CMU Researchers Introduce MultiModal Graph Learning (MMGL): A New Artificial Intelligence Framework for Capturing Information from Multiple Multimodal Neighbors with Relational Structures Among Them
Multimodal graph learning is a multidisciplinary field combining concepts from machine learning, graph theory, and data fusion to tackle complex problems involving diverse data sources and their interconnections. Multimodal graph learning can generate descriptive captions for images by combining visual data with textual information. It can improve the accuracy of retrieving relevant images or text documents based on queries. Multimodal graph learning is also used in autonomous vehicles to combine data from various sensors, such as cameras, LiDAR, radar, and GPS, to enhance perception and make informed driving decisions.
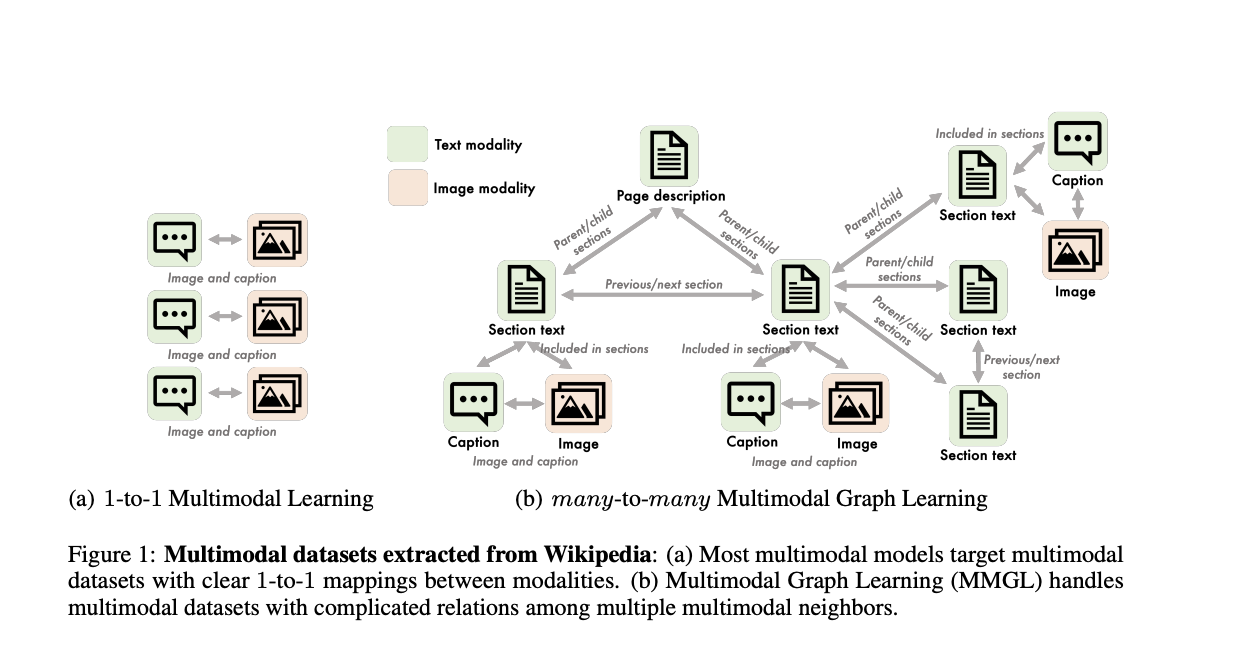
The present models depend upon generating images/text on given text/images using pre-trained image encoders and LMs. They use the method of pair modalities with a clear 1-to-1 mapping as an input. In the context of multimodal graph learning, modalities refer to distinct types or modes of data and information sources. Each modality represents a specific category or aspect of data and can take different forms. The problem arises when applying these models to many-to-many mappings among the modalities.
Researchers at Carnegie Mellon University propose a general and systematic framework of Multimodal graph learning for generative tasks. Their method involves capturing information from multiple multimodal neighbors with relational structures among themselves. They propose to represent the complex relationships as graphs to capture data with any number of modalities and complex relationships between modalities that can flexibly vary from one sample to another.
Their model extracts neighbor encodings and combines them with graph structure, followed by optimizing the model with parameter-efficient finetuning. To fully understand many-many mappings, the team studied neighbor encoding models like self-attention with text and embeddings, self-attention with only embeddings, and cross-attention with embeddings. They used Laplacian eigenvector position encoding(LPE) and graph neural network encoding (GNN) to compare the sequential position encodings.
Finetuning often requires substantial labeled data specific to the target task. If you already have a relevant dataset or can obtain it at a reasonable cost, finetuning can be cost-effective compared to training a model from scratch. Researchers use Prefix tuning and LoRA for Self-attention with text and embeddings(SA-TE) and Flamingo-style finetuning for cross-attention with embedding models(CA-E). They find that Prefix tuning uses nearly four times fewer parameters with SA-TE neighbor encoding, which decreases the cost.
Their research work is an in-depth analysis to lay the groundwork for future MMGL research and exploration in that field. The researchers say that the future scope of multimodal graph learning is promising and is expected to expand significantly, driven by advancements in machine learning, data collection, and the growing need to handle complex, multi-modal data in various applications.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.