CMU Researchers Introduce Internet Explorer: An AI Approach with Targeted Representation Learning on the Open Web
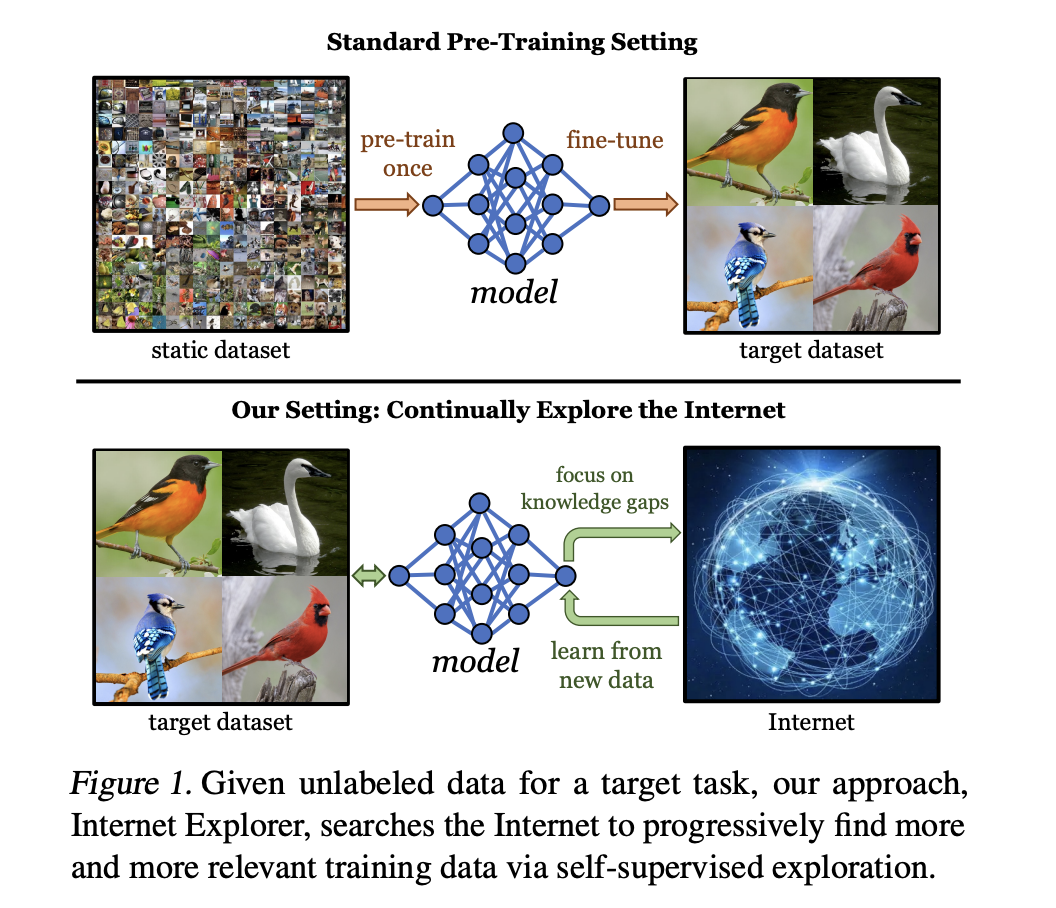
The most popular paradigm to solve modern vision tasks, such as image classification/object detection, etc., on small datasets involves fine-tuning the latest pre-trained deep network, which was previously ImageNet-based and is now likely CLIP-based. The current pipeline has been largely successful but still has some limitations.
Probably, the main concern regards the giant amount of effort needed to collect and label these large sets of images. Noticeably, the size of the most popular pretraining dataset has grown from 1.2M (ImageNet) to 400M (CLIP) and does not seem to stop. As a direct consequence, also training generalist networks require large computational efforts that nowadays only a few industrial or academic labs can afford. Another critical issue regarding such collected databases is their static nature. Indeed, despite being huge, these datasets are not updated. Hence, their expressive power regarding known concepts is limited in time.
Recent work from Carnegie Mellon University and Berkley University researchers proposes treating the Internet as a special dataset to overcome the previously mentioned issues of the current pre-training and fine-tuning paradigm.
In particular, the paper proposes a reinforcement learning-inspired, disembodied online agent called Internet Explorer that actively searches the Internet using standard search engines to find relevant visual data that improve feature quality on a target dataset.
The agent’s actions are text queries made to search engines, and the observations are the data obtained from the search.
The proposed approach is different from active learning and related work by performing an actively improving directed search in a fully self-supervised manner on an expanding dataset that requires no labels for training, even from the target dataset. In particular, the approach is not applied to a single dataset and does not require the intervention of expert labelers, as in standard active learning.
Practically, Internet Explorer uses WorNet concepts to query a search engine (e.g., Google Images) and embeds such concepts into a representation space to learn, through time, relevant query identification. The model leverages self-supervised learning to learn useful representations from the unlabeled images downloaded from the Internet. The initial vision encoder is a self-supervised pre-trained MoCoV3 model. The images downloaded from the internet are ranked according to the self-supervised loss to understand their similarity to the target dataset as a proxy for being relevant to training.
On five popular fine-grained and challenging benchmarks, i.e., Birdsnap, Flowers, Food101, Pets, and VOC2007, Internet Explorer (with the additional usage of GPT-generated descriptors for concepts) manages to rival a CLIP oracle ResNet 50 reducing the number of compute and training images by respectively one and two orders of magnitude.
To summarize, this paper presents a novel and smart agent that queries the web to download and learn helpful information to solve a given image classification task at a fraction of the training costs concerning previous approaches and opens up further research on the topic.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Lorenzo Brigato is a Postdoctoral Researcher at the ARTORG center, a research institution affiliated with the University of Bern, and is currently involved in the application of AI to health and nutrition. He holds a Ph.D. degree in Computer Science from the Sapienza University of Rome, Italy. His Ph.D. thesis focused on image classification problems with sample- and label-deficient data distributions.
Credit: Source link
Comments are closed.