Can LLMs Debug Programs like Human Developers? UCSD Researchers Introduce LDB: A Machine Learning-Based Debugging Framework with LLMs
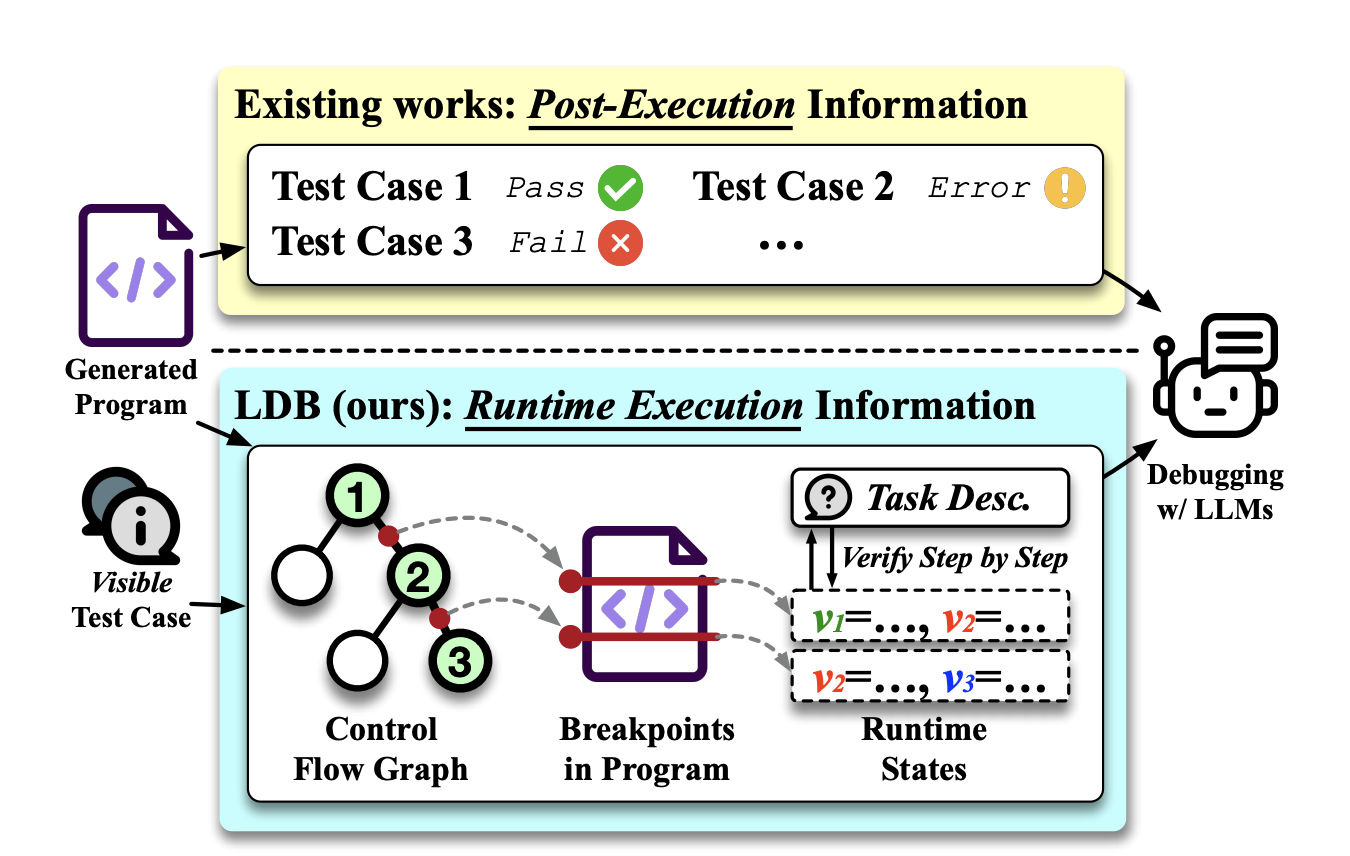
Large language models (LLMs) have revolutionized code generation in software development, providing developers with tools to automate complex coding tasks. Yet, as sophisticated as these models have become, crafting flawless, logic-bound code necessitates advanced debugging capabilities beyond the current standards. Traditional debugging approaches often fail to address the need to address the intricate nuances of programming logic and data operations inherent in LLM-generated code. Recognizing this gap, researchers from the University of California, San Diego, have developed the Large Language Model Debugger (LDB), a groundbreaking framework designed to refine debugging by harnessing runtime execution information.
LDB’s innovative strategy diverges significantly from existing methodologies by deconstructing programs into basic blocks. This decomposition allows for an in-depth analysis of intermediate variables’ values throughout the program’s execution, providing a more granular perspective on debugging. By leveraging detailed execution traces and inspecting variable states at each step, LDB enables LLMs to focus on discrete code units, drastically improving their capability to identify errors and verify code correctness against specified tasks.
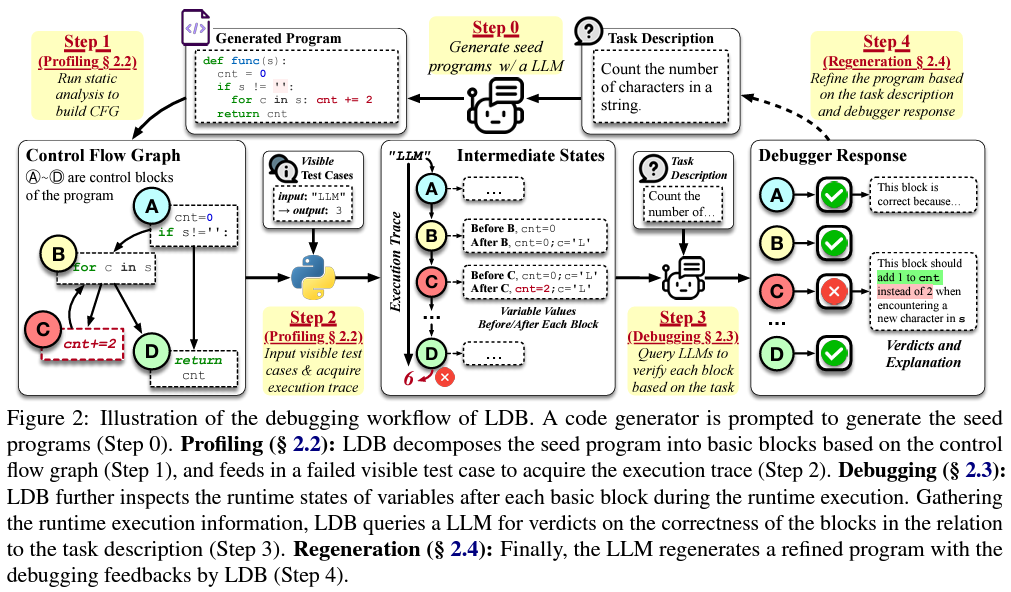
The introduction of LDB marks a pivotal advancement in code debugging techniques. Traditional methods, which treat the generated code as a monolithic block, rely heavily on post-execution feedback for error identification. Such an approach is inherently limited, especially when addressing complex logic flows and data operations. LDB, on the other hand, mimics the human debugging process, where developers employ breakpoints to examine the runtime execution and intermediate variables closely. This methodology facilitates a more nuanced debugging process and aligns closely with developers’ iterative refinement strategies in real-world scenarios.
Empirical evidence underscores the efficacy of the LDB framework. The researchers’ experiments demonstrate that LDB significantly enhances the performance of code generation models. For instance, when applied across various benchmarks, including HumanEval, MBPP, and TransCoder, LDB consistently improved baseline performance by up to 9.8%. Such improvements are attributed to LDB’s ability to provide LLMs with a detailed examination of execution flows, enabling a precise identification and correction of errors within the generated code. This level of granularity in debugging was previously unattainable with existing methods, establishing LDB as a new state-of-the-art in the realm of code debugging.
The implications of LDB’s development extend far beyond immediate performance enhancements. By offering a detailed insight into the runtime execution of code, LDB equips LLMs with the tools necessary for generating more accurate, logical, and efficient code. This not only bolsters the reliability of automated code generation but also paves the way for more sophisticated development tools in the future. LDB’s success in integrating runtime execution info with debugging shows the potential of merging programming practices with AI and machine learning.
In conclusion, the Large Language Model Debugger developed by the University of California, San Diego, represents a significant leap forward in automated code generation and debugging. By embracing a detailed analysis of runtime execution information, LDB addresses the critical challenges faced in debugging LLM-generated code, offering a pathway to more reliable, efficient, and logical programming solutions. As software development continues to evolve, tools like LDB will undoubtedly play a crucial role in shaping the future of programming, making the process more accessible and error-free for developers around the globe.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.