Cerebras Releases 7 GPT-based Large Language Models for Generative AI
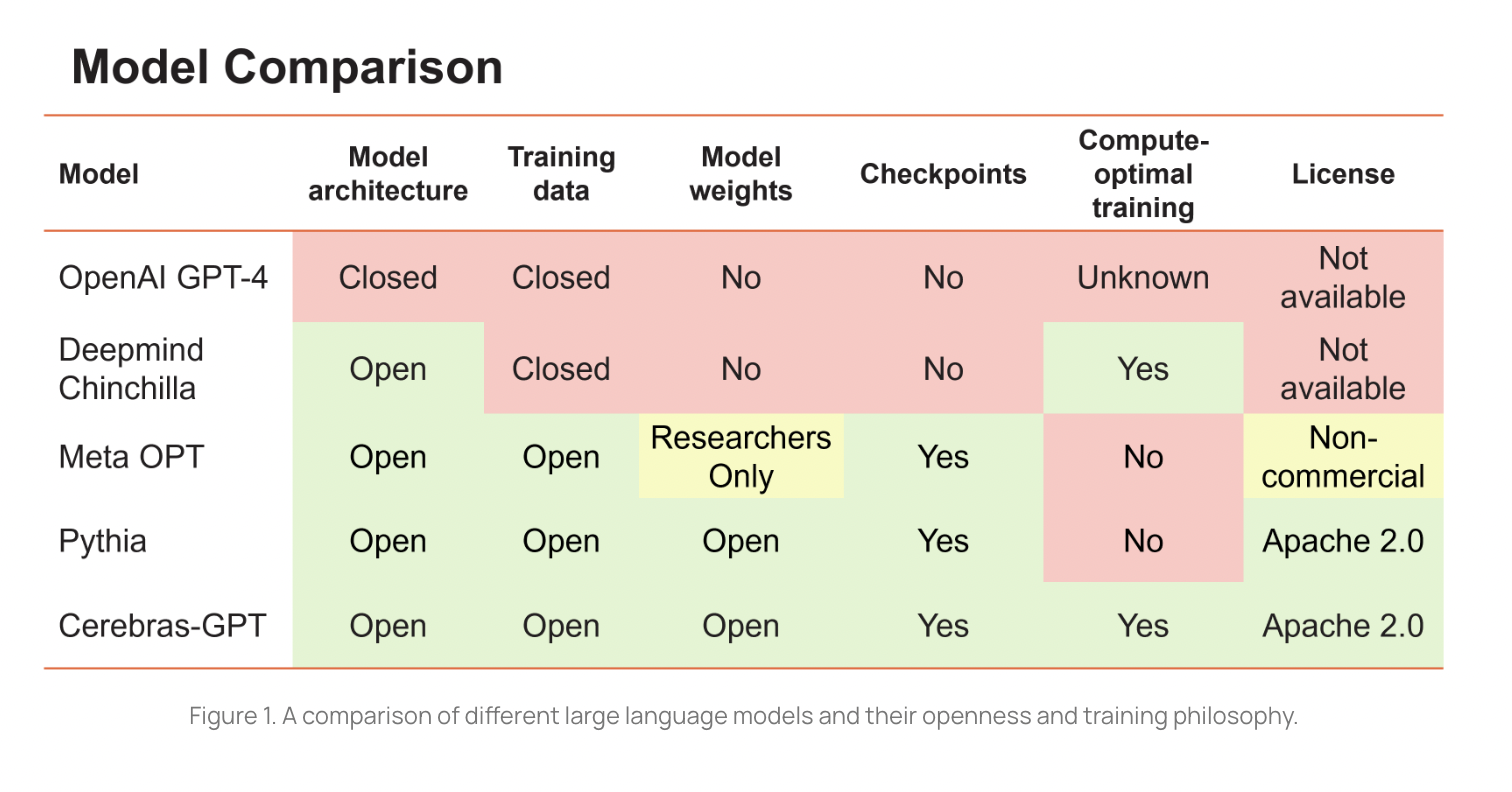
Rising entry barriers are hindering AI’s potential to revolutionize global trade. OpenAI’s GPT4 is the most recent big language model to be disclosed. However, the model’s architecture, training data, hardware, and hyperparameters are kept secret. Large models are increasingly being constructed by businesses, with access to the resulting models restricted to APIs and locked datasets.
Researchers feel it is crucial to have access to open, replicable, and royalty-free state-of-the-art models for both research and commercial applications for LLMs to be a freely available technology. To this goal, scientists have developed a set of transformer models, dubbed Cerebras-GPT, using cutting-edge methods and publicly available datasets. The Chinchilla formula was used to train these models, making them the first GPT models publicly available under the Apache 2.0 license.
Cerebras Systems Inc., a manufacturer of AI chips, recently revealed that it has trained and released seven GPT-based big language models for generative AI. Cerebras has announced that it will provide the models and their associated weights and training recipe under the open-source Apache 2.0 license. Notable about these new LLMs is that they are the first to be trained on the Cerebras Andromeda AI supercluster’s CS-2 systems, which are driven by the Cerebras WSE-2 chip and are optimized to execute AI software. This means they are pioneering LLMs that have been trained without GPU-based technologies.
When it comes to huge linguistic representations, there are two competing philosophies. Models like OpenAI’s GPT-4 and DeepMind’s Chinchilla, which have been trained on proprietary data, belong to the first category. Unfortunately, such models’ source code and learned weights are kept secret. The second category contains open-source models that need to be trained in a compute-optimal manner, such as Meta’s OPT and Eleuther’s Pythia.
Cerebras-GPT was created as a companion to Pythia; it shares the same public Pile dataset and aims to construct a training-efficient scaling law and family of models across a wide range of model sizes. Each of the seven models that make up Cerebras-GPT is trained with 20 tokens per parameter and has a size of either 111M, 256M, 590M, 1.3B, 2.7B, 6.7B, or 13B. Cerebras-GPT minimizes loss-per-unit-of-computing across all model sizes by selecting the most appropriate training tokens.
To carry on this line of inquiry, Cerebras-GPT uses the publicly available Pile dataset to develop a scaling law. This scaling law gives a computationally fast method for training LLMs of arbitrary size using Pile. Researchers plan to further the progress of big language models by publicizing the findings to provide a beneficial resource for the community.
Cerebras-GPT was tested on various language-based tasks, including sentence completion and question-and-answer sessions, to determine how well it performed. Even if the models are competent at comprehending natural language, that proficiency may not carry over to the specialized tasks in the pipeline. As shown in Figure 4, Cerebras-GPT maintains state-of-the-art training efficiency for most frequent downstream tasks. Scaling for downstream natural language tasks has yet to be reported in the literature, even though earlier scaling laws have demonstrated rising in the pre-training loss.

Cerebras GPT was educated on 16 CS-2 systems using traditional data parallelism. Cerebras CS-2 devices have enough memory to operate even the largest models on a single machine without splitting the model, making this viable. Researchers constructed the Cerebras Wafer-Scale Cluster to facilitate simple scaling specifically for the CS-2. Using weight streaming, a HW/SW co-designed execution technique, model size, and cluster size can be scaled independently without the need for model parallelism. Increasing the cluster size is as easy as editing a configuration file with this design.
The Andromeda cluster, a 16x Cerebras Wafer-Scale Cluster, was used to train all Cerebras-GPT models. The cluster made it possible to run all trials fast, eliminating the requirement for time-consuming steps like distributed systems engineering and model parallel tuning often required on GPU clusters. Most importantly, it freed up academics to concentrate on ML design rather than distributed system architecture. The Cerebras AI Model Studio provides access to the Cerebras Wafer-Scale Cluster in the cloud because researchers consider the capacity to easily train big models as a significant enabler for the general community.
Because so few companies have the resources to train genuinely large-scale models in-house, the release is significant, according to Cerebras co-founder and Chief Software Architect Sean Lie. Often requiring hundreds or thousands of GPUs, “releasing seven fully trained GPT models into the open-source community illustrates exactly how efficient clusters of Cerebras CS-2 systems can be,” he stated.
A full suite of GPT models trained using cutting-edge efficiency methods, the business claims, has never before been made publicly available. It was stated that compared to other LLMs, they require less time to train, are cheaper, and consume less energy.
The company said that the Cerebras LLMs are suitable for academic and business applications because of their open-source nature. They also have several advantages, such as their training weights producing an extremely accurate pre-trained model that can be tuned for different tasks with relatively little additional data, making it possible for anyone to create a robust, generative AI application with little in the way of programming knowledge.
Traditional LLM training on GPUs necessitates a complicated mashup of pipeline, model, and data parallelism techniques; this release shows that a “simple, data-parallel only approach to training” can be just as effective. Cerebras, on the other hand, demonstrates how this may be accomplished with a simpler, data-parallel-only model that does not necessitate any changes to the original code or model to scale to very big datasets.
Training state-of-the-art language models is incredibly difficult since it requires a lot of resources, including a large computing budget, complex distributed computing methods, and extensive ML knowledge. Thus, only some institutions develop in-house LLMs (large language models). Even in the past few months, there has been a notable shift toward not open-sourcing the results by those with the necessary resources and skills. Researchers at Cerebras are committed to promoting open access to state-of-the-art models. In light of this, the Cerebras-GPT model family, consisting of seven models with anywhere from 111 million to 13 billion parameters, has now been released to the open-source community. The Chinchilla-trained models achieve the maximum accuracy within a specified computational budget. Compared to publicly available models, Cerebras-GPT trains more quickly, costs less, and uses less energy overall.
Check out the Cerebras Blog. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 17k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.