Blazing a Trail in Interleaved Vision-and-Language Generation: Unveiling the Power of Generative Vokens with MiniGPT-5
Large language models excel at understanding and generating human language. This ability is crucial for tasks such as text summarization, sentiment analysis, translation, and chatbots, making them valuable tools for natural language processing. These models can improve machine translation systems, enabling more accurate and context-aware translations between different languages, with numerous global communication and business applications.
LLMs are proficient at recognizing and categorizing named entities in text, such as names of people, places, organizations, dates, and more. They can answer questions based on the information presented in a passage or document. They understand the context of the question and extract relevant information to provide accurate answers. However, the current LLMs are based on processing text image pairs. They need help when the task is to generate new images. The emerging vision and language tasks depend highly on topic-centric data and often skimps through image descriptors.
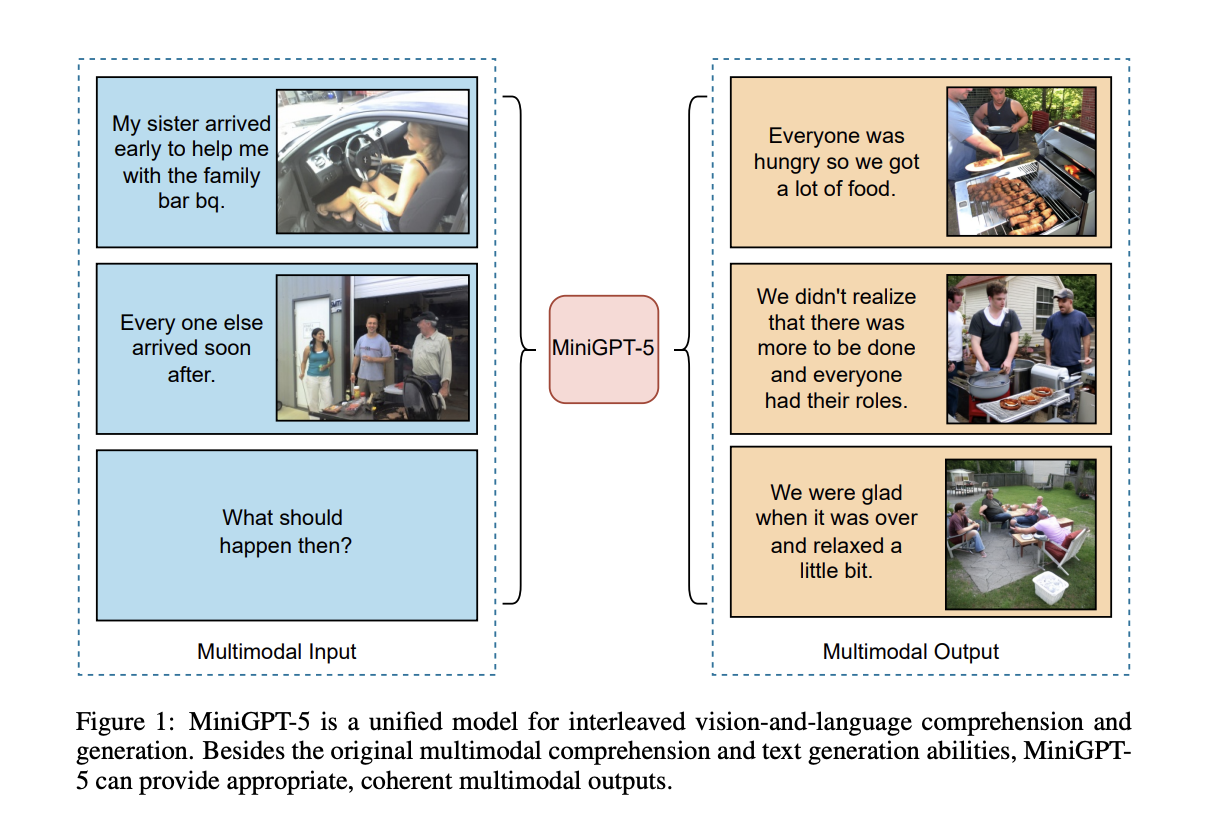
Researchers at the University of California built a new model named MiniGPT-5, which involves vision and language generation techniques based on generative vokens. This multimodal encoder is a novel technique proven effective compared to other LLMs. It combines the generative vokens with stable diffusion models to generate vision and language outputs.
The term generative vokens are the special visual tokens that can directly train on raw images. Visible tokens refer to elements added to the model’s input to incorporate visual information or enable multimodal understanding. When generating image captions, a model may take an image as input, tokenize the image into a series of special visual tokens, and combine them with textual tokens representing the context or description of the image. This integration allows the model to generate meaningful and contextually relevant captions for the images.
The researchers follow a two-stage method in which the first stage is unimodal alignment of the high-quality text-aligned visual features from large text-image pairs, and the second stage involves ensuring the visual and text prompts are well coordinated in the generation. Their method of generic stages enables one to eliminate domain-specific annotations and makes the solution from the existing works. They followed the dual-loss strategy to balance the text and the images. Their adapted method also optimizes the training efficiency and addresses memory constraints, which can be solved easily.
The team implemented Parameter-efficient fine-tuning over the MiniGPT-4 encoder to train the model better to understand instructions or prompts and enhance its performance in novel or zero-shot tasks. They also tried prefix tuning and LoRA over the language encoder Vicuna used in MiniGPT-4. Future work on these methods will broaden the applications, which seemed challenging previously due to the disjointed nature of existing image and text models.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.