Can Language Models Replace Programmers? Researchers from Princeton and the University of Chicago Introduce SWE-bench: An Evaluation Framework that Tests Machine Learning Models on Solving Real Issues from GitHub
Evaluating the proficiency of language models in addressing real-world software engineering challenges is essential for their progress. Enter SWE-bench, an innovative evaluation framework that employs Python repositories’ GitHub issues and pull requests to gauge these models’ ability to tackle coding tasks and problem-solving. Surprisingly, the findings reveal that even the most advanced models can only handle straightforward issues. This highlights the pressing need for further advancements in language models to enable practical and intelligent software engineering solutions.
While prior research has introduced evaluation frameworks for language models, they often need more versatility and address the complexity of real-world software engineering tasks. Notably, existing benchmarks for code generation need to capture the depth of these challenges. The SWE-bench framework by researchers from Princeton University and the University of Chicago stands out by focusing on real-world software engineering issues, like patch generation and complex context reasoning, offering a more realistic and comprehensive evaluation for enhancing language models with software engineering capabilities. This is particularly relevant in the field of Machine Learning for Software Engineering.
As language models (LMs) are used widely in commercial applications, the need for robust benchmarks to evaluate their capabilities becomes evident. Existing benchmarks need to be revised in challenging LMs with real-world tasks. Software engineering tasks offer a compelling challenge with their complexity and verifiability through unit tests. SWE-bench leverages GitHub issues and solutions to create a practical benchmark for evaluating LMs in a software engineering context, promoting real-world applicability and continuous updates.
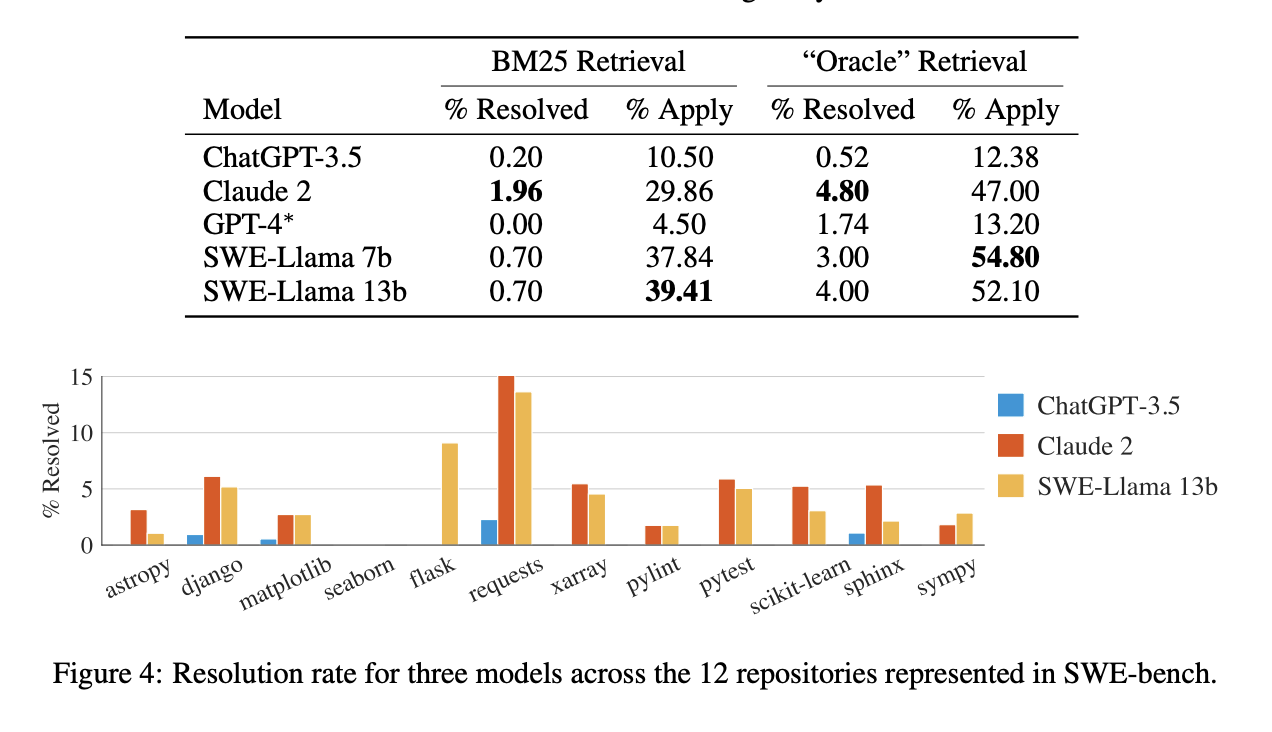
Their research includes 2,294 real-world software engineering problems from GitHub. LMs edit codebases to resolve issues across functions, classes, and files. Model inputs include task instructions, issue text, retrieved files, example patch, and a prompt. Model performance is evaluated under two context settings: sparse retrieval and oracle retrieval.
Evaluation results indicate that even state-of-the-art models like Claude 2 and GPT-4 struggle to resolve real-world software engineering issues, achieving pass rates as low as 4.8% and 1.7%, even with the best context retrieval methods. Their models perform worse when dealing with matters from longer contexts and exhibit sensitivity to context variations. Their models tend to generate shorter and less well-formatted patch files, highlighting challenges in handling complex code-related tasks.
As LMs advance, the paper highlights the critical need for their comprehensive evaluation in practical, real-world scenarios. The evaluation framework, SWE-bench, serves as a challenging and realistic testbed for assessing the capabilities of next-generation LMs within the context of software engineering. The evaluation results reveal the current limitations of even state-of-the-art LMs in handling complex software engineering challenges. Their contributions emphasize the necessity of developing more practical, intelligent, and autonomous LMs.
The researchers propose several avenues for advancing the SWE-bench evaluation framework. Their research suggests expanding the benchmark with a broader range of software engineering problems. Exploring advanced retrieval techniques and multi-modal learning approaches can enhance language models’ performance. Addressing limitations in understanding complex code changes and improving the generation of well-formatted patch files are highlighted as important areas for future exploration. These steps aim to create a more comprehensive and effective evaluation framework for language models in real-world software engineering scenarios.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.