BitNet b1.58: Pioneering the Future of Efficient Large Language Models

The surge in the development of Large Language Models (LLMs) has been revolutionary. These sophisticated models have dramatically enhanced our ability to process, understand, and generate human-like text. Yet, as these models grow in size and complexity, they bring forth significant challenges, notably in computational and environmental costs. The pursuit of efficiency without sacrificing performance has become a paramount concern within the AI community.
The core issue is the immense demand for computational resources inherent in traditional LLMs. Their training and operational phases require substantial power and memory, leading to high costs and a notable environmental footprint. This scenario has spurred research into alternative architectures that promise comparable effectiveness with a fraction of the resource usage.
Earlier efforts to curb the resource intensity of LLMs have revolved around post-training quantization methods. These techniques aim to reduce the precision of the weights within a model, thereby lessening the computational load. While these methods have found their place within industrial applications, they often represent a compromise, balancing efficiency against model performance.
BitNet b1.58, developed by a collaborative research team from Microsoft Research and the University of Chinese Academy of Sciences, BitNet b1.58 employs a novel approach utilizing 1-bit ternary parameters for every model weight. This shift from traditional 16-bit floating values to a 1.58-bit representation is revolutionary, striking an optimal balance between efficiency and performance.
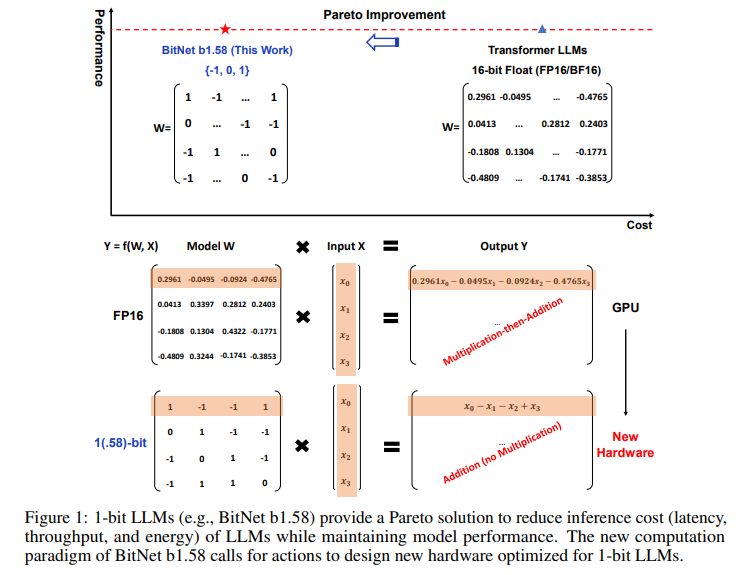
The methodology behind BitNet b1.58, by adopting ternary {-1, 0, 1} parameters, the model significantly reduces its demand on computational resources. This approach involves intricate quantization functions and optimizations that enable the model to maintain high-performance levels comparable to those of full-precision LLMs while achieving remarkable reductions in latency, memory usage, throughput, and energy consumption.
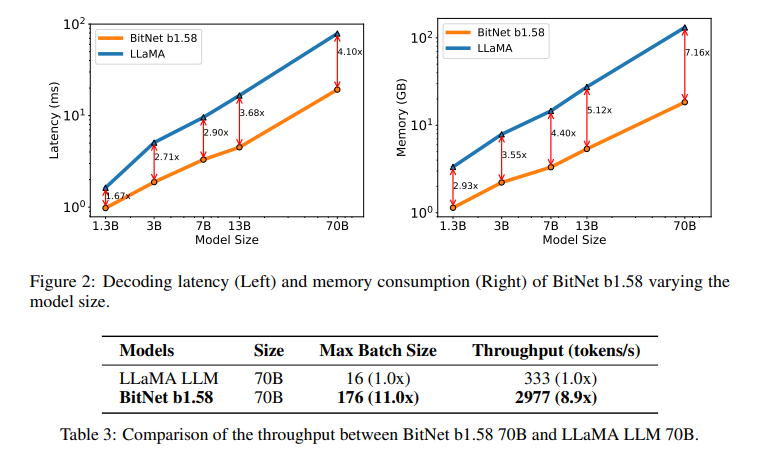
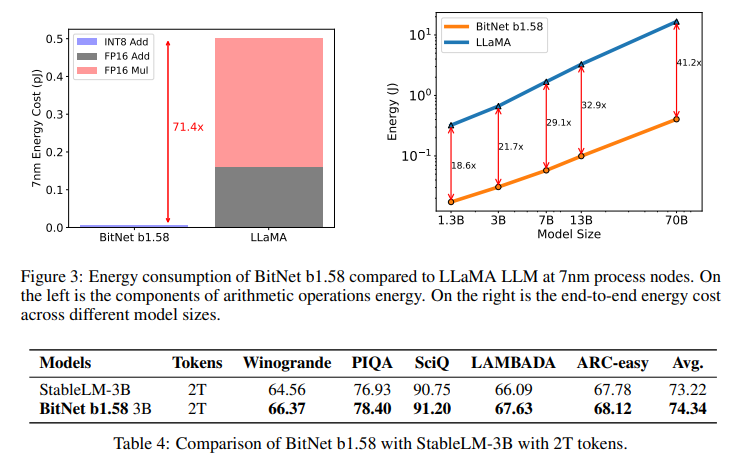
The performance of BitNet b1.58 demonstrates that it is possible to achieve high efficiency without compromising the quality of outcomes. Comparative studies have shown that BitNet b1.58 matches and occasionally exceeds conventional LLMs’ performance across various tasks. This is achieved with significantly faster processing speeds and lower resource consumption, showcasing the model’s potential to redefine the landscape of LLM development.
In conclusion, the research can be presented in a nutshell in the following points:
- The introduction of BitNet b1.58 tackles the pressing challenge of computational efficiency in LLMs, offering a novel solution that does not compromise performance.
- By utilizing 1-bit ternary parameters, BitNet b1.58 drastically reduces the resource requirements of LLMs, marking a leap forward in sustainable AI development.
- Comparative analyses affirm that BitNet b1.58 matches or surpasses traditional LLM performance, validating its effectiveness and efficiency.
- This research addresses a critical bottleneck in AI scalability and paves the way for future innovations, potentially transforming the application and accessibility of LLMs across various sectors.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.