Borealis AI Research Introduces fAux: A New Approach To Test Individual Fairness via Gradient Alignment
Machine learning models are trained on massive datasets with hundreds of thousands, if not billions, of parameters. However, how these models translate the input parameters into results is unknown. Having said that, the decision-making behavior of the model is difficult to comprehend. Furthermore, models are frequently skewed towards specific parameters due to faulty assumptions made during the machine learning process, which are difficult to detect.
Researchers from Borealis AI introduced fAux, a new approach to testing fairness.
They state that one approach to assessing fairness at the global level is to look at it from afar. By aggregating results across a complete population, the goal is to statistically quantify disparate treatment. The distribution of good and negative outcomes is then tested using fairness criteria. These are simple to build and can be computed without having access to the original model — because one only needs the model’s predictions. Moreover, historical data can even be tested.
However, they are confined to previously seen data points and cannot identify whether or not unique persons should be handled in the same way.
Another approach is testing the fairness individually. It is based on the idea that similar people should be handled in the same way. The team states that the models should be “blind” to the protected variable in one of two ways: either it is insensitive to perturbations or simply not included in the dataset. However, this definition misses several discriminatory mechanisms.
To determine which versions are valid and sensitive, the researchers used Counterfactual Fairness (CFF) to look for unequal treatment within a fair “subspace.” Later they utilized supervised learning to fit an auxiliary model to a target model and a dataset. Then an alignment score was computed using the gradients of both the target and auxiliary models. The target model’s choice was labeled as unfair if the score exceeded a user-specified threshold.
To measure the reliability of the discrimination tests, they create synthetic datasets that allow them to manipulate the amount of discrimination. The test is reliable if it produces a high score when discrimination is high and a low score when discrimination is low.
The researchers create two different datasets for which generative models can be built. One of these datasets is a “harder” learning task than the other in certain ways. These datasets’ inputs can be joined using a function to create the inputs for a “fused” dataset. Their findings show that any models trained on this dataset learn to exploit the bias.
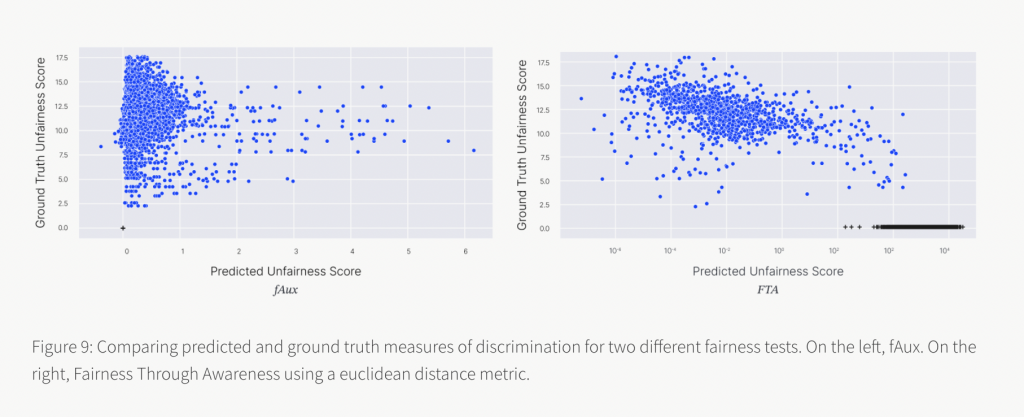
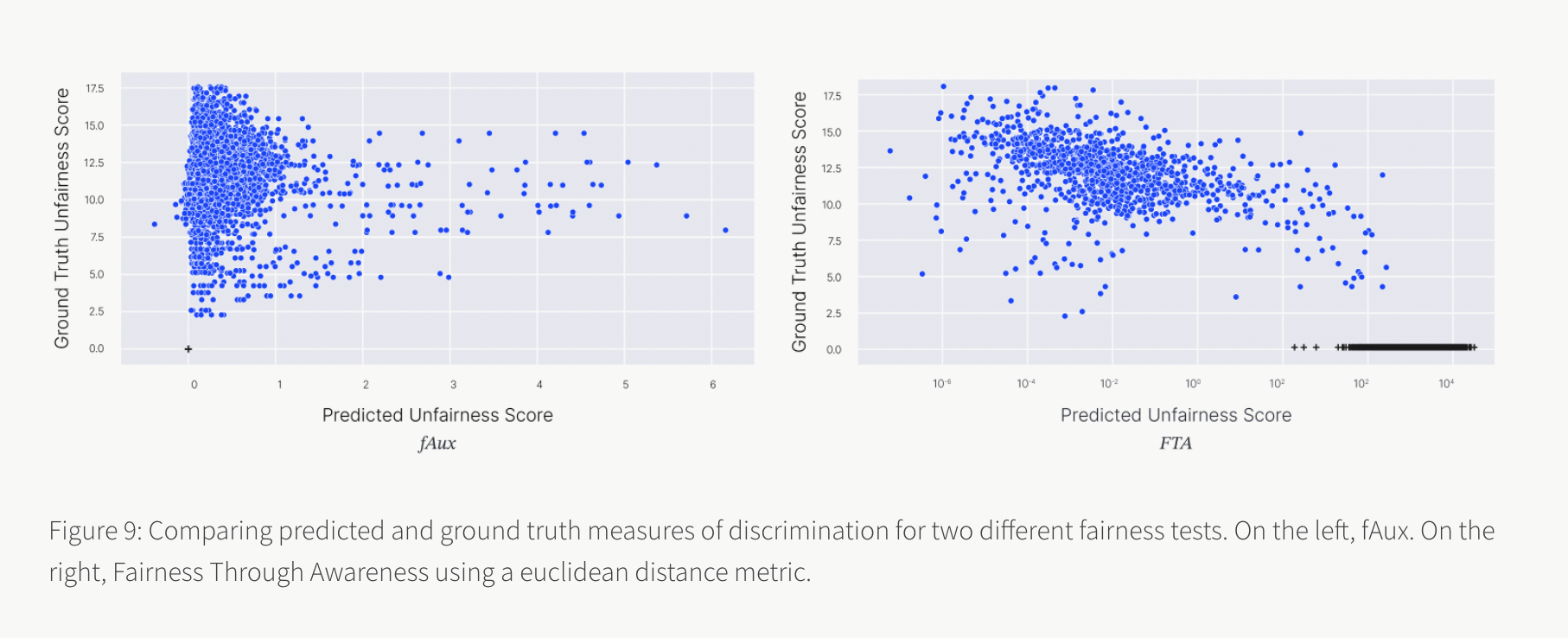
Having access to the generative model, according to academics, is extremely beneficial since it enables the creation of models that are fair in construction. It also includes a ground truth fairness score that may be used to compare the accuracy of various fairness tests.
The researchers compared the projected unfairness score from two tests to the ground truth unfairness score. The findings reveal that both tests can recognize that unjust outcomes are unfair, yet, FTA also gives fair decisions high unfairness scores. It turns out that models with big gradients, as opposed to models that discriminate, are particularly susceptible to this test. fAux, on the other hand, is only sensitive to changes in the protected attribute: all fair forecasts have a discrimination score of 0.
They begin by thresholding the ground truth score to get a binary label for discrimination to quantify a specific fairness test’s trustworthiness. The anticipated unfairness score might then be thresholded, and the binary accuracy calculated. The researchers explain that choosing such a threshold is a delicate matter. In general, numerous thresholds are used in the selection process, requiring more domain-specific research. Instead, the researchers look at the precision-recall (PR) curve to see how accurate each test is across different thresholds. Larger areas under the PR curve will indicate more trustworthy tests.
They compare fAux’s average precision results to those of other individual fairness tests found in the literature. They discovered that fAux outperforms.
Ground truth labels for discrimination are not available for real datasets. As a result, quantifying the precision of a fairness test at the level of individual data points is impossible. The researchers examine the following factors to assess fAux’s performance:
- How does their test compare to other fairness definitions?
- Is it possible to tell the difference between fair and unfair models?
- Is it possible to provide insight into the discrimination mechanism given an unfair model?
It may be possible to control the dataset’s bias any longer, but the researchers state that they could still control the models they test. They believe that models produced by training methods with higher regularisation for fairness will be fairer. To do this, they employ adversarial training to develop fair models with increasing regularisation. They also demonstrate that fAux has the advantage of explaining discriminatory predictions. Finally, they show that deleting ambiguous features from the dataset causes the model to predict correctly.
This Article Is Based On The Research Article 'fAux: Testing Individual Fairness via Gradient Alignment'. All Credit For This Research Goes To The Researchers of This Project. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.