CMU Researchers Introduce Unlimiformer: An AI Method for Augmenting Pretrained Encoder-Decoders with an External Datastore to Allow for Unlimited Length Input
Transformer-based models have dominated the natural language processing (NLP) field since their introduction in 2017. Tokens for words, morphemes, punctuation, etc., are generated from the text input by the transformer. However, because transformers have to pay attention to every token in the input, their context windows need to be bigger to handle long-form jobs like book summaries, etc., where the number of tokens in the input might easily exceed a hundred thousand. To handle inputs of arbitrary length, a group of researchers from Carnegie Mellon University provides a broad strategy for enhancing model performance by supplementing pretrained encoder-decoder converters with an external datastore.
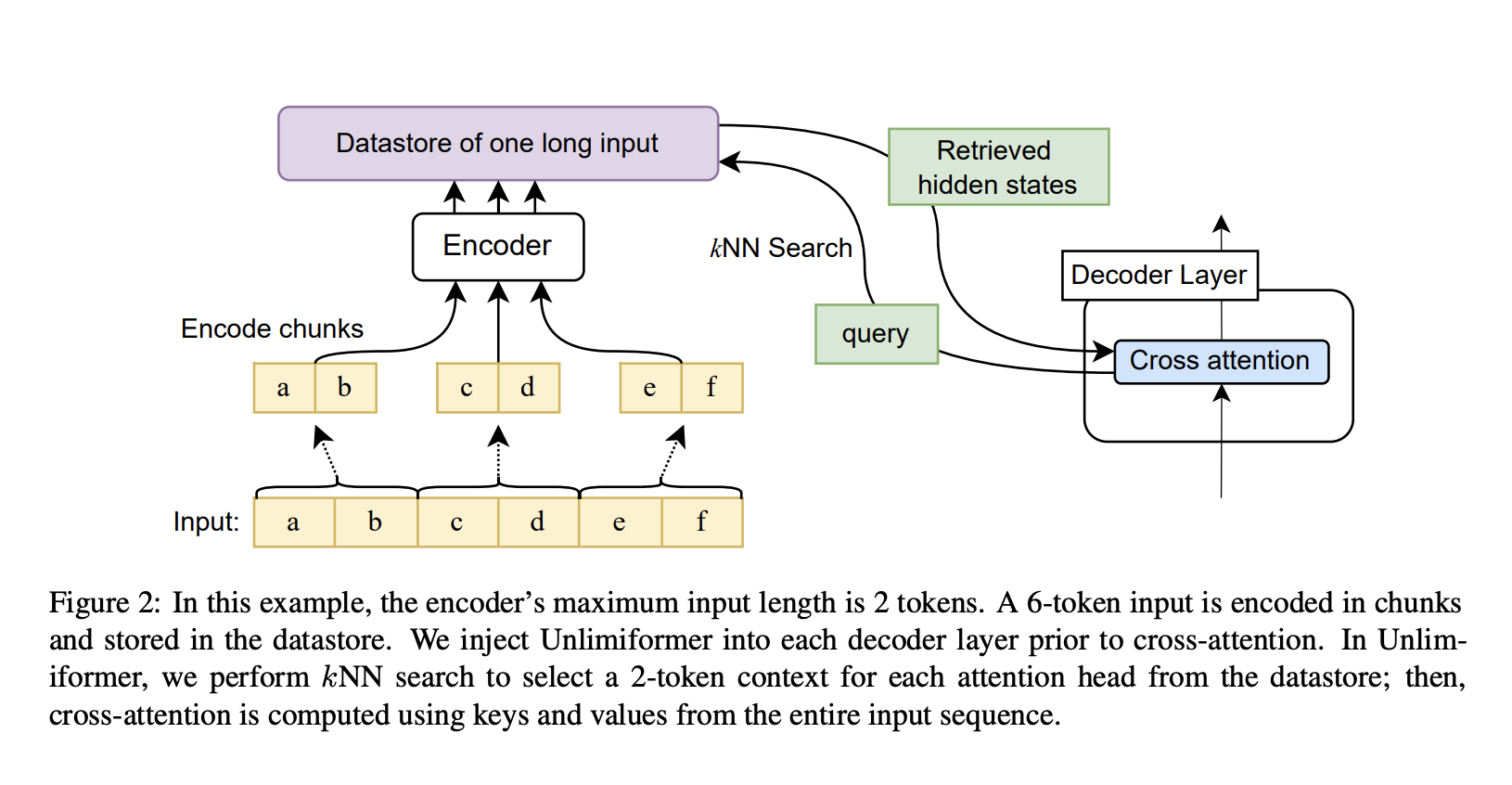
Unlimiformer is a new retrieval-based strategy that expands the input length tolerance of pretrained language models during testing. Any preexisting encoder-decoder transformer can be augmented with Unlimiformer to accept limitless inputs. Unlimiformer builds a datastore over the hidden states of all input tokens given a long input sequence. Next, the decoder uses its default cross attention to access the database and focus on the top k input tokens. The datastore supports sublinear searches and can be kept in GPU or CPU memory. A trained model can have its checkpoint enhanced by Unlimiformer without more training. Unlimiformer’s effectiveness can be further enhanced by tuning.
The maximum length of an input to a transformer is bounded by the size of the encoder’s context window. However, different information may be meaningful during decoding stages, and different attention centers may focus on multiple aspects of the data. As a result, a fixed context window may be inefficient since it focuses on tokens that an attention head needs to prioritize. At each decoding stage, Unlimiformer gives each head the option of selecting its unique context window from the entire input. To formalize this, we inject an Unlimiformer lookup into the decoder before applying cross-attention. This causes the model to conduct a k-nearest neighbor (kNN) search in an external datastore, selecting a set of tokens to focus on for each decoder layer and attention head.
To further boost Unlimiformer’s effectiveness, researchers are now focusing on training approaches. As a preliminary step, they consider alternative training methods that only demand less processing power than the conventional fine-tuning regime. They also investigate the computationally costly option of directly training the Unlimiformer.
The study’s code and models are available for download from GitHub.
Empirically, the team tested Unlimiformer on long-document and multi-document summarizing tasks, showing that it could summarize documents with as many as 350k tokens without truncating the inputs. Existing pretrained models were also fine-tuned using Unlimiformer, allowing them to handle unlimited inputs without needing any newly learned weights or alterations to the source code. Adding structure to the datastore or recovering embeddings in chunks, Unlimiformer may lead to further performance gains in retrieval-augmented big language models, which have shown encouraging results on downstream sequence-to-sequence generation tasks. Incorporating structure into the datastore or retrieving embeddings in chunks are two ways the researchers believe future work can boost speed. To further enhance the performance of retrieval-augmented LLMs on difficult downstream tasks, the information retrieval community has developed a wide array of approaches for improving retrieval. This is why the researchers behind the HuggingFace Transformers library have released a script that allows Unlimiformer to be injected into any model with a single click.
Check out the Paper and Github link. Don’t forget to join our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.