Bridging Modalities with VisionLLaMA: A Unified Architecture for Vision Tasks
Large language models, predominantly based on transformer architectures, have reshaped natural language processing. The LLaMA family of models has emerged as a prominent example. However, a fundamental question arises: can the same transformer architecture be effectively applied to process 2D images? This paper introduces VisionLLaMA, a vision transformer tailored to bridge the gap between language and vision modalities. In this article, we explore the key aspects of VisionLLaMA, from its architecture and design principles to its performance in various vision tasks.
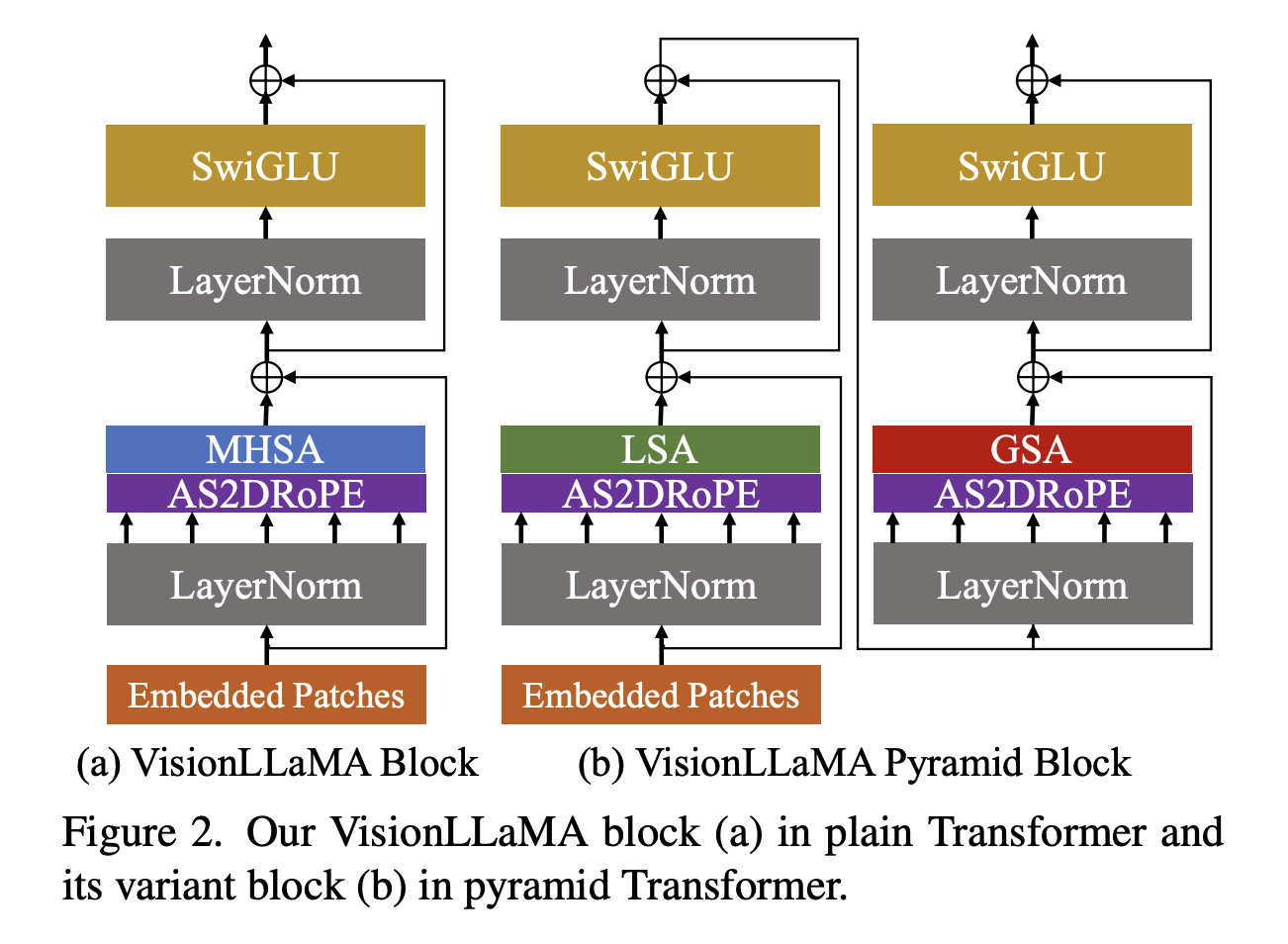
VisionLLaMA closely follows the pipeline of Vision Transformer (ViT) while retaining the architectural design of LLaMA. The image is segmented into non-overlapping patches and processed through VisionLLaMA blocks, which include features such as self-attention via Rotary Positional Encodings (RoPE) and SwiGLU activation. Notably, VisionLLaMA varies from ViT by relying solely on the inherent positional encoding of its basic block.
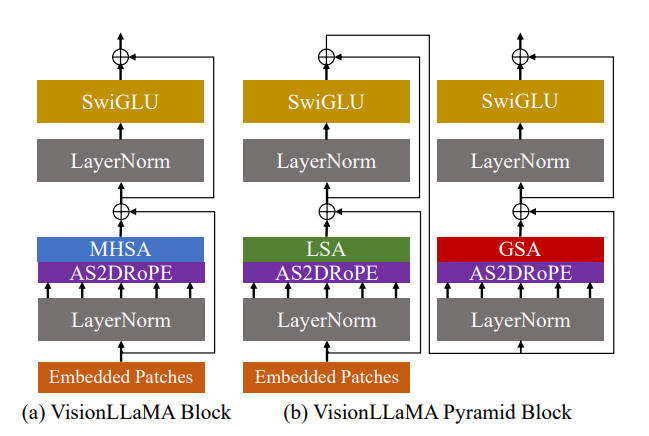
The paper focuses on two versions of VisionLLaMA: plain and pyramid transformers. The plain variant is consistent with the ViT architecture, whereas the pyramid variant investigates extending VisionLLaMA to window-based transformers (Twins). The purpose is not to construct new pyramid transformers but rather to show how VisionLLaMA adapts to existing designs, exhibiting adaptability across architectures.
Numerous experiments assess VisionLLaMA’s performance in image generation, classification, segmentation, and detection. VisionLLaMA has been incorporated into the DiT diffusion framework for image generation and the SiT generative model framework to evaluate its merits in model architecture. Results show that VisionLLaMA consistently outperforms across model sizes, validating its efficiency as a vision backbone. VisionLLaMA’s design choices, such as using SwiGLU, normalization techniques, positional encoding ratios, and feature abstraction methods, are investigated in ablation studies. The study offers insights into the dependability and efficiency of VisionLLaMA’s constituent parts, directing decisions about its implementation.
The experiments can be summarized as:
- Image Generation on DiT and SiT Diffusion Frameworks
- Classification on ImageNet-1K Dataset
- Semantic Segmentation on ADE20K Dataset
- Object Detection on COCO
The performances of supervised and self-supervised training were compared, and the models were fine-tuned accordingly.
Additional analysis of the underlying mechanisms enabling VisionLLaMA’s improved performance can be found in the discussion section. The model’s positional encoding technique and insights into how it affects convergence speed and overall performance are highlighted. The flexibility provided by RoPE is highlighted as an essential factor in efficiently leveraging model capacity.
The paper proposes VisionLLaMA as an appealing architecture for vision tasks, laying the groundwork for further investigations. The exploration of its capabilities in various applications suggests further possibilities, like expanding the capabilities of VisionLLaMA beyond text and vision to create a more inclusive and adaptable model architecture.
In conclusion, VisionLLaMA provides a seamless architecture that cuts across modalities, bridging the link between language and vision. Together, its theoretical justification, experimental validation, and design choices highlight VisionLLaMA’s ability to significantly impact the field of vision tasks. The open-source release promotes cooperative research and creativity in the field of large vision transformers a lot further.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Vibhanshu Patidar is a consulting intern at MarktechPost. Currently pursuing B.S. at Indian Institute of Technology (IIT) Kanpur. He is a Robotics and Machine Learning enthusiast with a knack for unraveling the complexities of algorithms that bridge theory and practical applications.
Credit: Source link
Comments are closed.