Check Out This Legal NLP Dataset Called ‘MAUD’ With Over 39,000+ Examples Released
Although large language models have made great strides in recent years, their ability to comprehend legal material still falls short of expectations. The length and intricacy of legal clauses make it difficult and laborious to understand the legal text. Furthermore, there are few expert-annotated legal datasets because curating them costs a fortune. These difficulties have had a significant impact on legal NLP research.
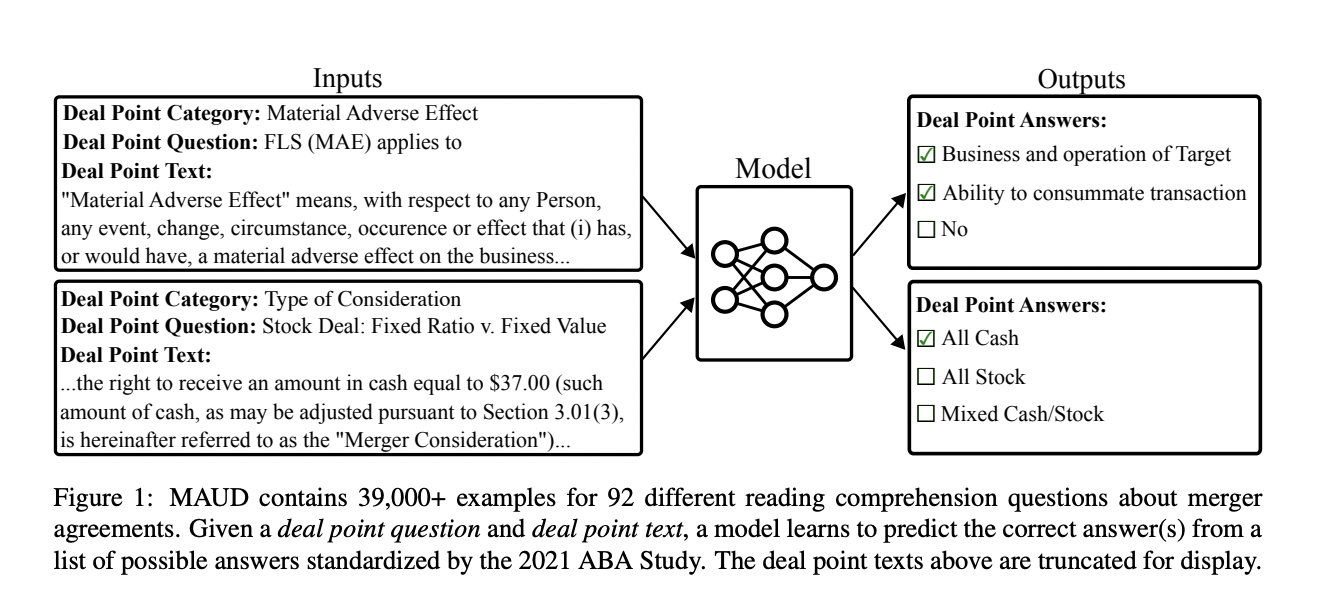
To address this issue, researchers from the top universities in the world, in collaboration with The Atticus Project, released the Merger Agreement Understand Dataset (MAUD), an expert-annotated dataset based on the American Bar Association’s 2021 Public Target Deal Points Study (ABA Study). The Atticus Project is a grassroots initiative led by seasoned attorneys in top in-house legal departments and law firms that aims at using artificial intelligence to revolutionize the legal industry. The corpus includes more than 47,000 manually annotated labels and 39,000 multiple-choice reading comprehension examples for 152 merger agreements.
Attorneys working on the ABA Study perform contract reviews on merger agreements. Typically, this contract review is a two-step process in which the attorneys first extract important legal elements from the contract before evaluating its intent (often referred to as a reading comprehension task). The lawyers extract deal points from merger agreements, and for each deal point, they respond to a series of standardized multiple-choice questions. Deal points refer to the key provisions in merger agreements that permit the acquisition of public target firms and specify the parties’ obligations concerning the acquisition.
Annotating the MAUD dataset was one of the activities that took the longest to complete. Several law students and seasoned attorneys worked together to create the final annotated dataset. Models trained on the MAUD dataset can answer 92 reading comprehension questions from the 2021 ABA Study. By responding to these inquiries, models classify the agreements made by the companies in the contract and understand the meaning of specific legal language.
Using the Transformers library, the team fine-tuned both single-task and multitask pretrained language models on MAUD. The major models whose performance was evaluated in the single-task context were the fine-tuned BERT-base, RoBERTa-base, and LegalBERTbase. RoBERTabase, LegalBERT-base, and DeBERTa-v3-base were assessed in the multitask setting. The area under the precision-recall curve (AUPR) was the main parameter employed by the researchers to evaluate their findings. According to their experimental evaluations, the fine-tuned models had high AUPR scores in several areas but had lower results in the three toughest categories.
In a nutshell, MAUD is a large reading comprehension dataset, carefully annotated by expert lawyers, that supports NLP research on specialized merger agreement review tasks. The team’s fine-tuned Transformers perform remarkably on some deal point categories, but there is still space for improvement for a large portion of the questions. But since MAUD is a one-of-a-kind dataset and the only dataset with expert annotations for merger agreements, researchers believe it can speed up research on specialized legal tasks like merger agreement review and serve as a baseline for evaluating NLP models for legal text understanding. Additionally, it may serve as an interesting research problem for NLP researchers who lack legal expertise. More details regarding the dataset can be found here.
Check out the Paper and Dataset. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
![]()
Asif Razzaq is the CEO of Marktechpost, LLC. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over a million monthly views, illustrating its popularity among audiences.
Credit: Source link
Comments are closed.