Can Large Language Models Retain Old Skills While Learning New Ones? This Paper Introduces LLaMA Pro-8.3B: A New Frontier in AI Adaptability
Large Language Models (LLMs) have transformed the field of Natural Language Processing (NLP) and the way humans interact with machines. From question answering and text generation to text summarization and code completion, these models have extended their capabilities in a variety of tasks.
Though LLMs are highly adaptable, their potential as universal language agents is limited in programming, mathematics, the biomedical sciences, and finance. Methods like domain-adaptive pretraining improve LLMs using domain-specific corpora following their first pretraining with a lower computation cost.
However, catastrophic forgetting presents a major obstacle, as post-pretraining causes the model’s initial general abilities to deteriorate. This makes it difficult for the model to function at its optimal level on various tasks. Hence, a technique that adds domain-specific knowledge to LLMs without compromising their overall capabilities is required.
To address this issue, a team of researchers has suggested a new post-pretraining technique called block expansion for LLMs that involves extending Transformer blocks. With this method, the model’s information can be effectively and efficiently added without any catastrophic forgetting. Using duplicate Transformer blocks, this technique includes growing a pre-trained LLM that is available off the shelf.
While the remaining blocks stay frozen, the recently inserted blocks are exclusively fine-tuned using domain-specific corpora and feature zero-initialized linear layers to aid in identity mapping. An extended pre-trained model that performs well in both general and domain-specific tasks is the outcome of this method.
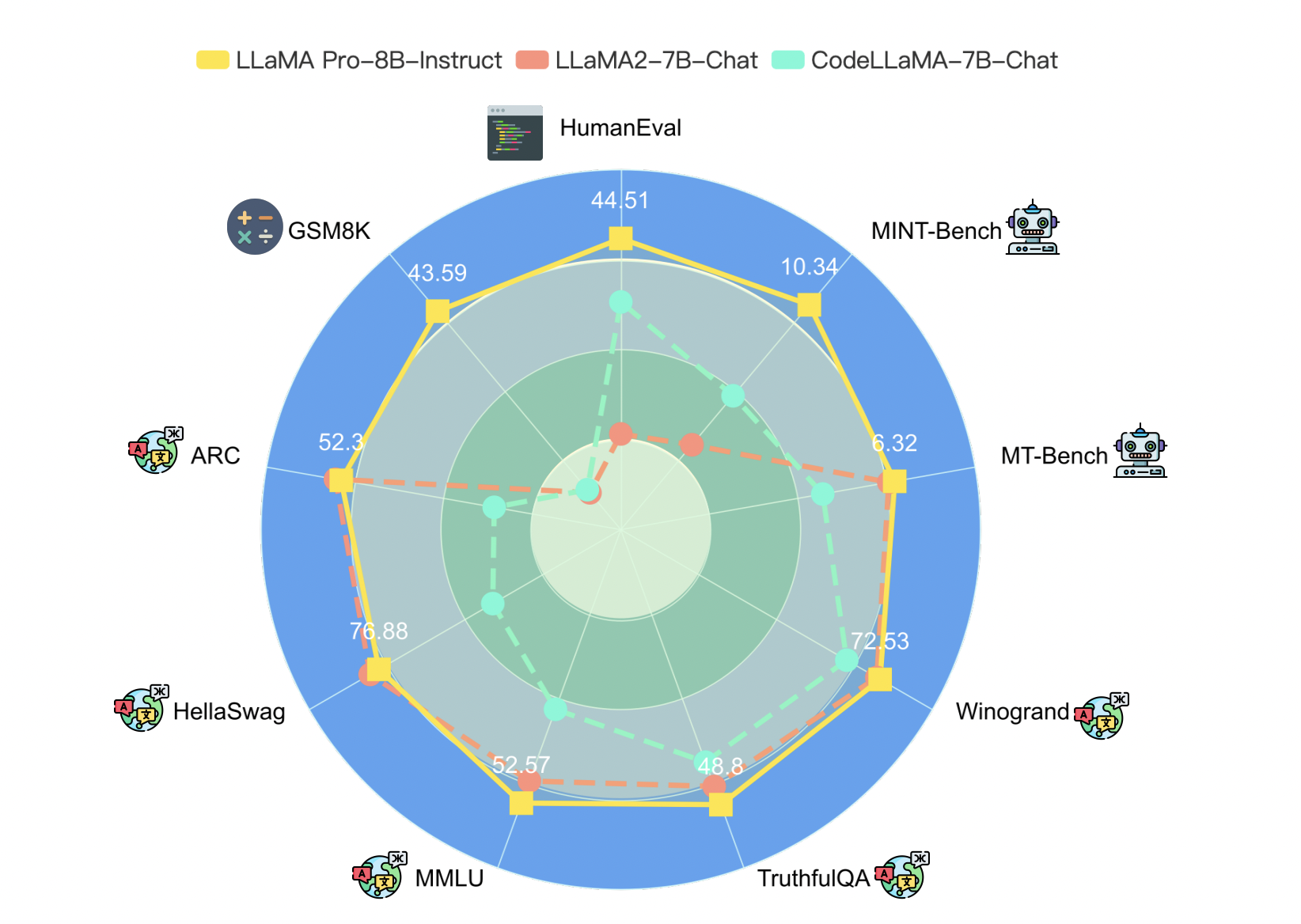
The team has introduced the family of LLAMA PRO in this study. By experimenting with code and math corpora, LLAMA PRO-8.3B has been developed. Initialized from LLaMA2-7B, this adaptable foundation model performs exceptionally well on a wide range of general tasks, programming, and mathematics. The possibility of catastrophic forgetting has been reduced by fine-tuning the extended blocks only with fresh corpus data, guaranteeing the model’s flexibility and proficiency with both newly learned and pre-existing knowledge.
LLAMA PRO has demonstrated superior performance on multiple benchmarks, as does its instruction-following equivalent, LLAMA PRO – INSTRUCT. They have significantly outperformed current open models in the LLaMA family, demonstrating the models’ great potential for reasoning and handling a variety of tasks as intelligent agents.
The team has summarized their primary contributions as follows.
- A new technique called block expansion has been presented for LLMs, making it easier to incorporate new information without sacrificing existing capabilities.
- Flexible models like LLAMA PRO and LLAMA PRO – INSTRUCT, which smoothly combine programming and natural languages, have been introduced.
- These have excelled in math, programming, and general jobs, demonstrating the models’ adaptability.
- LLAMA PRO family has been thoroughly benchmarked on a variety of datasets that include both agent-oriented and traditional workloads.
- LLAMA PRO’s superiority and enormous potential have been demonstrated in handling more complicated and wide-ranging applications.
In conclusion, this study has provided important new insights into the interplay between programming and natural languages, providing a solid basis for creating sophisticated language agents that can function well in various settings. The results have highlighted how crucial it is to overcome the flaws in LLMs’ processes for learning new skills and point the way towards a viable path for developing more flexible and powerful language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.