Can Autoformalization Bridge the Gap Between Informal and Formal Language? Meet MMA: A Multilingual and Multi-Domain Dataset Revolutionizing the Field
Mathematical content described in a formal language that is computer-checkable mechanically is referred to as standard mathematics. Mathematicians use formal languages, which are incorporated with tools for proofreading, such as HOL Light, Isabelle, Coq, and Lean. Converting natural language sources into verifiable formalizations is known as autoformalization. Verifying current mathematical conclusions may be made less expensive using an optimal autoformalization engine. It allows automated reasoning study domains that rely on formal languages, such as automated theorem proving, to access the large quantity of mathematics written in plain language. The ambition of automatically converting informal mathematics into formally provable material is as old as standard mathematics itself.
Autoformalization could only be taught recently because of advances in neural networks and Neural Machine Translation. Large parallel datasets made up of pairs of sequences that convey the same meaning in both the source and the target languages are usually needed for NMT techniques. Building a parallel dataset in both a formal and natural language that satisfies two requirements at once—that is, that the number of data points is sufficient for the machine learning methods that require a large amount of data and that the natural language component closely resembles how mathematics is written—is the most difficult aspect of autoformalization research. This is challenging because it requires expensive, highly qualified computer science and mathematics specialists to translate informal mathematical knowledge into a formal language manually.
By using a cutting-edge Large Language Model, GPT-4, to convert the two largest formal corpora, Archive of Formal Proofs in Isabelle and mathlib4 in Lean4, into natural language, the authors of this study addressed the absence of a parallel dataset. The two most important insights that informalization is far simpler than formalization and that a strong LLM may yield a variety of natural language outputs—facilitated this process. Researchers from the University of Cambridge and the University of Edinburgh produced a 332K informal-formal dataset simultaneously, which they call the MMA dataset. As far as they know, this is the first parallel dataset with several formal languages. It has four times as many data points as the largest available dataset.
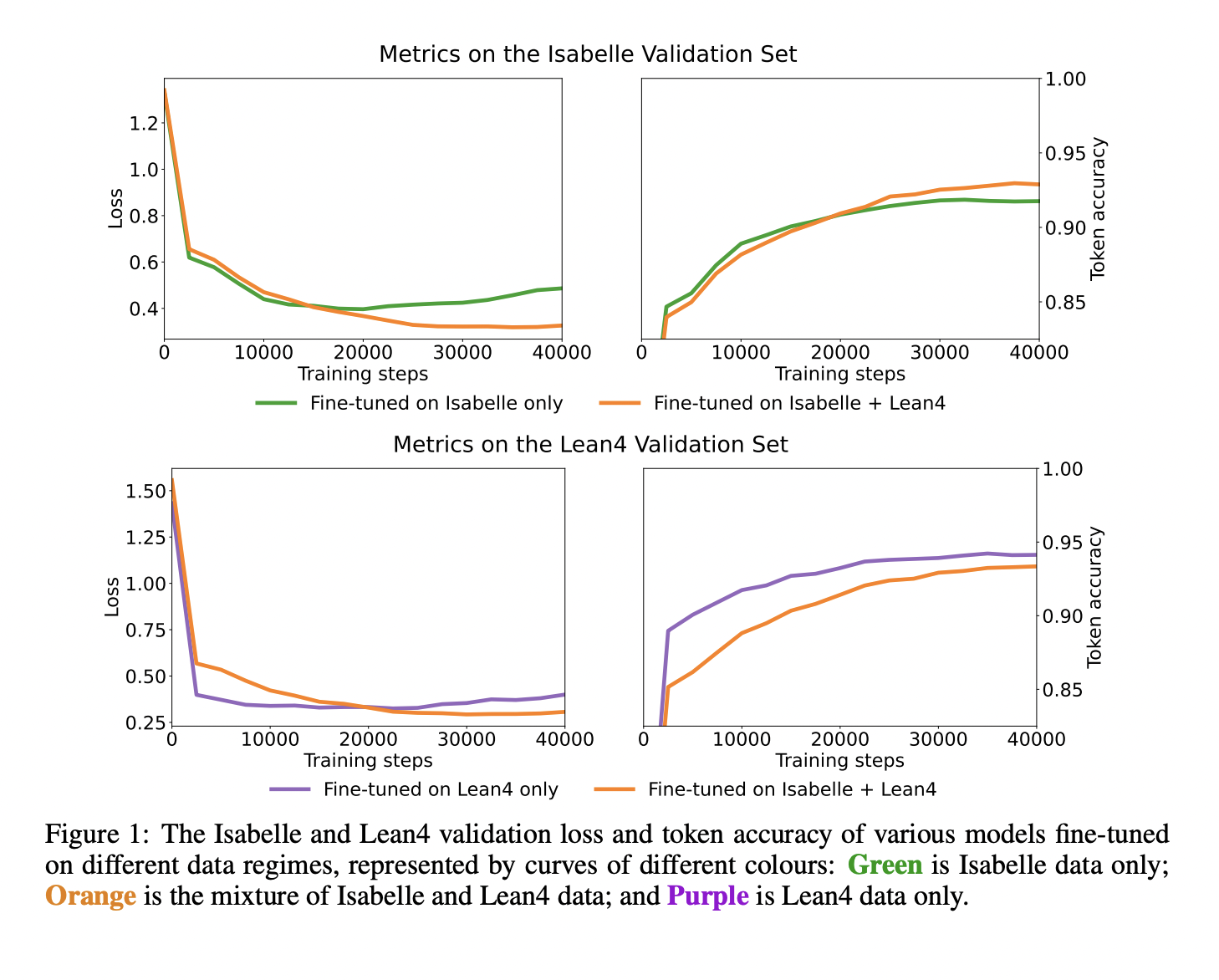
They optimized LLaMA-33B, an open-source and very effective LLM, on MMA to provide formal phrases corresponding to informal ones. Then, miniF2F and ProofNet, two autoformalization benchmarks, were used to assess the trained model. After the model was fine-tuned, 16 ‐ 18% of formal statements on the benchmarks that require no or minimum modification could be produced, compared to 0% for the raw model, according to a manual review of 50 outputs from each benchmark. Additionally, they adjusted two similar models independently for the same amount of steps on the Lean4 and Isabelle components of MMA. Their autoformalization performances are notably worse than those of the model trained on multilingual data, indicating the importance of autoformalization training on parallel data, including different formal languages.
Contributions:
• They create MMA, a collection of informal-formal pairings, by informalizing all formal assertions from mathlib4 and the Archive of Formal Proofs.
• They train the first language model that can auto-formalize to multiple languages in the zero-shot setting and manually evaluate it on two auto-formalization benchmarks. This is the first autoformalization dataset containing multiple formal languages, four times larger than the biggest existing dataset.
• They confirm that language models trained on MMA have robust auto-formalization capabilities and outperform language models trained on monolingual partitions of MMA with the same computational budget in auto-formalization.
• They make the optimized models available for deduction. In addition, they make the MMA dataset available for anybody to use in training and enriching autoformalization models with other domains and languages.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.