Can Large-Scale Language Models Replace Humans in Text Evaluation Tasks? This AI Paper Proposes to Use LLM for Evaluating the Quality of Texts to Serve as an Alternative to Human Evaluation
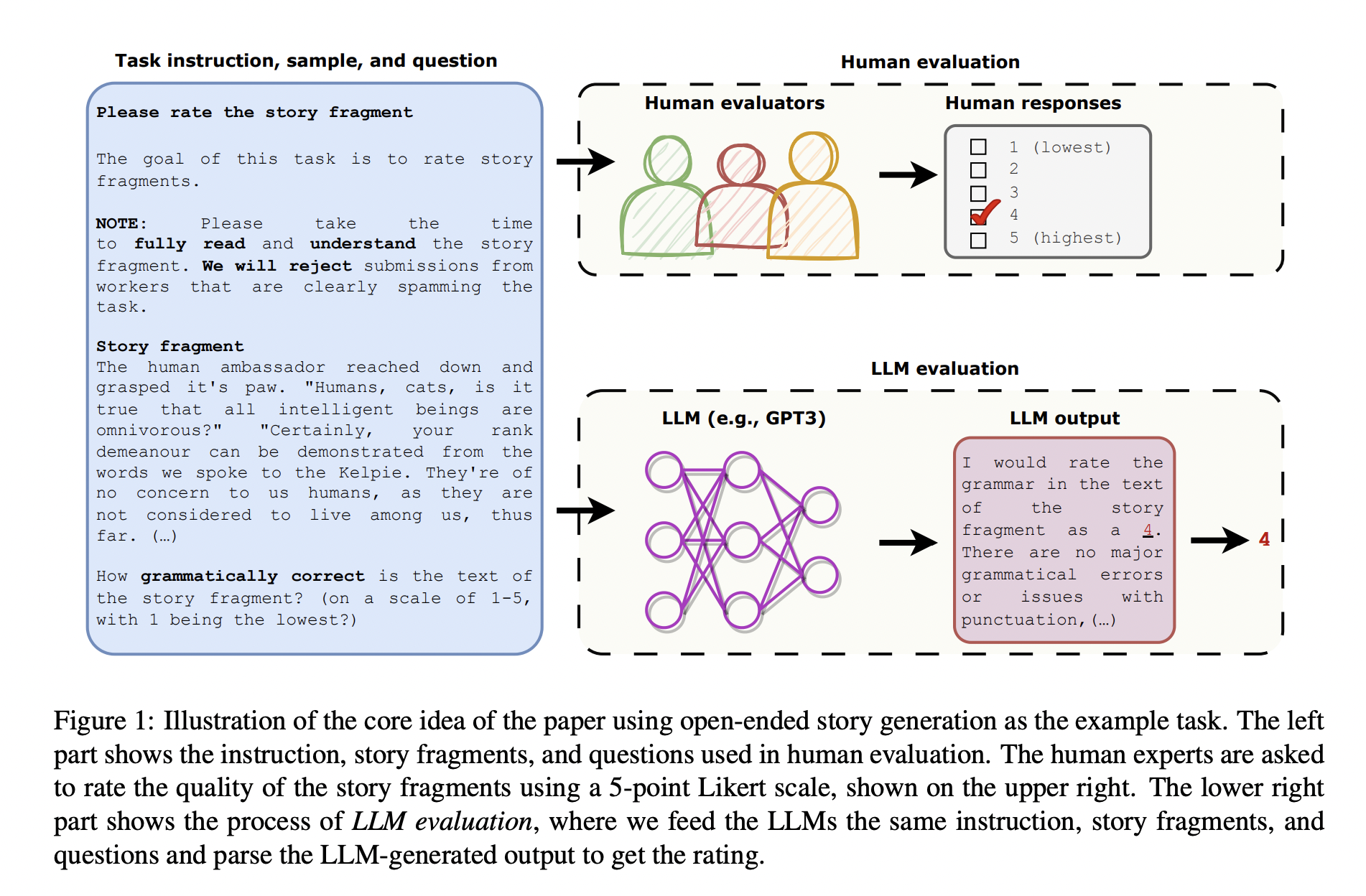
Human evaluation has been used to evaluate the performance of natural language processing models and algorithms for denoting text quality. Still, human evaluation is only sometimes consistent and may not be reproducible as it is hard to recruit the same human evaluators and return the same evaluation as the evaluator uses a different number of factors, including the subjectivity or differences in their interpretation of the evaluation criteria.
The researchers from National Taiwan University have studied the use of “large-scale language models” (models trained to model human language. They are trained using large amounts of textual data accessible on the Web, and as a result, they learn how to use a person’s language) as a new evaluation method to address this reproducibility issue. The researchers presented the LLMs with the same instructions, samples to be evaluated, and questions used to conduct human evaluation and then asked the LLMs to generate responses to those questions. They used human and LLM evaluation to evaluate the texts in two NLP tasks: open-ended story generation and adversarial attacks.
In “open-ended story generation,” they checked the quality of stories generated by a human and a generative model (GPT-2) evaluated by a large-scale language model and a human to verify whether the large-scale language model can rate human-written stories higher than those generated by the generative model.
To do so, they first generated a questionnaire(evaluation instructions, generated story fragments, and evaluation questions) prepared and rated on a Likert scale (5 levels) based on four different attributes (grammatical accuracy, consistency, liking, and relevance), respectively.
In human evaluation, the user responds to the prepared questionnaire as is. For the evaluation by the large-scale language model, they input the questionnaire as a prompt and obtain the output by the large-scale language model. The researchers used four large language models T0, text-curie-001, text-davinci-003, and ChatGPT. For the human evaluation, the researchers used renowned English teachers. These large-scale language models and English teachers evaluated 200 human-written and 200 GPT-2 generated stories.
Ratings given by English teachers show a preference for all four attributes (Grammaticality, Cohesiveness, Likability, and Relevance) for human-written stories. This shows that English teachers can distinguish the difference in quality between stories written by the generative model and those written by humans. But, T0 and text-curie-001 show no clear preference for human-written stories. This indicates that large-scale language models are less competent than human experts in evaluating open-ended story generation. On the other hand, text-davinci-003 shows a clear preference for human-written stories and English teachers. Further, ChatGPT also showed a higher rating for human-written stories.
They examined a task for adversarial attacks that test the AI’s ability to classify sentences. They tested the ability to classify a sentence on some kind of hostile attack ( using synonyms to slightly change the sentence). They then evaluated how the attack affects the AI’s ability to classify the sentences. They performed this by using a large-scale language model (ChatGPT) and a human.
For adversarial attacks, English teachers (Human evaluation) rated sentences produced by hostile attacks lower than the original sentences on fluency and preservation of meaning. Further, ChatGPT gave higher ratings to hostile-attack sentences than English teachers. Also, ChatGPT rated hostile-attack sentences lower than the original sentences, and overall, the large-scale language models evaluated the quality of hostile-attack sentences and original sentences in the same way as humans.
The researchers noted the following four advantages of evaluation by large-scale language models: Reproducibility, Independence, Cost efficiency and speed, and Reduced exposure to objectionable content.
However, Large-scale language models are also susceptible to misinterpretation of facts, and the learning method can introduce biases. Moreover, the absence of emotions in these models might limit their efficacy in assessing tasks that involve emotions. Human evaluations and assessments from extensive language models have distinct strengths and weaknesses. Their optimal utility is likely to be achieved through a combination of humans and these large-scale models.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.