Can (Very) Simple Math Informs RLHF For Large Language Models LLMs? This AI Paper Says Yes!
Incorporating human input is a key component of the recent impressive improvements in large language model (LLM) capacities, such as ChatGPT and GPT-4. To use human feedback effectively, a reward model that incorporates human preferences, values, and ethical issues must first be trained. The LLMs are then adjusted using reinforcement learning under the direction of the reward model. This procedure, also known as reinforcement learning from human feedback (RLHF), successfully coordinates LLMs with human purpose, significantly enhancing the caliber of interpersonal communication.
It isn’t easy to create a reward system that is functional and based on human preferences. It becomes very challenging when a human labeler fails to provide a numerical grade to a response or completion for a particular prompt. Instead, pairwise comparisons of completions in terms of quality are far simpler for people to make, and this approach was used in the creation of InstructGPT. In particular, a human labeler sorts the completions from highest to lowest perceived quality after being shown many completions produced by the LLMs for the same prompt.
The replies are then rewarded according to a reward model developed after training a neural network to match the ranks of human preferences nearly as feasible. Despite certain advantages, such as removing calibration problems, rankings do not adequately reflect the various reward distributions of multiple prompts. This is so that it is clear how much better one completion is than another when ranked higher. Since some RLHF prompts are open-ended or, to put it another way, reliant on the user’s history, the reward distribution might range over a wide range; thus, this worry is particularly relevant.
In contrast, some prompts are closed-ended, producing responses that should receive a high or low score, resulting in an approximately two-point mass distribution for the reward distribution. Examples of the first kind of prompts include “Prove the Pythagorean theorem” and “Is chicken a dinosaur.” Examples of the second kind include “prove the Pythagorean theorem” and “write a short story about how AI will look like in 100 years.” The incentive model may only be able to assist LLMs in appropriately measuring uncertainty if they consider the subtleties of various cues.
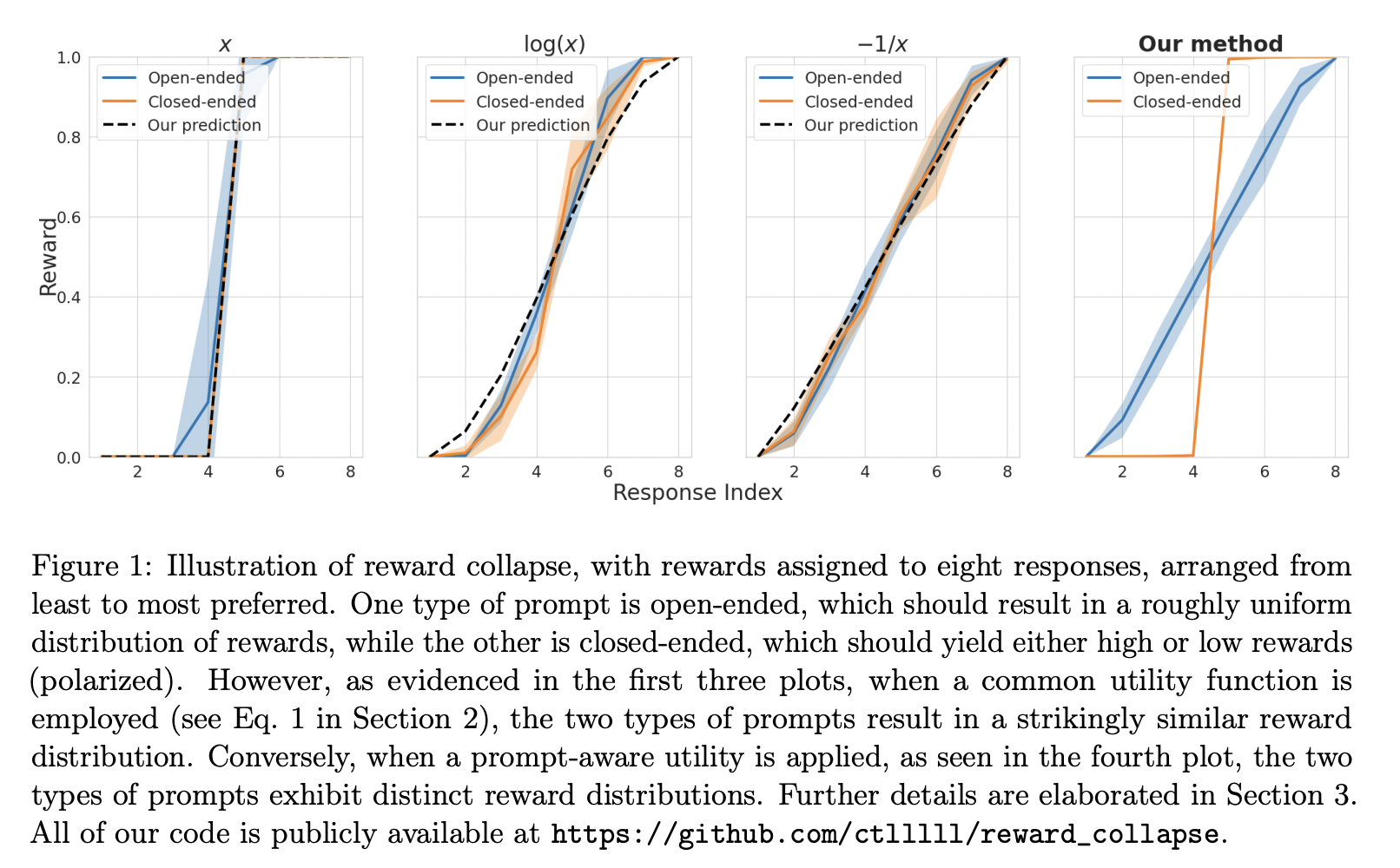
Researchers from Stanford University, Princeton University, and the University of Pennsylvania make documentation of an unexpected phenomenon that shows how training a reward model on preference rankings can provide the same reward distribution independent of the prompts. This event, which takes place during the last stage of training, is known as reward collapse. It’s interesting to note that before this event was proved empirically, their theoretical analysis anticipated it. They demonstrate that a straightforward optimization program or even more simply, a closed-form expression may be used to infer the collapse reward distribution numerically. Their prediction of reward collapse is in very good accord with the empirical findings.
Their second major contribution is introducing a principled strategy to prevent reward collapse using data from the same optimization program that helped forecast its occurrence. Reward collapse is undesirable because it ignores the minute distinctions between different prompts and might result in the miscalibration of human choice when LLMs are trained using reinforcement learning and the reward model. Early termination of the reward model’s training is a simple solution to this problem, but it is rather arbitrary and can be difficult to decide when to end.
In essence, they suggest training the reward model with different utility functions based on the prompts, such that the resultant reward distribution may be either broadly scattered or tightly concentrated, depending on whether the prompt is open-ended or closed-ended. This prompt-aware technique has the obvious benefit of analytical analysis, allowing for complete customization of the reward distribution’s structure as needed. Their findings demonstrate that reward collapse may be significantly reduced by utilizing this prompt-aware technique.
Check Out The Paper and Github link. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.