Can Video Segmentation Be More Cost-Effective? Meet DEVA: A Decoupled Video Segmentation Approach that Saves on Annotations and Generalizes Across Tasks

Have you ever wondered how surveillance systems work and how we can identify individuals or vehicles using just videos? Or how is an orca identified using underwater documentaries? Or perhaps live sports analysis? All this is done via video segmentation. Video segmentation is the process of partitioning videos into multiple regions based on certain characteristics, such as object boundaries, motion, color, texture, or other visual features. The basic idea is to identify and separate different objects from the background and temporal events in a video and to provide a more detailed and structured representation of the visual content.
Expanding the use of algorithms for video segmentation can be costly because it requires labeling a lot of data. To make it easier to track objects in videos without needing to train the algorithm for each specific task, researchers have come up with a decoupled video segmentation DEVA. DEVA involves two main parts: one that’s specialized for each task to find objects in individual frames and another part that helps connect the dots over time, regardless of what the objects are. This way, DEVA can be more flexible and adaptable for various video segmentation tasks without the need for extensive training data.
With this design, we can get away with having a simpler image-level model for the specific task we’re interested in (which is less expensive to train) and a universal temporal propagation model that only needs to be trained once and can work for various tasks. To make these two modules work together effectively, researchers use a bi-directional propagation approach. This helps to merge segmentation guesses from different frames in a way that makes the final segmentation look consistent, even when it’s done online or in real time.
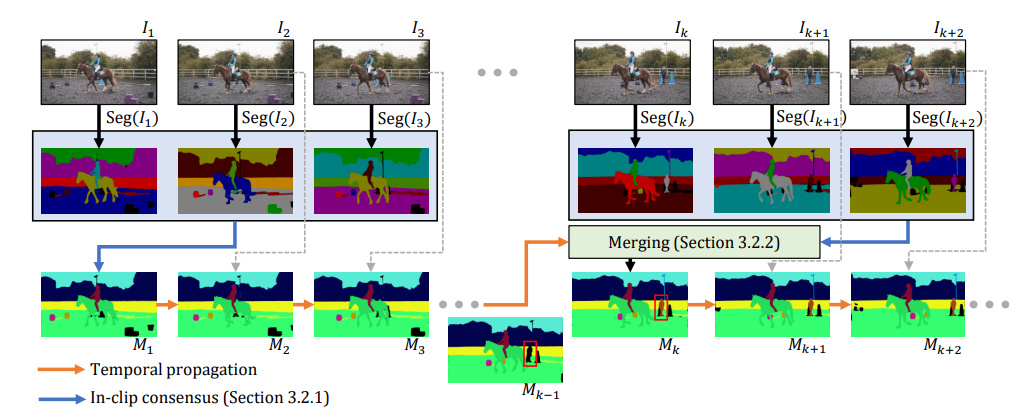
The above image provides us with an overview of the framework. The research team first filters image-level segmentations with in-clip consensus and temporally propagates this result forward. To incorporate a new image segmentation at a later time step (for previously unseen objects, e.g., red box), they merge the propagated results with in-clip consensus.
The approach adopted in this research makes significant use of external task-agnostic data, aiming to decrease dependence on the specific target task. It results in better generalization capabilities, particularly for tasks with limited available data compared to end-to-end methods. It does not even require fine-tuning. When paired with universal image segmentation models, this decoupled paradigm showcases cutting-edge performance. It most definitely represents an initial stride towards achieving state-of-the-art large-vocabulary video segmentation in an open-world context!
Check out the Paper, Github, and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Credit: Source link
Comments are closed.