CMU Researchers Introduce Sequoia: A Scalable, Robust, and Hardware-Aware Algorithm for Speculative Decoding
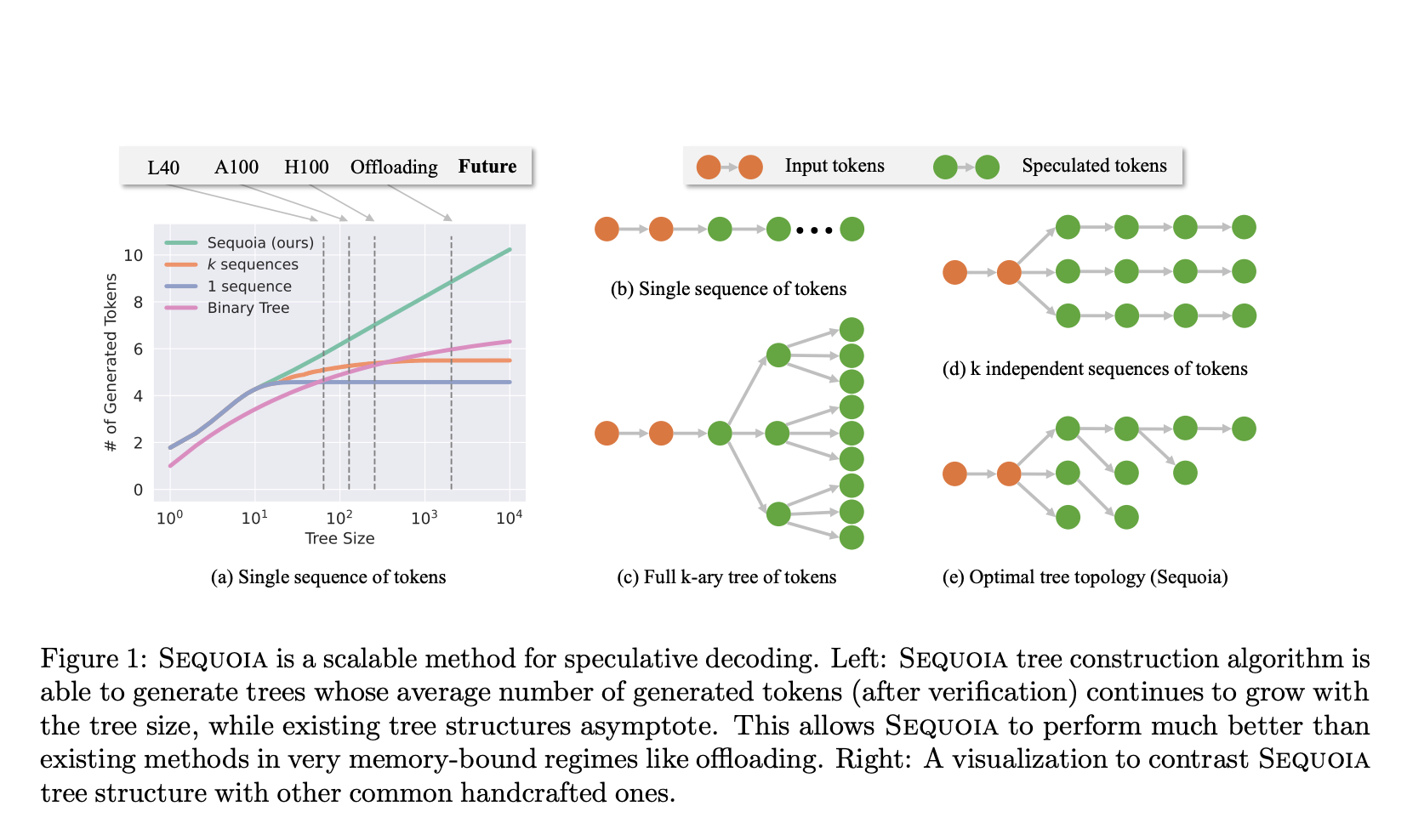
Efficiently supporting LLMs is becoming more critical as large language models (LLMs) become widely used. Since getting a new token involves getting all of the LLM’s parameters, speeding up LLM inference is difficult. The hardware is underutilized throughout generation due to this I/O constraint. Offloading-based inference and small-batch inference settings worsen this problem because, on current GPUs, producing a single token takes as long as processing a prompt containing hundreds or thousands of tokens.
Recent research has added speculative decoding to speed up LLM inference while keeping the LLM’s output distribution intact, which solves this difficulty. These approaches use one or more draft models to forecast the LLM’s output. The forecasts are structured in a token tree, with each node representing a different sequence of speculated tokens. Next, a single forward pass of the LLM is used to verify the correctness of these postulated tokens concurrently. The amount of tokens the LLM can accept can be increased using a token tree instead of a sequence, as there are multiple alternatives for each token position.
Researchers show that tree-based speculative decoding approaches have significant limitations even though there are extensive studies on the topic. To begin with, they find that the current algorithms for building token trees work fine for very small trees but fall short when faced with very big ones. Furthermore, it has been noted that current token tree sampling and verification algorithms do not work well when applied to different inference hyperparameter configurations. Finally, current systems fail miserably when optimizing the size and structure of their predicted trees, regardless of the hardware setup. For large hypothesized trees, the assumption that verification time is constant in existing models characterizing the speedup from speculative decoding does not hold, rendering these models useless for identifying the optimal tree dimensions.
Researchers from Carnegie Mellon University, Meta AI, Together AI, and Yandex frame tree building as a limited optimization issue and use a dynamic programming method to find the best speculative token tree. Token generation using this tree structure is shown to be unlimited and expand approximately logarithmically with tree size, both in theory and practice. According to the team, it’s important to develop a method for sampling and verifying trees that works well with different inference hyperparameters, doesn’t keep sampling the wrong tokens, and produces accurate results every time. To tackle this, they implement a sampling strategy that does not update the draft model. This prevents the draft model from making the same error twice and keeps the output distribution of the target model intact. This approach is based on the SpecInfer algorithm. They provide empirical evidence that this novel sampling and verification approach can achieve high acceptance rates in hot and cold environments.
The team further presents a hardware-aware tree optimizer that considers the hardware-dependent relationship between the number of verified tokens and the verification time. This optimizer then uses this relationship to determine the best tree form and depth, thereby addressing the final obstacle. Their findings show that the strategy outperforms methods not specific to hardware regarding speed.
They prove Sequoia’s efficacy with comprehensive end-to-end trials and ablation research. Their Sequoia implementation uses CUDA Graphs and is built on top of Hugging Face (and Accelerate). In the offloading mode on a L40 GPU, Sequoia can increase to 4.04× for Llama2-7B and 10.33× for Llama2-70B on a single A100 GPU. Additionally, ablation studies have shown that:
- The Sequoia tree structure is more scalable than k-independent sequences (tree size ≤ 512), generating up to 33% more tokens per decoding step.
- The Sequoia sampling and verification algorithm is temperature and top-p robust, providing speedups of up to 65% and 27%, respectively, compared to SpecInfer and top-k sampling and verification algorithms.
- The Sequoia hardware-aware tree optimizer can automatically determine the optimal tree size and depth of various hardware.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.