Can AI Really Tell if Your 3D Model is a Masterpiece or a Mess? This AI Paper Seems to have an Answer!
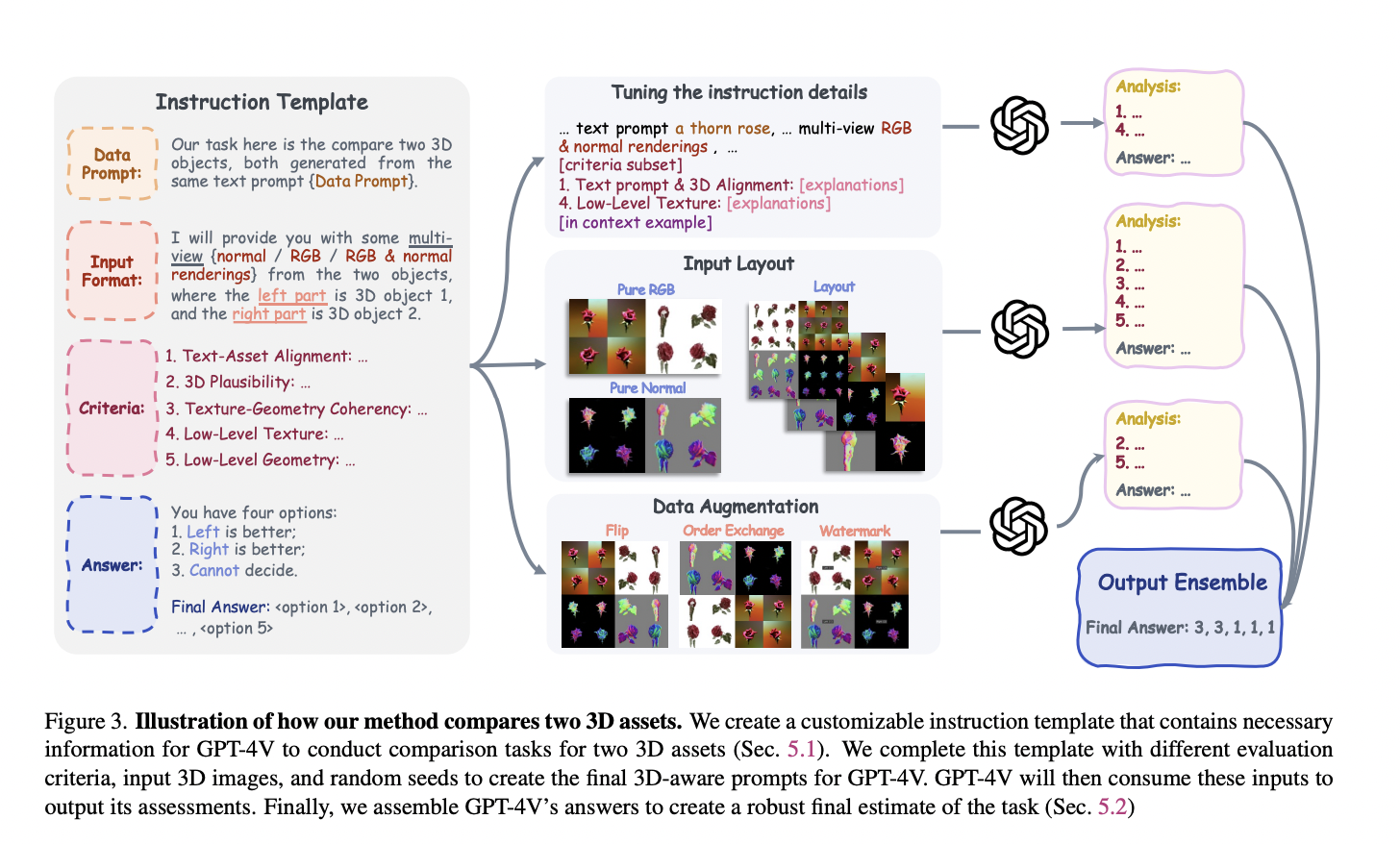
The rapidly evolving domain of text-to-3D generative methods, the challenge of creating reliable and comprehensive evaluation metrics is paramount. Previous approaches have relied on specific criteria, such as how well a generated 3D object aligns with its textual description. However, these methods often must improve versatility and alignment with human judgment. The need for a more adaptable and encompassing evaluation system is evident, especially in a field where the complexity and creativity of outputs are continually expanding.
An evaluation metric has been developed by a team of researchers from The Chinese University of Hong Kong, Stanford University, Adobe Research, S-Lab Nanyang Technological University, and Shanghai Artificial Intelligence Laboratory using GPT-4V to address this challenge, a variant of the Generative Pre-trained Transformer 4 (GPT-4) model. This metric introduces a two-fold approach:
- First, generate various input prompts that accurately reflect diverse evaluative needs.
- Second, by assessing 3D models against these prompts using GPT-4V.
This approach provides a multifaceted evaluation, considering various aspects such as text-asset alignment, 3D plausibility, and texture details, offering a more rounded assessment than previous methods.
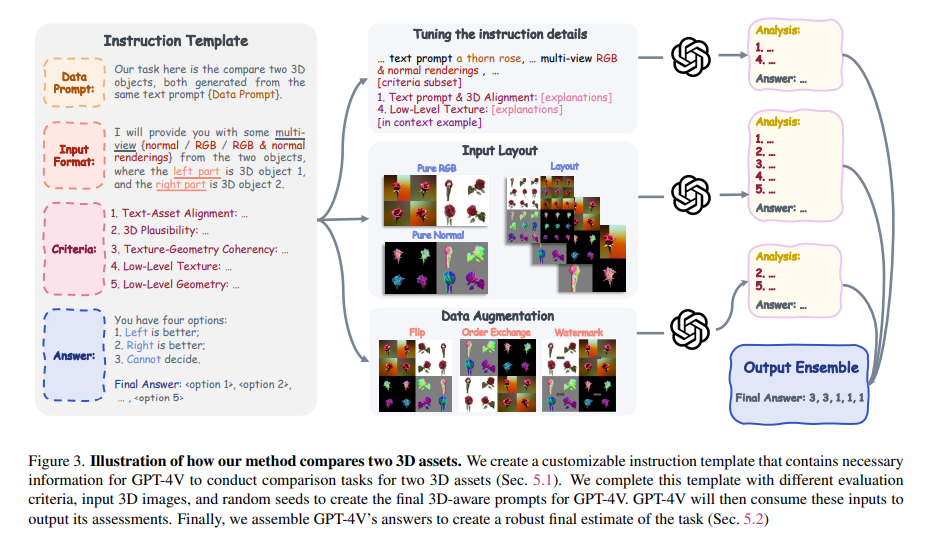
The core of this new methodology lies in its prompt generation and comparative analysis. The prompt generator, powered by GPT-4V, creates diverse evaluation prompts, ensuring a wide range of user demands are met. Following this, GPT-4V compares pairs of 3D shapes generated from these prompts. The comparison is based on various user-defined criteria, making the evaluation process flexible and thorough. This technique allows for a scalable and holistic way to evaluate text-to-3D models, surpassing the limitations of existing metrics.
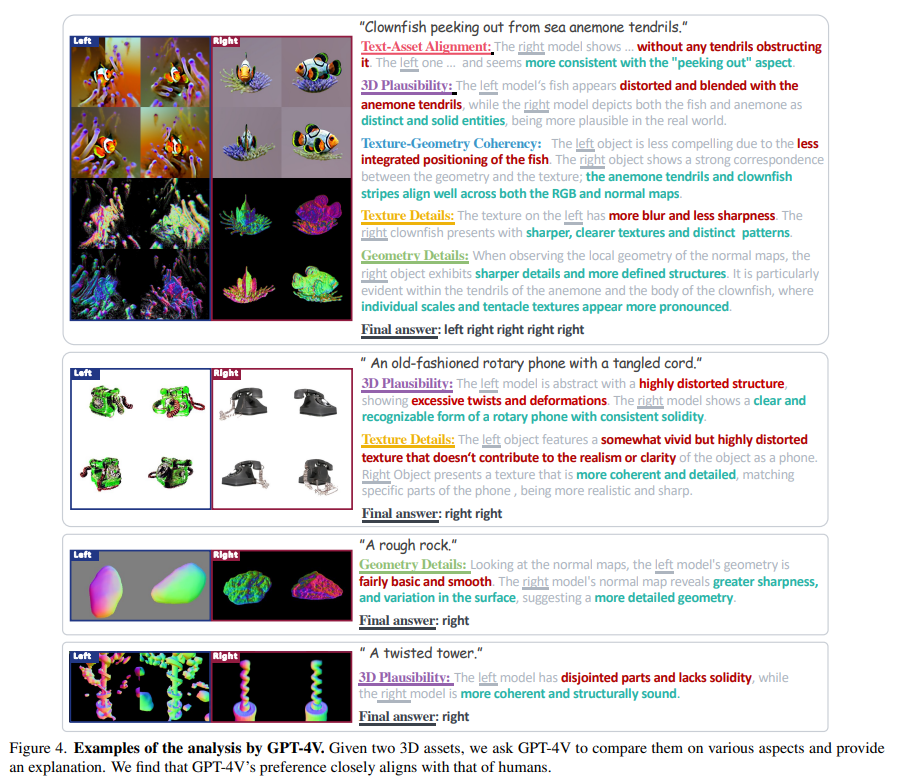
This new metric strongly aligns with human preferences across multiple evaluation criteria. It offers a comprehensive view of each model’s capabilities, particularly in texture sharpness and shape plausibility. The metric’s adaptability is evident as it performs consistently across different criteria, significantly improving over previous metrics that typically excelled in only one or two areas. This demonstrates the metric’s ability to provide a balanced and nuanced evaluation of text-to-3D generative models.
Key highlights of the research can be summarized in the following points:
- This research marks a significant advancement in evaluating text-to-3D generative models.
- A key development is introducing a versatile, human-aligned evaluation metric using GPT-4V.
- The new tool excels in multiple criteria, offering a comprehensive assessment that aligns closely with human judgment.
- This innovation paves the way for more accurate and efficient model assessments in text-to-3D generation.
- The approach sets a new standard in the field, guiding future advancements and research directions.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.