Can Large Language Models Revolutionize Multi-Scene Video Generation? Meet VideoDirectorGPT: The Future of Dynamic Text-to-Video Creation
With the continuous advancements in the field of Artificial Intelligence and Machine Learning, text-to-image generation and text-to-video generation have made significant developments. Text-to-video (T2V) generation goes beyond Text-to-image by producing brief movies, often with 16 frames at two frames per second, based on verbal prompts. With numerous works contributing to the creation of these brief videos, this growing field has advanced quickly. Long video generation, which aims to produce films lasting several minutes with a narrative, has been more popular recently.
One drawback of creating lengthy films is that they frequently include repeated patterns or continuous movements rather than transitions and dynamics involving several changing actions or occurrences. The ability to develop layouts and programs to control visual components has also been demonstrated by large language models (LLMs), including GPT-4. This is especially true in the context of image production.
Using the knowledge present in these LLMs to assist the creation of reliable multi-scene has been a question for the researchers. In a recent research, a team of researchers introduced VideoDirectorGPT, a unique framework that builds on the expertise found in LLMs to handle the problem of producing multi-scene videos consistently. For both planning video content and producing grounded videos, the framework makes use of LLMs.
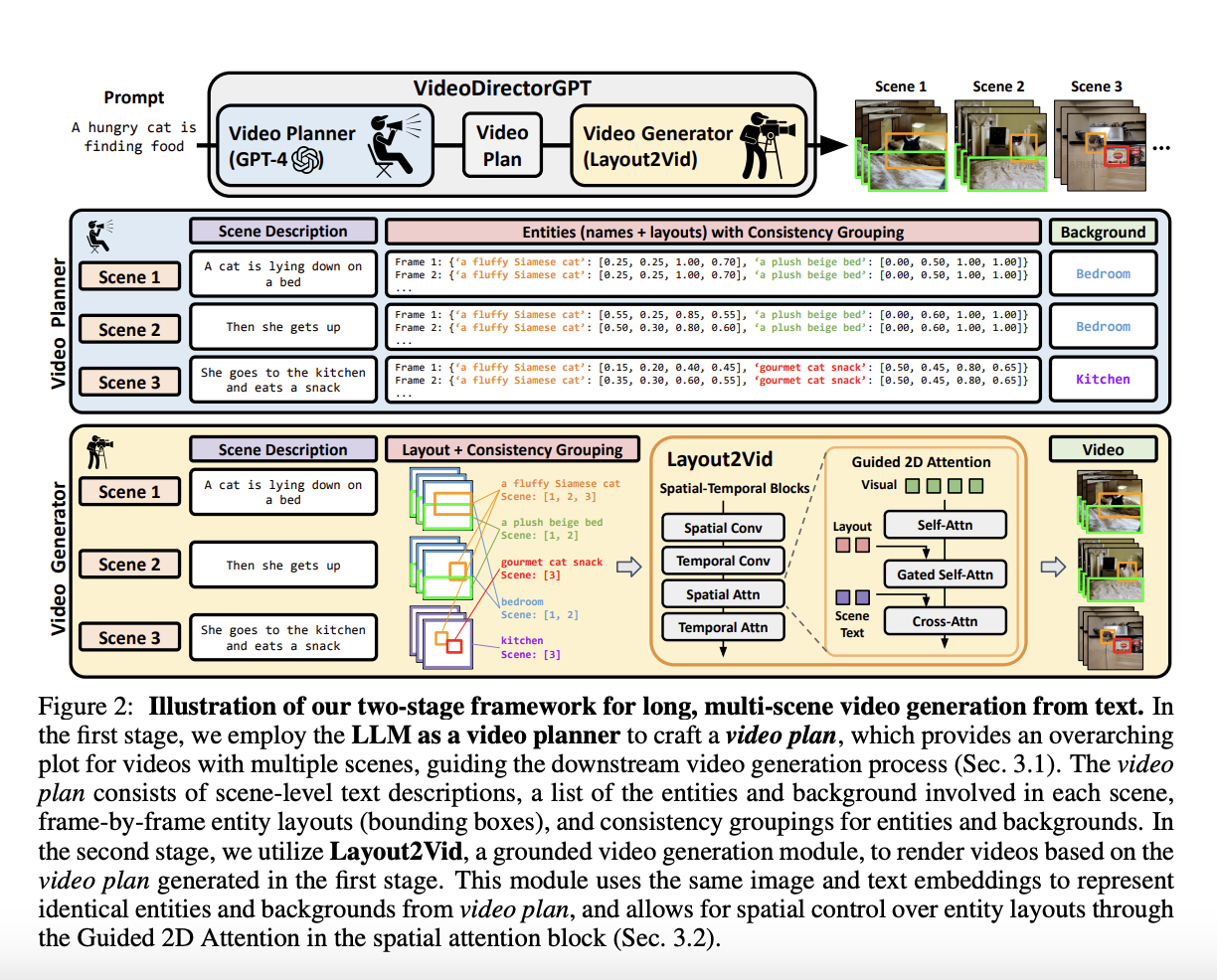
This framework has been divided into two main stages. First is video planning, in which an LLM is used to create a video plan in which the video’s overall structure is represented. Having several scenes with text descriptions, entity names and layouts, and backgrounds, it also includes consistency groupings outlining which objects or backdrops should maintain visual consistency throughout scenes.
The creation of the video plan takes two steps. First, the LLM is used to transform a single text prompt into multi-step scene descriptions. This comprises in-depth explanations, a list of the entities, and backgrounds. In order to maintain visual coherence, the LLM is also asked to produce extra details for each entity, such as color and dress, as well as to aggregate entities across frames and scenes. The LLM creates a list of bounding boxes for the entities in every frame based on the supplied entity list and scene description in the second step, which expands the detailed layouts for each scene. This thorough video plan serves as a roadmap for the ensuing video creation stage.
In the second stage, the framework uses a video generator named Layout2Vid and the output from the video planner as its starting point. This video generator can maintain the temporal consistency of entities and backdrops over several scenes and provides explicit control over spatial layouts. Layout2Vid does this without requiring expensive video-level training because it was taught exclusively with image-level annotations. The experiments conducted with VideoDirectorGPT demonstrated its effectiveness in various aspects of video generation, which are as follows.
- Layout and Movement Control: The framework substantially enhances the control over layouts and movements, both in single-scene and multi-scene video generation.
- Visual Consistency Across Scenes: It succeeds in generating multi-scene videos that maintain visual consistency throughout different scenes.
- Competitive Performance: The framework performs competitively with state-of-the-art models in open-domain single-scene text-to-video generation.
- Dynamic Layout Control: VideoDirectorGPT showcases the ability to dynamically adjust the strength of layout guidance, allowing for flexibility in generating videos with varying degrees of control.
- User-Provided Images: The framework is versatile enough to generate videos that incorporate user-provided images, demonstrating its adaptability and potential for creative applications.
In conclusion, VideoDirectorGPT has marked a considerable advancement in text-to-video generation. It efficiently uses LLMs’ planning skills to create coherent multi-scene movies, overcoming the drawbacks of earlier methods and igniting new directions for this field of study.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.

Credit: Source link
Comments are closed.