Can Large Language Models Learn New Tricks? This Machine Learning Research from Google Introduces ‘CALM’: A Novel Approach for Enhancing AI Capabilities Through Composition
Large Language Models (LLMs), renowned for their foundational capabilities like commonsense reasoning and coherent language generation, have been fine-tuned for domain-specific tasks such as code generation and mathematical problem-solving. This trend has led to specialized models excelling in specific domains, like code generation or logical reasoning.
This prompts whether an anchor model can be combined with a domain-specific augmenting model to introduce novel capabilities, such as merging a model’s code understanding prowess with another’s language generation for code-to-text generation. Traditionally, the approach involves further pre-training or fine-tuning the anchor model on data used for training the augmenting model. However, this might need to be more practical due to computational costs. Working with distinct models enables leveraging established capabilities without encountering issues like catastrophic forgetting seen in traditional methods.
To tackle the obstacles related to training and data limitations outlined earlier, researchers at Google Research and Google DeepMind introduce and explore a pragmatic scenario for model composition: (i) having access to one or multiple augmenting models alongside an anchor model, (ii) being restricted from altering the weights of either model and (iii) having access to a limited dataset representing the combined capabilities of the provided models, such as code generation integrated with intricate logical reasoning.
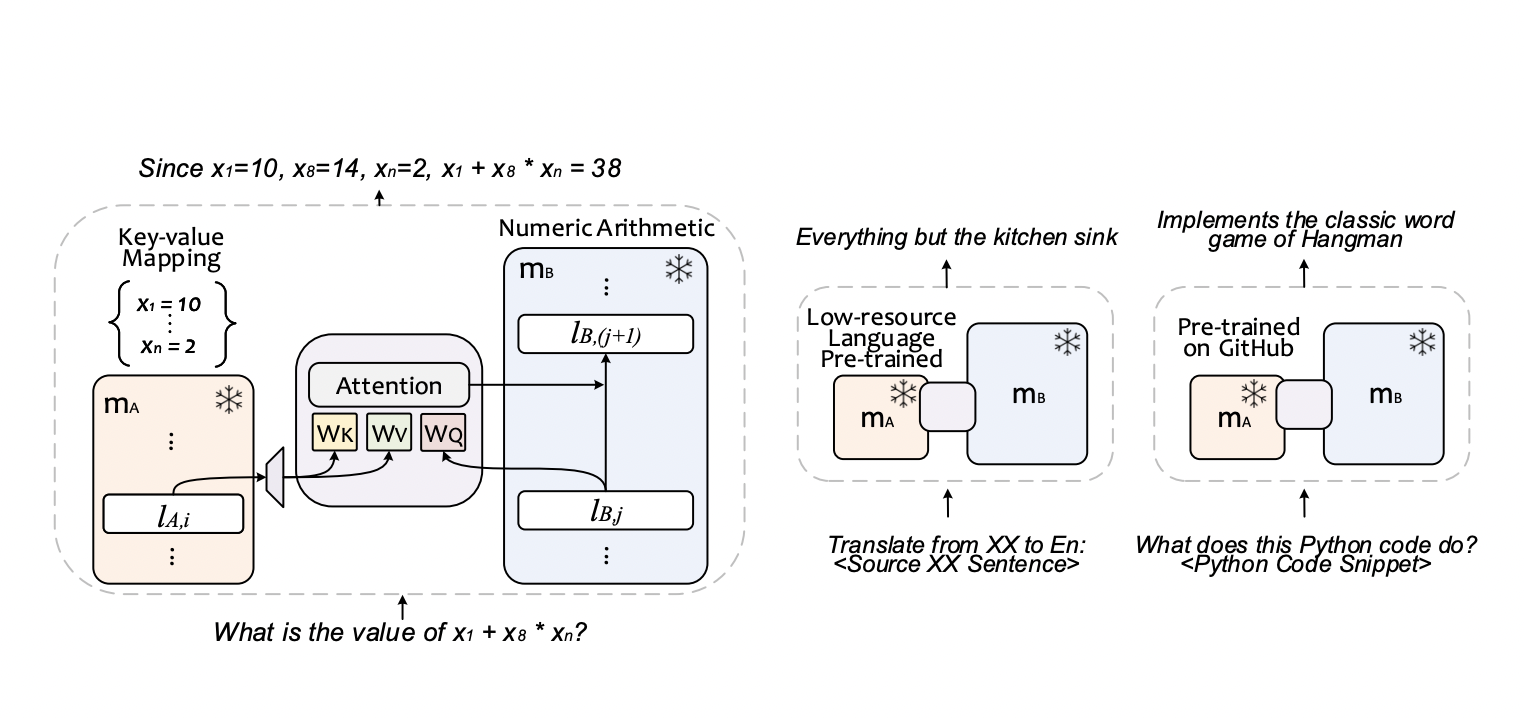
They propose an innovative framework called Composition to Augment Language Models (CALM) to tackle the general model composition scenario outlined earlier. Unlike superficial augmenting and anchor LMs amalgamations, CALM introduces a small set of trainable parameters within the intermediate layer representations of both augmenting and anchor models. CALM aims to discover an optimal fusion of these models, enhancing their collective performance in handling new complex tasks more effectively than either model operating alone, all the while retaining the distinct capabilities of each model.
They explore significant practical applications of CALM, focusing on language inclusivity and code generation. In the context of language inclusivity, they leverage a model trained specifically on low-resource languages. They combine this model with the LLM, granting them access to its advanced generation and reasoning abilities, resulting in notably enhanced performance for translation and arithmetic reasoning tasks in low-resource languages.
Interestingly, this composed model surpasses the performance of the two base models and outperforms versions of the LLM that underwent further pre-training or LoRA fine-tuning tailored for low-resource languages. In the case of code generation, they employ a model trained on diverse open-source code across multiple programming languages by integrating this model with the LLM. Hence, harnessing its underlying low-level logic and generation prowess, they achieve superior performance on tasks involving code explanation and completion compared to the performance of the two base models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.