Can AI Truly Restore Facial Details from Low-Quality Images? Meet DAEFR: A Dual-Branch Framework for Enhanced Quality
In the field of image processing, recovering high-definition information from poor facial photographs is still a difficult task. Due to the numerous degradations these images go through, which frequently cause the loss of essential information, such activities are intrinsically hard. This problem highlights the difference in quality between low-quality and high-quality photographs. The question that follows is whether it is possible to use the inherent qualities of the low-quality domain to understand better and improve the process of facial repair.
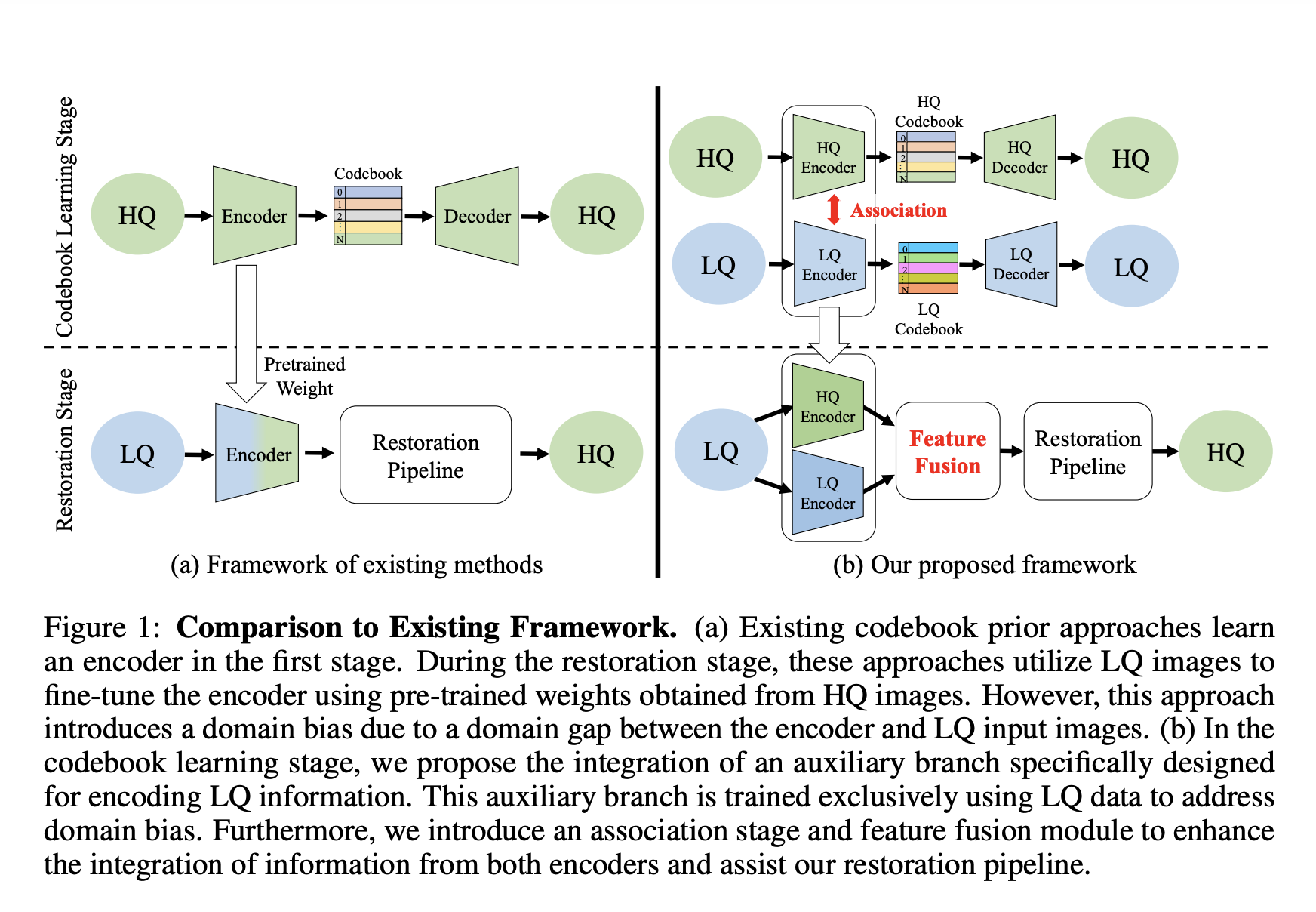
Recent approaches have incorporated codebook priors, autoencoders, and high-quality feature sets to address this issue. These methods continue to have a significant weakness, nevertheless. They generally rely on a single encoder trained exclusively on high-quality data, omitting the special complexities that low-quality images have. Although innovative, such a method may unintentionally widen the domain gap and miss the subtleties of low-quality data.
A new paper was recently introduced to tackle these issues, presenting a fresh solution. This approach uses an extra “low-quality” branch to pull important details from blurry or unclear images, combining them with clearer picture details to improve face image restoration.
Here’s what stands out about their work:
1. They added a special tool to capture the unique features of low-quality images, bridging the gap between clear and unclear images.
2. Their method mixes details from both low and high-quality images. This mix helps overcome common problems in image restoration, leading to clearer, better results.
3. They introduced a technique called DAEFR to handle blurry or unclear face images.
Concretely, their approach involves several key steps:
- Discrete Codebook Learning Stage: They establish codebooks for HQ and LQ images. Using vector quantization, they train an autoencoder for self-reconstruction to capture domain-specific information. This stage produces encoders and codebooks for both HQ and LQ domains.
- Association Stage: Drawing inspiration from the CLIP model, they associate features from the HQ and LQ domains. Features from domain-specific encoders are flattened into patches to construct a similarity matrix. This matrix measures the closeness of these patches in terms of spatial location and feature level. The goal is to minimize the domain gap and produce two associated encoders integrating information from both domains.
- Feature Fusion & Code Prediction Stage: The LQ image is encoded using both encoders after obtaining associated encoders. A multi-head cross-attention module merges features from these encoders, producing a fused feature encompassing information from both HQ and LQ domains. Subsequently, a transformer predicts the relevant code elements for the HQ codebook, which are then used by a decoder to generate the restored HQ images.
The authors evaluated their method through a series of experiments. They trained their model using the PyTorch framework on the FFHQ dataset of 70,000 high-quality face images. These images were resized and synthetically degraded for training purposes. For testing, they chose four datasets: CelebA-Test and three real-world datasets. Their evaluation metrics ranged from PSNR and SSIM for datasets with ground truth to FID and NIQE for real-world datasets without ground truth. Compared with state-of-the-art methods, their DAEFR model displayed superior perceptual quality on real-world datasets and competitive performance on synthetic datasets. Additionally, an ablation study revealed that using two encoders was optimal, and their proposed multi-head cross-attention module improved feature fusion, underscoring the method’s efficacy in restoring degraded images.
To conclude, we presented in this article a new paper that was published to address the challenges of image restoration, particularly for low-quality facial photographs. The researchers introduced a novel method, DAEFR, which harnesses both high and low-quality image features to produce clearer and more refined restorations. This approach uniquely uses a dual-encoder system, one each for high and low-quality images, bridging the existing gap between the two domains. The solution was evaluated rigorously, showing notable improvements over previous methods. The paper’s findings underscore the potential of DAEFR to significantly advance the field of image processing, paving the way for more accurate facial image restorations.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Mahmoud is a PhD researcher in machine learning. He also holds a
bachelor’s degree in physical science and a master’s degree in
telecommunications and networking systems. His current areas of
research concern computer vision, stock market prediction and deep
learning. He produced several scientific articles about person re-
identification and the study of the robustness and stability of deep
networks.
Credit: Source link
Comments are closed.