CMU Researchers Introduce a Method for Estimating the Generalization Error of Black-Box Deep Neural Networks With Only Unlabeled Data

Take a look at the following fascinating observation. On two identically generated datasets S1 and S2 of the same size, train two networks of the same architecture to zero training error. Both networks would have a test error (or, to put it another way, a generalization gap) of about the same size, which is denoted by epsilon.
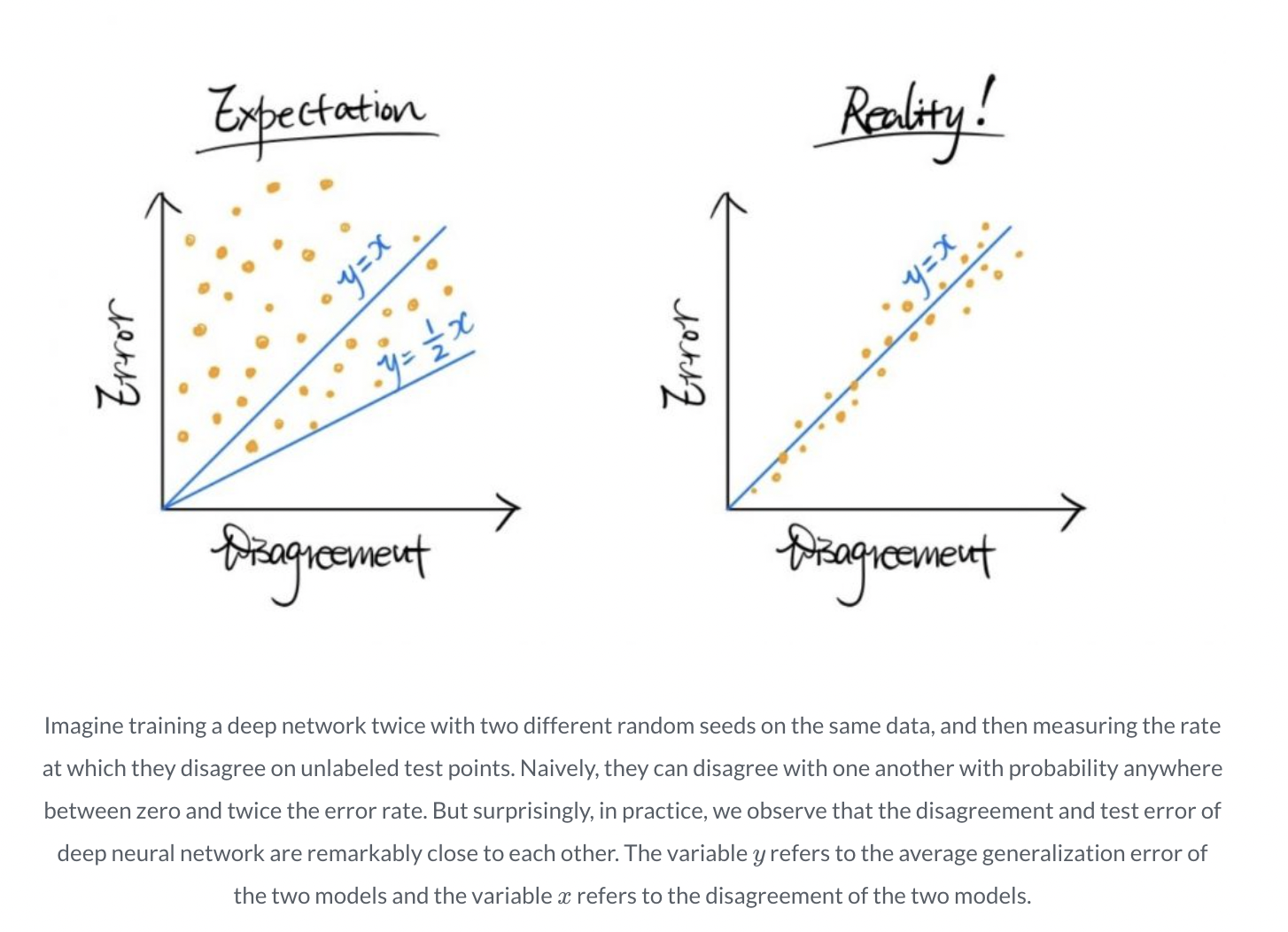
Measure the rate of disagreement of the predicted label between these two networks on a new unlabeled dataset U. This disagreement rate could be anything between 0 and 2 epsilon, based on a triangle inequality. However, studies show that the disagreement rate is not only linearly related to the test error but virtually equals it for various training set sizes and models such as neural networks, kernel SVMs, and decision trees.
What is the source of this unique equality? Solving this unsolved problem could lead to the discovery of basic patterns in how neural networks make mistakes. This could help researchers better understand generalization and other empirical phenomena in deep learning.
Researchers from Carnegie Mellon University identified a stronger observation first in a recent investigation. Consider two neural networks that were trained with the same hyperparameters and dataset but with different random seeds (for example, the data may be given in various random orders, and/or the network weights could be randomly initialized). Given that both models observe the same data, one would expect the percentage of disagreement to be substantially lower than in previous experiments.
However, the team finds that the disagreement rate is still roughly equivalent to the test error on the SVHN and CIFAR-10/100 datasets, as well as for variations of Residual Networks and Convolutional Networks, only slightly diverging from previous studies.
While studies show that the disagreement rate captures significant changes in test error with varying training set sizes, researchers point to a much more powerful behavior: the disagreement rate can capture even minute variations in test error when hyperparameters such as width and depth are varied. Furthermore, the researchers show that these qualities apply for various types of out-of-distribution data in the PACS dataset under appropriate training settings.
The preceding discoveries not only pose deeper philosophical concerns but also have a practical application. The disagreement rate, in particular, is a useful estimator of test accuracy because it does not require a new labeled dataset to calculate but only a new unlabeled dataset. Furthermore, unlike many other generalization measures that just correlate with the generalization gap or provide an unrealistically cautious upper bound, this clearly provides the team with a direct estimate of the generalization error without the need for correlation constants.
Furthermore, unlike these metrics, the estimator shows promise even when the distribution shifts in particular ways. The team gives a theoretical study of these observations in the second half of the work. Researchers demonstrate that if the ensemble of networks learned from different stochastic runs of the training algorithm (e.g., across different random seeds) is well-calibrated (i.e., the ensemble’s output probabilities are neither over-confident nor under-confident), then the disagreement rate equals the test error (in expectation over pairs of classifiers sampled from the stochastic algorithm). Indeed, such ensembles are well-known for being calibrated precisely in practice, and the research provides useful insight into the practical generalization features of deep networks.
Conclusion
Building on previous research, Carnegie Mellon University researchers discovered that two networks trained on the same dataset tend to differ nearly as much on unlabeled data as they do on the ground truth. They also show that this trait is due to the fact that SGD ensembles are well-calibrated theoretically. These findings, in general, help to further the greater goal of detecting and understanding empirical phenomena in deep learning.
Future research could reveal why diverse sources of stochasticity have a remarkably similar effect on calibration. This work may also inspire other unique approaches to estimate generalization from unlabeled data. The researchers also hope that these findings inspire further cross-pollination of ideas between generalization and calibration research.
Paper: https://arxiv.org/pdf/2106.13799.pdf
Reference: https://blog.ml.cmu.edu/2022/03/04/assessing-generalization-of-sgd-via-disagreement/
Suggested
Credit: Source link
Comments are closed.