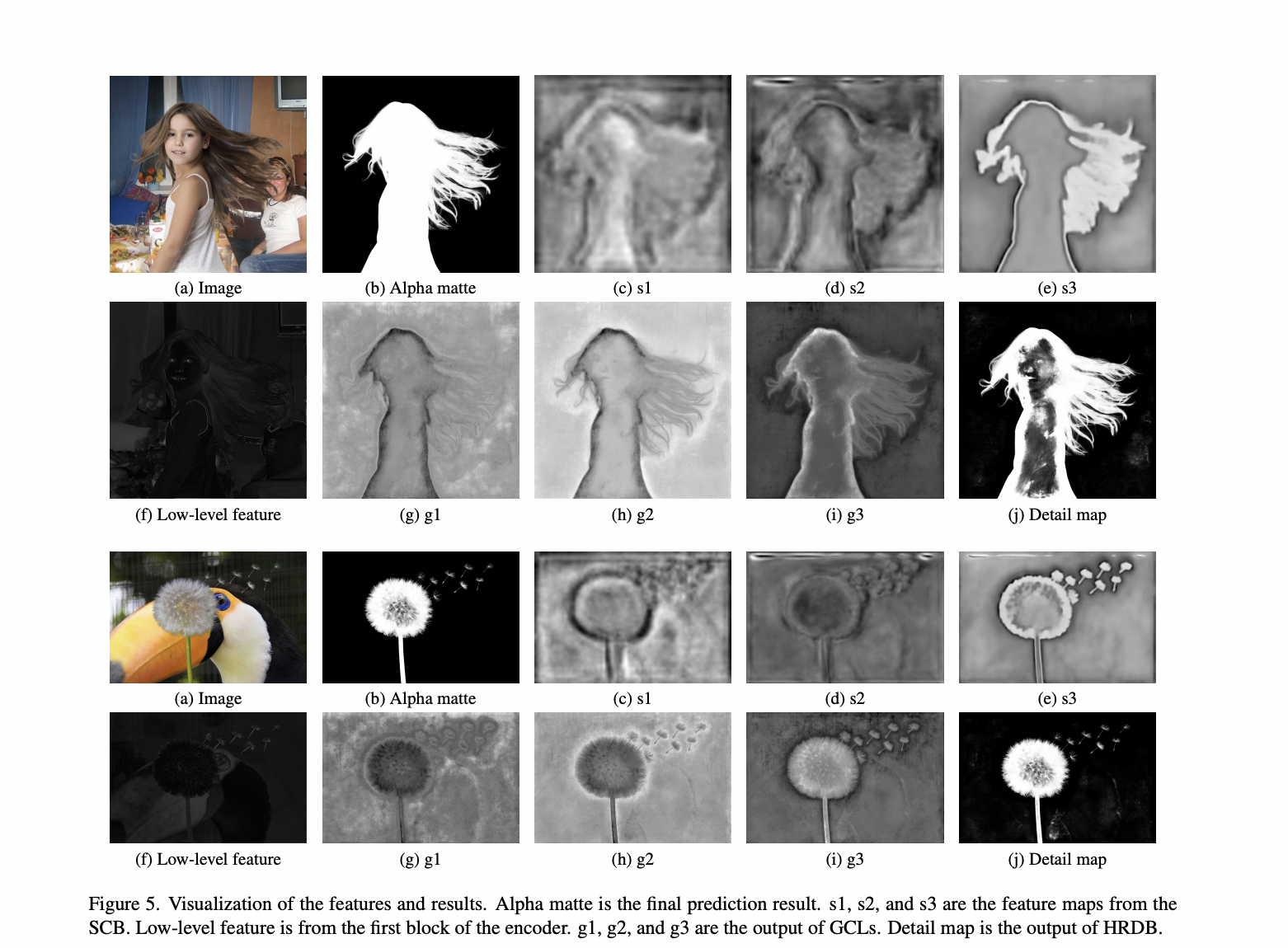
The team has used a high-resolution detail branch (HRDB) to get fine-grained foreground details in this strategy. Rather than using a downsample-upsample encoder-decoder structure, it maintains high resolution while extracting features at multiple levels.
According to researchers, the detail prediction is prone to foreground-background ambiguity due to a lack of semantics. Their semantic context branch (SCB) uses the segmentation subtask to ensure that details are semantically correct. The final alpha matte is created by merging the HRDB detail prediction with the SCB semantic map.
The researchers tested their method on datasets Composition-1k and Distinctions-646. Their findings demonstrate that PP-Matting outperforms previous methods and shows exceptional performance in real-world situations in human mating experiments.
Paper: https://arxiv.org/pdf/2204.09433.pdf
Github: https://github.com/PaddlePaddle/PaddleSeg
Credit: Source link
Comments are closed.