Checkmate with Scale: Google DeepMind’s Revolutionary Leap in Chess AI
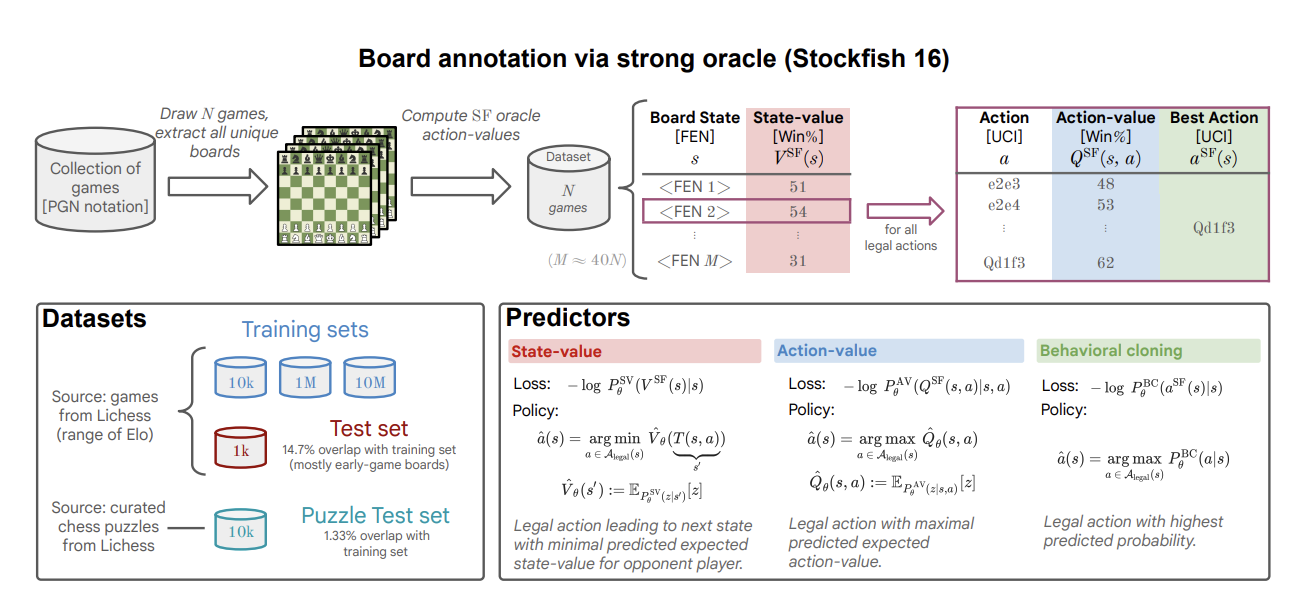
The intersection of artificial intelligence and the ancient game of chess has long captivated researchers, offering a fertile ground for testing the limits of computational strategy and intelligence. The journey from IBM’s Deep Blue, which in 1997 famously defeated the reigning world champion, to today’s highly sophisticated engines like Stockfish and AlphaZero underscores a continuous quest to refine and redefine machine intellect. These advancements have primarily been anchored in explicit search algorithms and intricate heuristics tailored to dissect and dominate the chessboard.
In an era where AI’s prowess is increasingly measured by its capacity to learn and adapt, a groundbreaking study shifts the narrative by harnessing the power of large-scale data and advanced neural architectures. This research by Google DeepMind revolves around a bold experiment: training a transformer model equipped with 270 million parameters, purely through supervised learning techniques, on an extensive dataset comprised of 10 million chess games. This model stands apart by not leaning on the conventional crutches of domain-specific adaptations or the explicit navigation of the decision tree that chess inherently represents.
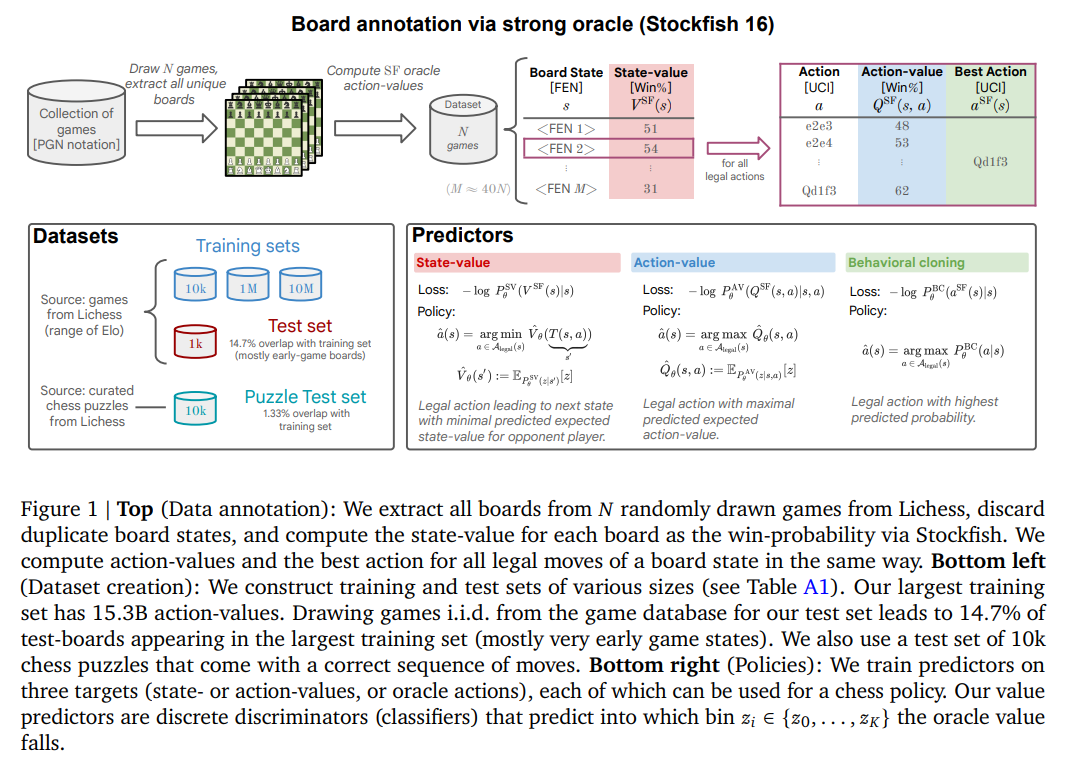
Rather than concocting a labyrinth of search paths and handcrafted heuristics, the model learns to predict the most advantageous moves directly from the positions on the chessboard. This methodological pivot is not just a departure from tradition but a testament to the transformative potential of large-scale attention-based learning. By annotating each game state with action values derived from the formidable Stockfish 16 engine, the research taps into a deep well of strategic insight, distilling this knowledge into a neural network capable of grandmaster-level decision-making.
The performance metrics of this transformer model are nothing short of revolutionary. Achieving a Lichess blitz Elo rating of 2895 not only sets a new benchmark in human-computer chess confrontations but also demonstrates a remarkable proficiency in solving intricate chess puzzles that have historically been the domain of the most advanced search-based engines. A comparative analysis with existing field giants further underscores this performance leap. The model not only outperforms the policy and value networks of AlphaZero. This program had itself redefined AI’s approach to chess through self-play and deep learning, but it also eclipses the capabilities of GPT-3.5-turbo-instruct in understanding and executing chess strategy.
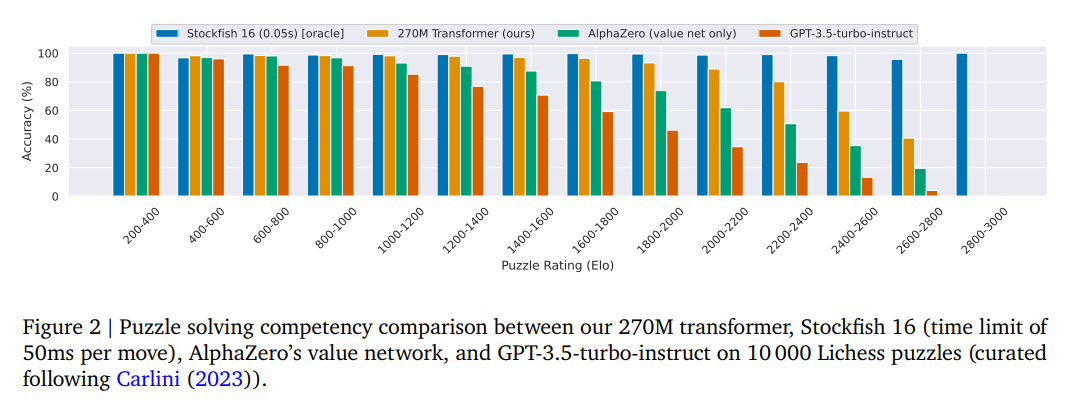
This paradigm-shifting success story is underpinned by meticulously examining the factors contributing to AI excellence in chess. The study delineates a direct correlation between the scale of the training data and the model’s effectiveness, revealing that the depth of strategic understanding and the ability to generalize across unseen board configurations only emerge at a certain magnitude of dataset and model complexity. This insight reinforces the significance of scale in AI’s conquest of intellectual domains and illustrates the nuanced balance between data diversity and computational heuristics.
In conclusion, this research not only redefines the boundaries of AI in chess but also illuminates a path forward for artificial intelligence. The key takeaways include:
- The feasibility of achieving grandmaster-level chess play without explicit search algorithms relying solely on the predictive power of transformer models trained on large-scale datasets.
- This demonstrates that the traditional reliance on complex heuristics and domain-specific adjustments can be bypassed, paving the way for more generalized and scalable approaches to AI problem-solving.
- The critical role of dataset and model size in unlocking the full potential of AI suggests a broader applicability of these findings beyond the chessboard.
These revelations propel further exploration into the capabilities of neural networks, suggesting that the future of AI may well lie in its ability to distill complex patterns and strategies from vast oceans of data across diverse domains without the need for explicitly programmed guidance.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.