Check Out TorchOpt: An Efficient Library For Differentiable Optimization Built Upon PyTorch

Differentiable optimization-based algorithms, such as MAML, OptNet, and MGRL, have flourished recently. Meta-gradient, or the gradient term of outer-loop variables obtained by differentiating through the inner-loop optimization process, is one of the crucial components of differentiable optimization. Machine learning models can improve the sampling efficiency and the ultimate performance by utilizing meta-gradients. There are various difficulties in creating differentiable optimization algorithms. Before implementing algorithms with gradient flows on complex computational graphs, developers must realize different inner-loop optimization techniques.
Examples include Gumbel-Softmax to differentiate through discrete distribution, function interpolation for differentiable combinatorial solvers, explicit gradient computation of unrolled optimization, implicit gradient for differentiable optimization, evolutionary strategies for non-differentiable optimization, adjoint methods for differentiable ordinary differentiable equations, etc. Second, differentiable optimization requires a lot of computation. Large task-level batch sizes, high-dimensional linear equations, or extensive Hessian calculations are necessary for meta-gradient analysis. Such computing needs frequently need more power than a single CPU and GPU can offer. None of the differentiable optimization libraries currently available can fully enable the creation and execution of efficient algorithms.
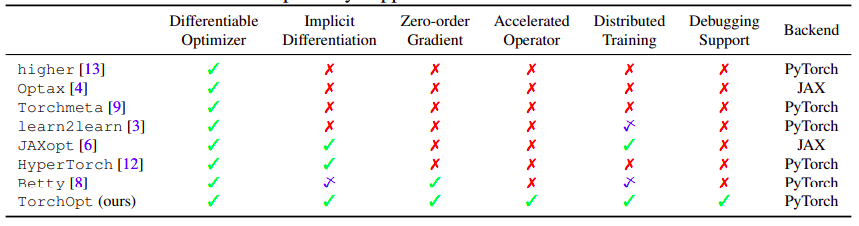
The majority of libraries focus on a small set of differentiable optimizers. As seen in the table below, they cannot wholly support implicit differentiation, zero-order gradient, and dispersed training. As a result, researchers are forced to create algorithms on-the-fly and according to the needs of each application, adding complexity and cost to the development process. Additionally, essential system optimization techniques (such as GPU optimization and distributed execution) are challenging to activate for all potential algorithms since they are intimately tied to some algorithms. TorchOpt is a PyTorch package that makes it possible to create and run differentiable optimization algorithms with multiple GPUs to address these issues.
The following contributions are made by the design and implementation of TorchOpt: (1) Unified and expressive differentiation mode for differentiable optimization To allow users to flexibly enable differentiable optimization within the computational networks created by PyTorch, TorchOpt offers a broad set of low-level, high-level, functional, and object-oriented (OO) APIs. TorchOpt offers explicit gradient for unrolled optimization, implicit gradient for differentiable optimization, and zero-order gradient estimation for non-smooth or differentiable functions as its three differentiation techniques for addressing differentiable optimization issues. (2) A runtime for distributed, high-performance execution. TorchOpt seeks to make CPUs and GPUs entirely usable through different optimization techniques.
To do this, they develop the following:
- CPU/GPU accelerated optimizers (e.g., SGD, RMSProp, Adam) that realize the fusion of small differentiable operators and fully offload these operators to GPUs.
- Parallel OpTree that can fully parallelize the nested structure flattening (Tree Operations), a crucial computation-intensive operation in differentiable optimization, on distributed CPUs.
- According to test findings, TorchOpt can cut the forward/backward time of the PyTorch optimizer by 5 to 10 on the CPU and 5 to 20 on GPU.
TorchOpt can cut the MAML algorithm’s training time in half by dividing the computation among 8 GPUs. Built upon PyTorch, the TorchOpt library is open source and readily available on GitHub and PyPi.
Check out the paper and code. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.