Can Synthetic Clinical Text Generation Revolutionize Clinical NLP Tasks? Meet ClinGen: An AI Model that Involves Clinical Knowledge Extraction and Context-Informed LLM Prompting
Medical data extraction, analysis, and interpretation from unstructured clinical literature are included in the emerging discipline of clinical natural language processing (NLP). Even with its importance, particular difficulties arise while developing methodologies for clinical NLP. For instance, clinical texts might confuse ordinary NLP models since they are frequently filled with acronyms and specialized medical terminology. Fortunately, recent developments in large language models provide a promising solution to these problems since they are pre-trained on large corpora and include billions of parameters, naturally capturing substantial clinical information.
These developments highlight the necessity for developing specific methods for modifying LLMs for use in clinical settings that both deal with the complexity of terminology and enhance models via fine-tuning clinical data. Even though generic LLMs have a lot of potential, using them directly to make inferences about clinical text data is only sometimes desirable in real-world settings. First, these LLMs frequently have billions of parameters, requiring substantial processing power even during conception. This results in high infrastructure costs and lengthy inference times. The clinical text’s sensitive patient information also raises concerns about privacy and regulatory compliance. Creating synthetic training data with LLMs is a potential technique to address these issues as it uses LLMs’ capabilities in a resource- and privacy-conscious way.
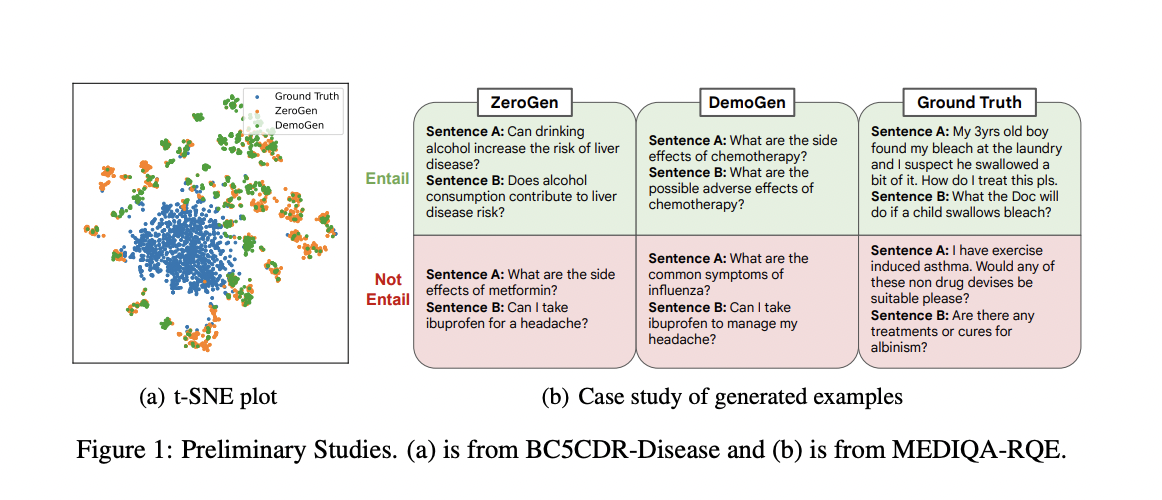
Models can operate at high-performance levels while adhering to data privacy laws when trained on these artificial datasets, replicating clinical data from the real world. In general machine learning, one of the most common study areas is synthetic data creation using foundation models. However, using LLMs trained on available texts to create clinical data has special hurdles when providing high-quality data that follows the original dataset’s distribution. To evaluate the quality of the data produced by the existing techniques, they conduct a thorough analysis focused on variety and distribution. The Central Moment Discrepancy (CMD) score and the t-SNE embedding visualization reveal a notable shift in the data distribution.
They also look at the amounts and frequencies of clinically related entities in the synthetic data; a significant decrease is seen when comparing the synthetic data to the ground truth data. Although several studies have explored creating clinical data using language models, many of these initiatives are task-specific. Electronic health records, clinical notes, medical text mining, and medical conversations are a few examples. These studies can use excessive training data and frequently use language models directly for text production. There are only so many cohesive ideas for improving how LLMs are modified to produce synthetic text that will help with clinical downstream applications.
Inspired by the above research, researchers from Emory University and Georgia Institute of Technology put forth CLINGEN, a generic framework imbued with clinical expertise for producing high-quality clinical texts in few-shot situations. Their ultimate objectives are to promote subject variety in the produced text and close the gap between synthetic and ground-truth data. They provide a method to use clinical knowledge extraction to contextualize the prompts to achieve this goal. This involves getting ideas for clinical themes from KGs and LLMs and advice for writing styles from LLMs. In this way, CLINGEN combines the internal parametric information embodied in big language models with non-parametric insights from external clinical knowledge graphs.
It is important to note that CLINGEN may be easily used for various fundamental clinical NLP tasks and requires very little extra human work. The following is a summary of their contributions:
• For creating clinical text data in few-shot circumstances, they suggest CLINGEN, a generic framework filled with clinical information.
• They offer a straightforward yet efficient method to use clinical knowledge extraction to tailor the prompts toward the intended clinical NLP tasks, which may be easily applied to various activities in clinical NLP. This involves getting ideas for clinical themes from KGs and LLMs and advice for writing styles from LLMs.
• They carry out a thorough analysis of the creation of synthetic clinical data using 16 datasets and 7 clinical NLP tasks. Experimental results show that CLINGEN increases the variety of the produced training samples while aligning more closely with the original data distribution. The empirical performance increases (8.98% for PubMedBERTBase and 7.27% for PubMedBERTLarge) are consistent across multiple tasks with different LLMs and classifiers.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.