Cleanlab Open-Sources ActiveLab: A Novel Active Learning Method For Data Labeling To Improve Machine Learning Models
Labeled data is essential for training supervised machine learning models, but mistakes made by data annotators can impact the model’s accuracy. It is common to collect multiple annotations per data point to reduce annotation errors to establish a more reliable consensus label, but this approach can be costly. To optimize the ML model with minimal data labeling, it is critical to determine which new data require labeling or which current labels need to be checked again.
ActiveLab, a recently published active learning method, has been made available as an open-source tool to help with this decision-making process. ActiveLab aids in identifying the data that require labeling or re-labeling to achieve maximum improvement in the ML model while adhering to a limited annotation budget. Training datasets generated using ActiveLab have produced superior ML models compared to other active learning techniques when working with a fixed number of annotations.
ActiveLab addresses the crucial inquiry of determining whether obtaining an additional annotation for a previously labeled data point is more advantageous or to label a completely new instance from the unlabeled pool. The response to this question hinges on the degree of confidence in the current annotations. In cases with only one annotation from an unreliable annotator or two annotations with conflicting results, obtaining another opinion through relabeling is crucial. This process becomes particularly significant when the negative consequences of training a model with mislabeled data cannot be remedied by merely labeling new data points from the unlabeled pool.
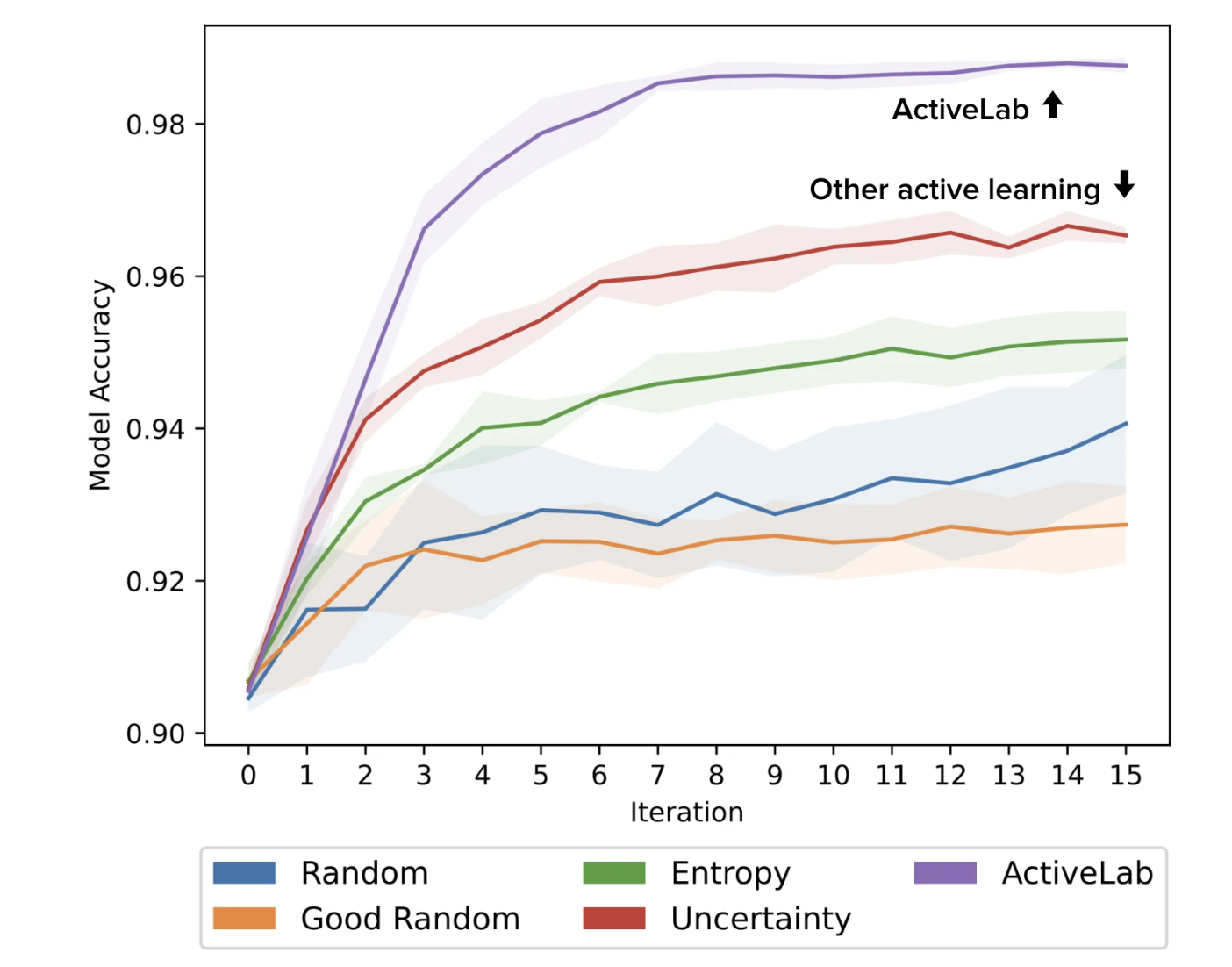
The researchers began with an initial training set of 500 labeled examples and trained a classifier model for multiple rounds, plotting its test accuracy after each iteration. Additional annotations for 100 examples were collected in each round, chosen from either this set of 500 or a separate pool of 1500 initially-unlabeled examples. Various active learning methods were used to decide which data to label/re-label next. Random selection was compared to Good Random, which prioritizes the unlabeled data first, as well as Entropy and Uncertainty, popular model-based active learning methods. ActiveLab was also used, which relies on model predictions to estimate how informative another label will be for each example while accounting for how many annotations an example has received so far and their agreement, as well as how trustworthy each annotator is overall relative to the trained model. Similar results were found for other models and image classification datasets, as detailed in the researchers’ paper on the development of this method.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.