Beyond Photoshop: How Inst-Inpaint is Shaking Up Object Removal with Diffusion Models

Image inpainting is an ancient art. It is the process of removing unwanted objects and filling missing pixels in an image so that the completed image is realistic-looking and follows the original context. The applications of image inpainting are diverse, including tasks like enhancing aesthetics or privacy by eliminating undesired objects from images, improving the quality and clarity of old or damaged photos, completing missing information by filling gaps or holes in images, and expressing creativity or mood through the generation of artistic effects.

Inst-Inpaint or instructional image inpaint has been introduced, a method that takes an image and a textual instruction as input to remove the unwanted object as mentioned automatically. The image above shows us the input and output in the sample results with Inst-Inpaint. Here, this is done using state-of-the-art diffusion models. Diffusion Models are a class of probabilistic generative models that turn noise into a representative data sample and have been widely used in computer vision to obtain high-quality images in generative AI.
- Researchers first built the GQA-Inpaint, a real-world picture dataset, to train and test models for the proposed instructional image inpainting job. To create input/output pairs, they utilized the images and their scene graphs in the GQA dataset. This proposed method is undertaken in the following steps:
- Selecting an object of interest (object to be removed).
- Performing instance segmentation to locate the object in the image.
- Then, apply a state-of-the-art image inpainting method to erase the object.
- Finally, create a template-based textual prompt to describe the removal operation. As a result, the GQA-Inpaint dataset includes 147165 unique images and 41407 different instructions. Trained on this dataset, the Inst-Inpaint model is a text-based image inpainting method based on a conditioned Latent Diffusion Model, which does not require any user-specified binary mask and performs object removal in a single step without predicting a mask.
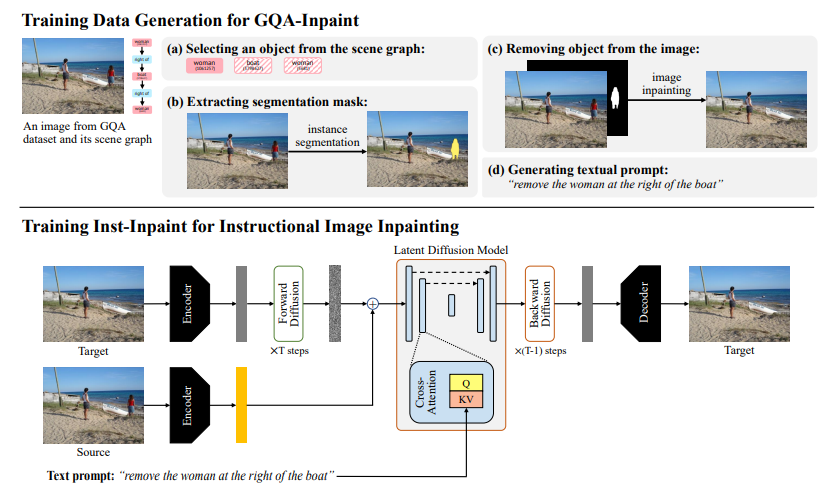
One detail to note is that the image is divided into three equal sections along the x-axis and named “left”, “center”, and “right,” following the natural naming and ‘location’ such as “on the table” is used to identify objects in the image. To compare the outcomes of experiments, researchers used numerous measures, including a novel CLIP-based inpainting score, to evaluate the GAN and diffusion-based baselines and prove significant quantitative and qualitative improvements.
In a rapidly evolving digital landscape, where the boundaries between human creativity and artificial intelligence are constantly blurring, Inst-Inpaint is a testament to AI’s transformative power in image manipulation. It has opened up numerous avenues for using textual instructions to image inpainting and once again brings AI closer to the human brain.
Check out the Paper, Project, and GitHub. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Credit: Source link
Comments are closed.