Cambridge AI Researchers Propose ‘MAGIC’: A Training-Free Framework That Plugs Visual Controls Into The Generation Of A Language Model

This Article Is Based On The Research Paper 'Language Models Can See: Plugging Visual Controls in Text Generation'. All Credit For This Research Goes To The Researchers 👏👏👏 Please Don't Forget To Join Our ML Subreddit
The release of Generative Pretrained Transformer (GPT-2) has fetched huge attention towards generative language models (LMs), which are pre-trained on massive amounts of unstructured text and have generated efficient results on a variety of NLP applications. LMs can produce texts constantly utilizing a textual prompt’s next-token prediction decoding approach. Models such as CLIP and ALIGN, pre-trained image-text joint embedding approaches, have revived multimodal illustration learning of text and images. Accordingly, it is challenging to integrate the benefits of pre-trained LMs and image-text embedding models to generate visually grounded text. The traditional approaches are generally limited by the object detectors trained with a fixed set of labels. Currently, the ZeroCap approach is utilized for image captioning, which is an unsupervised technique that integrates frozen CLIP and GPT-2. ZeroCap uses gradient update and optimization over the context cache. This approach slows down inference and makes it challenging to utilize in real-world scenarios. This research resolves this challenge by proposing a novel method called iMAge-Guided text generatIon with CLIP (MAGIC) for text decoding. MAGIC uses explicit “control knobs” to choose desired outputs, following the direction of both the GPT-2 and CLIP models. Also, it does not require any additional parameters for training. The approach involves a new term called magic sore from boosting the predicted result for demonstrating information close to a given image. The simulation results depict that such a framework allows for zero-shot image captioning and visually grounded story creation using a simple plug-and-play method. This research tests two widely used benchmarks: MS-COCO and Flickr30k. The proposed approach outperforms all unsupervised and weakly supervised baselines, achieving state-of-the-art (SOTA) results across several evaluation measures. Also, the proposed method does not require a gradient update, and hence the inference speed is approximately 27 times faster than earlier zero-shot image captioning SOTA. This approach is also evaluated on visually grounded story generation. On both human and machine evaluations, the proposed method produces high-quality, efficient stories compared to robust baseline methods.

Figure 1 depicts visual comparisons of the proposed technique with two other zero-shot solid baselines and the reference caption. The outcome showcase that the proposed approach can produce related captions while also being more efficient at grounding on the supplied image.
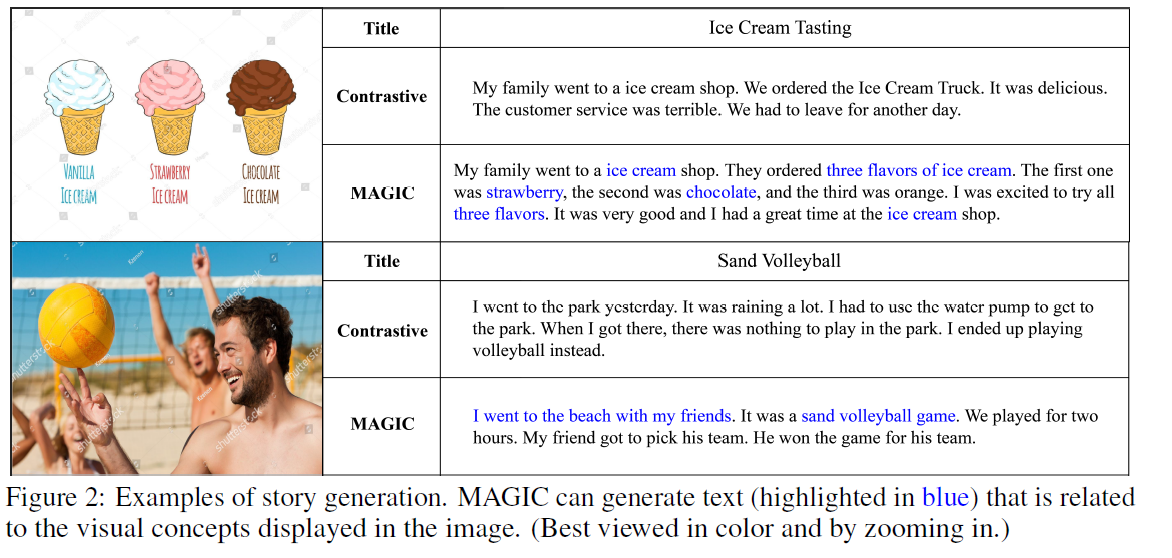
The proposed method contrasts with the most substantial baseline (contrastive search) in Figure 2, where the image retrieved by the story title is shown on the left. It can depict that the MAGIC framework creates text based on the image’s visual concepts.

This research proposes MAGIC Search, a new decoding methodology that seeks to lead the language model’s decoding process in the desired visual direction. This method adapts to the textual domain by first learning an unsupervised language model on the text corpus of the end task. It also presents the magic score, a new scoring criterion for visual controls in the decoding process. The GPT-2 is fine-tuned for three epochs on the training text corpus for each model. The proposed approach is compared with top-k sampling with k = 40, nucleus sampling with p = 0.95, a CLIP-based method called CLIPRe, and the state-of-the-art approach ZeroCap. Evaluation of the approaches is done using performance measures such as BLEU-1 ([email protected]), BLEU-4 ([email protected]), METER (M), ROUGE-L (R-L), CIDEr, and SPICE. In addition, the average inference time per image instance is used to calculate the decoding speed.
Conclusion:
The two primary tasks of this research are image captioning and visually grounded story generation. This work proposes a new decoding approach, MAGIC, that incorporates visual controls into the language model creation. It’s a framework that doesn’t require any training and allows the LM to tackle complex multimodal tasks without sacrificing decoding speed. The experimental results show that the proposed methodology surpasses earlier state-of-the-art systems in automatic and human evaluations. In the future, this generic architecture can be extended to modalities beyond text and image (i.e, audio and video).
Paper: https://arxiv.org/pdf/2205.02655v1.pdf
Github: https://github.com/yxuansu/magic
Credit: Source link
Comments are closed.