Brown University Researchers Propose LexC-Gen: A New Artificial Intelligence Method that Generates Low-Resource-Language Classification Task Data at Scale
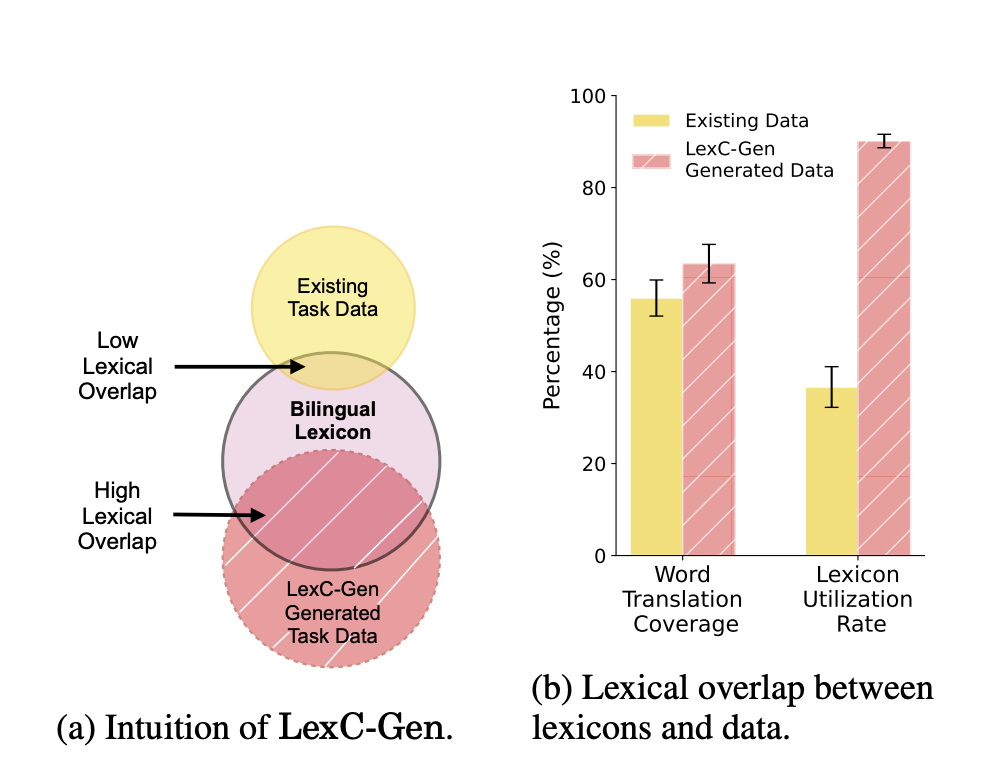
Data scarcity in low-resource languages can be mitigated using word-to-word translations from high-resource languages. However, bilingual lexicons typically need more overlap with task data, leading to inadequate translation coverage. Extremely low-resource languages need more labeled data, widening the gap in NLP progress compared to high-resource languages.
Lexicon-based cross-lingual data augmentation involves swapping words in high-resource language data with their translations from bilingual lexicons to generate data for low-resource languages. While effective for various NLP tasks, including machine translation, sentiment classification, and topic classification, existing methods often rely on domain-specific lexicons and need more gold training data quality in target low-resource languages. This approach faces challenges with domain specificity and performance compared to native data. Additionally, lexicon coverage and translation model limitations hinder broader application across languages.
Researchers from the Department of Computer Science and Data Science Institute at Brown University have proposed LexC-Gen, a method for scalable generation of low-resource-language classification task data. It leverages bilingual lexicons first to create lexicon-compatible task data in high-resource languages, then translates them into low-resource languages through word translation. Conditioning on bilingual lexicons is identified as a crucial aspect of its effectiveness. LexC-Gen demonstrates practicality, requiring only a single GPU for scalable data generation and compatibility with open-access LLMs.
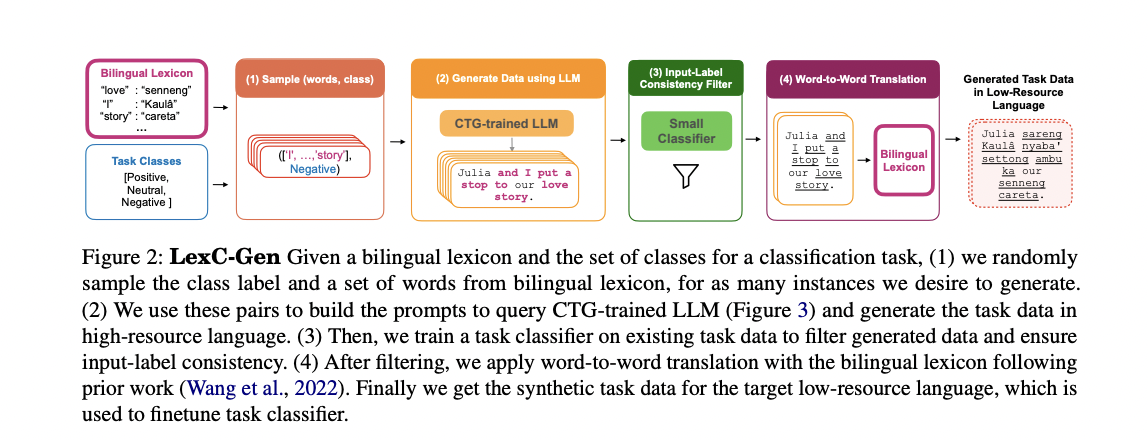
LexC-Gen employs a multi-step process to generate labeled task data for low-resource languages. It utilizes high-resource-language data, a bilingual lexicon, and a language model supporting the high-resource language. Firstly, it samples high-resource-language words and class labels, then generates lexicon-compatible task data using a Controlled-Text Generation (CTG)-trained LLM. After applying an input-label consistency filter, it translates the data into the low-resource language using word-to-word translation via the bilingual lexicon. This approach ensures scalability, data quality, and effective translation, facilitating classifier finetuning for low-resource language tasks.
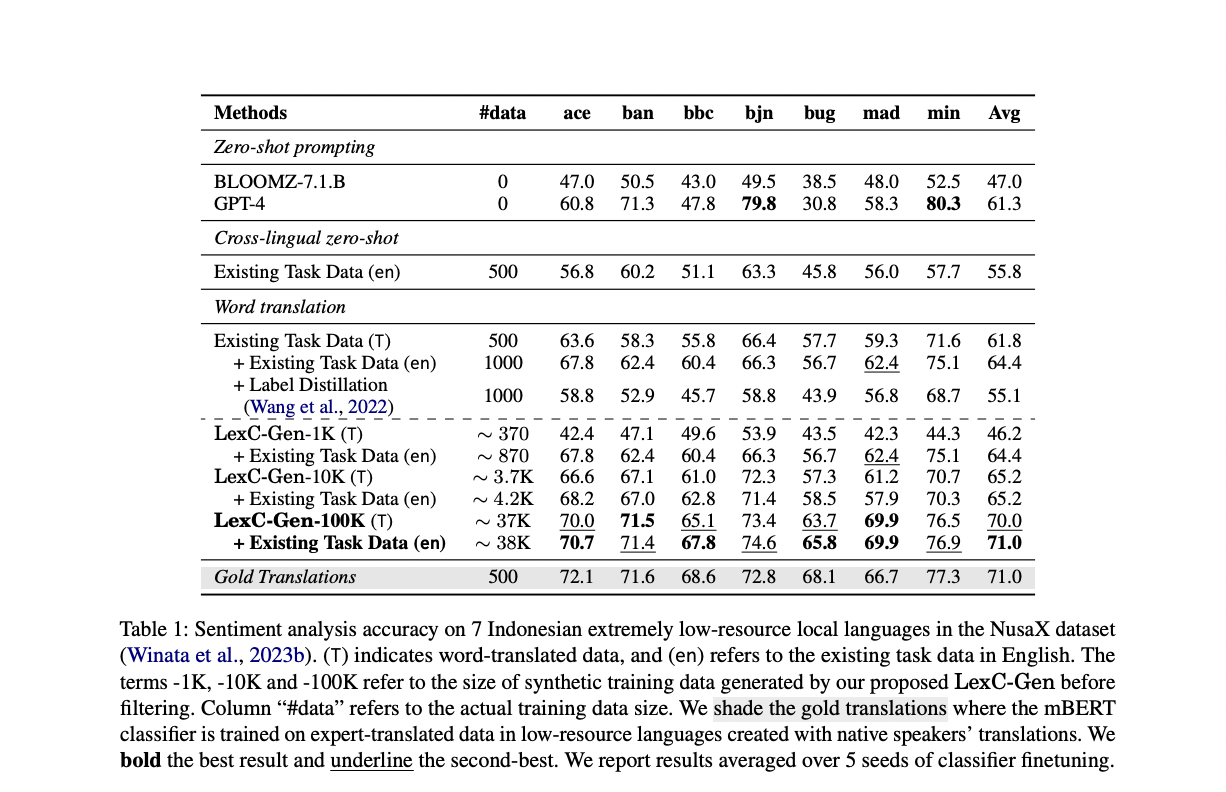
In comparing LexC-Gen against baselines and gold translations on sentiment analysis and topic classification tasks, it outperforms all baselines in both the sentiment analysis and topic classification tasks. In sentiment analysis and topic classification tasks across 17 low-resource languages, LexC-Gen demonstrates superiority over all baselines. For sentiment analysis, combining LexC-Gen-100K with existing English data boosts performance by 15.2 points over cross-lingual zero-shot and 6.6 points over word translation baselines. In topic classification, LexC-Gen-100K surpasses cross-lingual zero-shot and word translation baselines by 18.3 and 8.9 points, respectively.
To conclude, researchers from Brown University present LexC-Gen, a solution for generating task data in low-resource languages by leveraging LLMs to create lexicon-compatible data, enhancing translation with bilingual lexicons. Through finetuning on this generated data, LexC-Gen achieves performance comparable to difficult-to-obtain gold data in sentiment analysis and topic classification tasks. Its practicality offers promise in mitigating data scarcity in low-resource languages, potentially accelerating progress in NLP for these underserved linguistic communities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Credit: Source link
Comments are closed.