Check out this new Diffusion Probabilistic Model for Video Data that Provides a Unique Implicit Condition Paradigm for Modeling Continuous Spatial-Temporal Changing of Videos
Another day and another blog post about diffusion models. Diffusion models were probably one of the hottest, if not the hottest, topics in the AI domain in 2022, and we have seen amazing results. From text-to-image generation to guided image editing to video generation, we are closer to human-like generation models.
Before the diffusion model saga, image generation models, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), were quite popular due to their ability to generate new images from scratch. These models are able to learn the underlying probability distributions of image data and can generate new images that are similar to the training data.
These models could generate new images from scratch, but it was hard to control what the output looked like. Diffusion models were developed to fix that issue. These models allow you to manipulate specific features in the generated image and give you more control over the final result. It can be useful for things like image editing or generating new images that look similar to existing ones.
On the other hand, video generation models have become increasingly popular as they allow for the generation of new videos from scratch. These models also use techniques such as GANs and VAEs to learn the underlying probability distributions of video data and generate new videos that are similar to the training data. However, similar to image generation, controlling the output of video generation is difficult. Again, researchers have addressed this by using diffusion models, which allow for the manipulation of specific features in the generated video. This allows for more control over the final output and has many potential applications, such as video editing and synthesis.
Making sure the “conditioning mechanism” in diffusion models is done right is important to ensure the generated videos look good. It’s like a blueprint for creating the video. One can think of a real video as a combination of the content and the movement. If we can get the content part right, it’ll make the frames look super realistic. And if we get the movement part right, the video will look smooth and seamless. So, a top-notch video generation model should be able to capture both the movement and the content in a way that feels real.
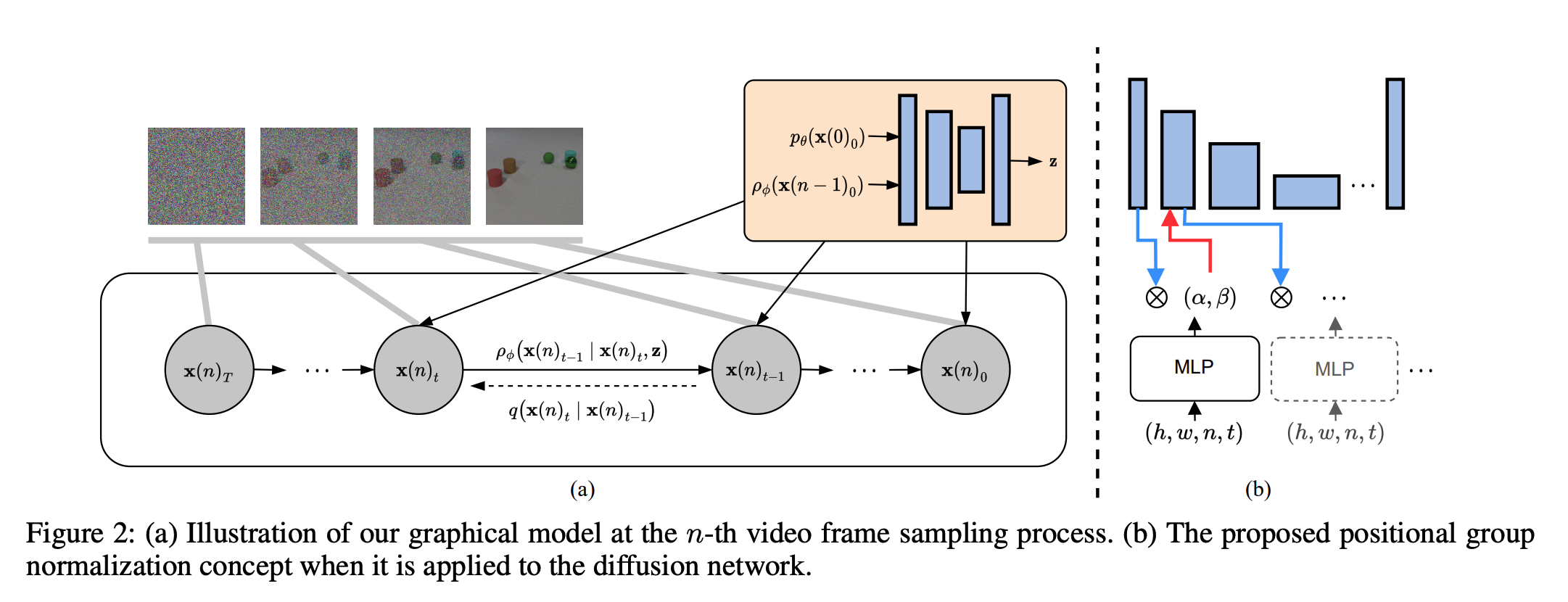
This was the motivation of VIDM authors, and they came up with brilliant execution. VIDM works as the following:
There are two different diffusion models to generate videos. The first one, the content generator, is used to generate the first frame. Then, the motion generator takes over and generates the next frame based on the first one and the previous frame. This way, the dynamics of the video can be modeled by looking at the “latent features” of the frames, and the model can represent the changes in the video over time and space. To generate the entire video, all that is needed is to keep repeating the process.
VIDM is a new way of generating videos that’s really unique. Instead of just using one big model, two smaller models that are responsible for different aspects are used to generate the video frame by frame. This way, the changes that happen in the video over time and space can be captured precisely.
Check out the Paper, Github, and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.