BurstAttention: A Groundbreaking Machine Learning Framework that Transforms Efficiency in Large Language Models with Advanced Distributed Attention Mechanism for Extremely Long Sequences
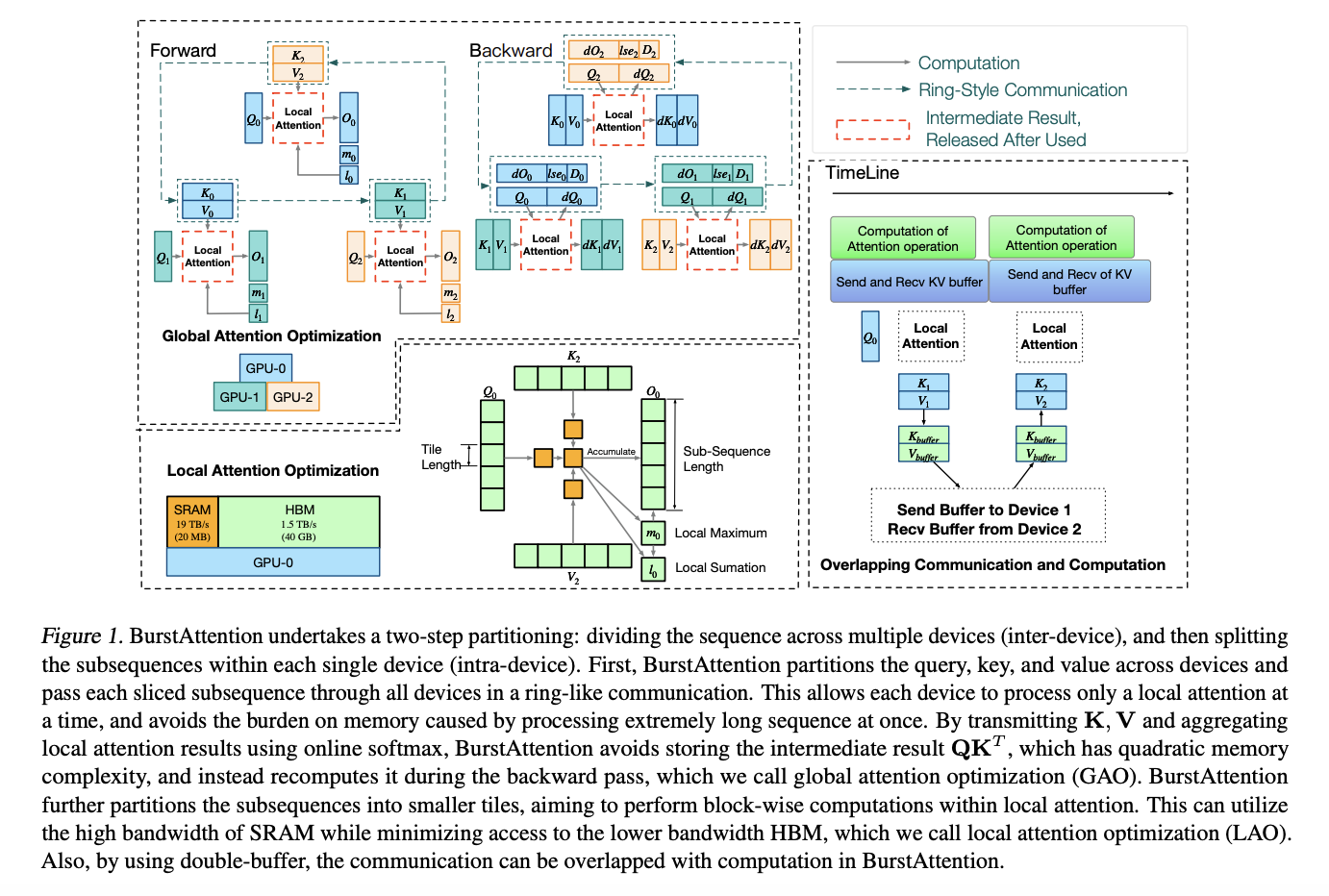
Large language models (LLMs) have revolutionized how computers understand and generate human language in machine learning and natural language processing. Central to this revolution is the Transformer architecture, known for its remarkable ability to handle complex textual data. We must overcome significant challenges as we explore the full potential of these models, particularly in processing exceptionally lengthy sequences. Despite their effectiveness, traditional attention mechanisms suffer from a quadratic increase in computational and memory costs concerning sequence length, making the processing of long sequences inefficient and resource-intensive.
Addressing this crucial bottleneck, the novel framework BurstAttention emerges from a powerful collaborative effort, a testament to the significance of collective intelligence. Researchers from Beijing, Tsinghua University, and Huawei are pooling their expertise to enhance long-sequence processing efficiency. This optimization is not a simple task; it involves a sophisticated partitioning strategy that divides the computational workload of attention mechanisms across multiple devices, such as GPUs, effectively parallelizing the task while minimizing memory overhead and communication costs.
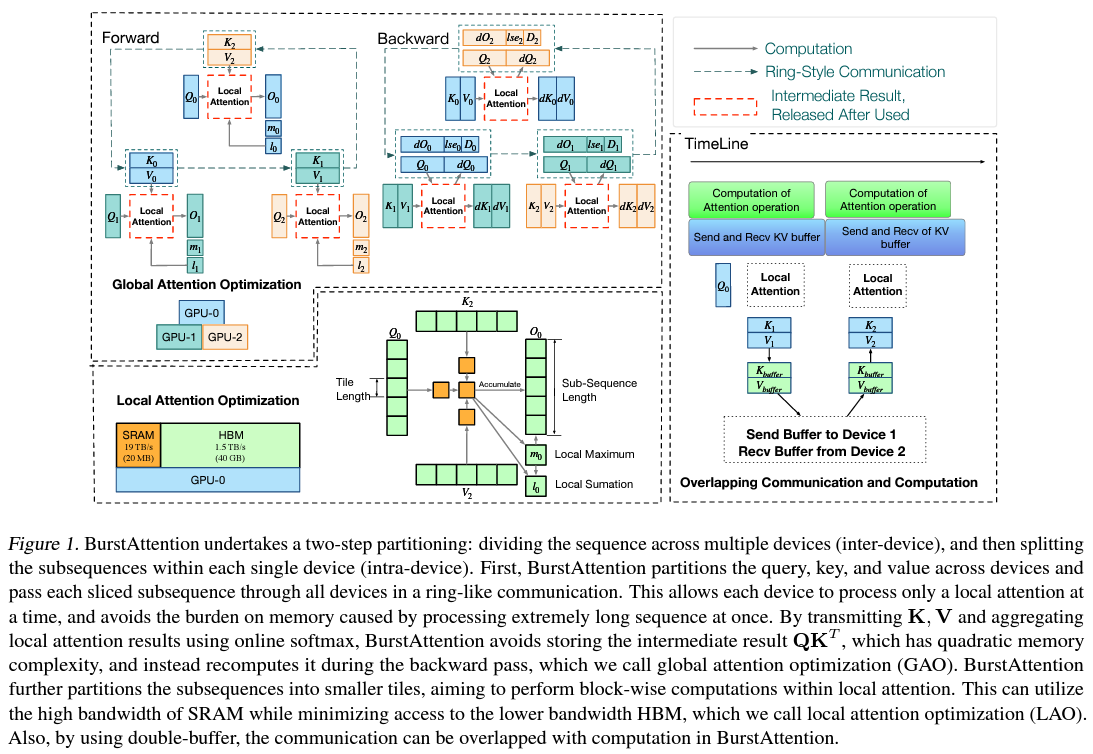
BurstAttention uses a dual-level optimization approach to enhance global and local computational processes. On a worldwide scale, the framework smartly distributes the computational load across the devices in a distributed cluster, reducing the overall memory footprint and curtailing unnecessary communication overhead. Locally, BurstAttention refines the computation of attention scores within each device, employing strategies that leverage the device’s memory hierarchy to accelerate processing speeds while further conserving memory. This ingenious combination of global and local optimizations allows the framework to process sequences of unprecedented length with remarkable efficiency.
Empirical validation of BurstAttention underscores its undeniable superiority over existing distributed attention solutions, including tensor parallelism and the RingAttention method. In rigorous testing environments, specifically on setups equipped with 8x A100 GPUs, BurstAttention demonstrated a remarkable reduction in communication overhead by 40% and doubled training speed. These performance metrics become even more pronounced with sequences extending to 128,000 (128K), showcasing BurstAttention’s unparalleled capability in handling long sequences, a critical advantage for developing and applying next-generation LLMs.
Moreover, BurstAttention’s scalability and efficiency are not achieved at the expense of model performance. Rigorous evaluations, including perplexity measurements on the LLaMA-7b model using a dataset from C4, reveal that BurstAttention maintains model performance fidelity, with perplexity scores on par with those obtained using traditional distributed attention methods. This delicate balance between efficiency and performance integrity is a testament to the robustness of BurstAttention, making it a pivotal development in the realm of NLP and offering a scalable and efficient solution to one of the most pressing challenges in the field.
BurstAttention is a significant advancement in processing long sequences in large language models; it’s a game-changer for NLP. This new approach to NLP sets a standard for addressing computational efficiency and memory constraints, paving the way for future innovations. The collaboration between academia and industry underscores the importance of cross-sector partnerships in advancing technology and machine learning. Frameworks such as BurstAttention will not just have a significant role in unlocking the full potential of large language models but will also provide new opportunities for exploration in AI.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.