CMU Researchers Unveil An AI System for Human-like Text-to-Speech Training with Diverse Speech
Synthesizing human-level speech is essential to Artificial Intelligence (AI), notably in conversational bots. Recent developments in deep learning have significantly improved the quality of synthesized speech produced by neural-based Text-to-Speech (TTS) systems. However, reading or acting address recorded in a controlled context makes up most of the standard corpora used for training TTS systems. On the other hand, humans make a speech on demand with various prosodies that express paralinguistic information, such as subtle emotions. The exposure to many hours of speech from the actual world gives one this skill.
The limitless number of utterances in the wild can be used by systems that have been effectively trained on real-world speech. It implies that human-level AI is made possible by TTS systems introduced in the real-world lesson. In this study, they investigate the use of real-world speech gathered from YouTube and podcasts on TTS. Although the ultimate objective is to utilize an ASR system to record real-world speech, in this case, they simplify the environment by leveraging a corpus of already registered speech and concentrating on TTS. They thus think it should be able to reproduce the success of significant language models like GPT-3.
With few resources, these systems may be tailored to certain speaker characteristics or recording conditions. In this research, the authors address new difficulties encountered while training TTS systems on real-world speech, such as background noise and increased prosodic variance compared to reading speech recorded in controlled situations. They first show through real-world speech that mel-spectrogram-based autoregressive algorithms could not provide accurate text-audio alignment during inference, leading to garbled speech. The failure of inference alignment may thus be properly attributed to error buildup in the decoding process, as they also demonstrate that precise alignments can still be learned during training.
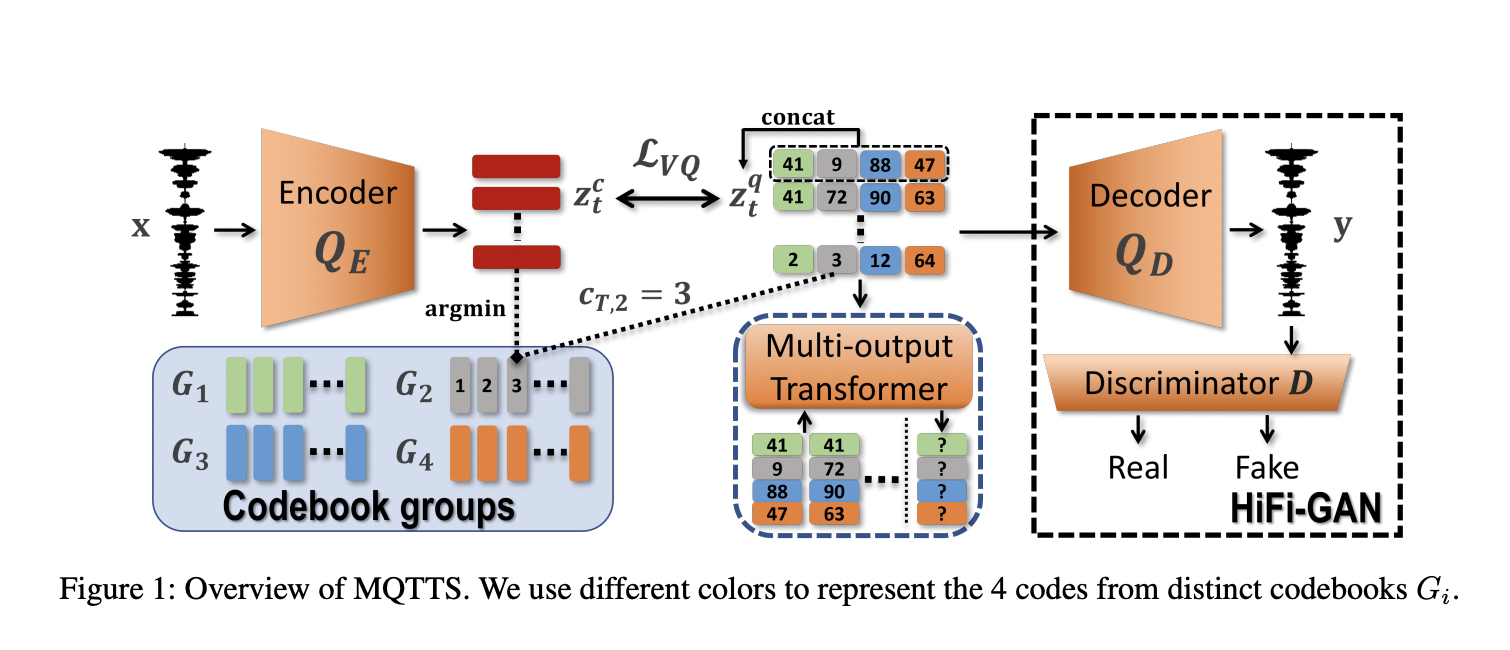
They discovered that this problem was solved by substituting learned discrete codebooks for the mel-spectrogram. They explain this by pointing to discrete representations’ superior resistance to input noise. However, their findings show that a single codebook results in skewed reconstruction for real-world speech even with greater codebook sizes. They speculate that there are too many prosody patterns in spontaneous speech for one codebook to handle. They use several codebooks to create particular architectures for multi-code sampling and monotonic alignment. They utilize a pure silence audio prompt during inference to encourage the model to produce pure speech despite training on a noisy corpus.
They introduced this technology called MQTTS (multi-codebook vector quantized TTS). To determine the characteristics required for real-world voice synthesis, they compare mel-spectrogram-based systems in Section 5 and undertake ablation analysis. They contrast MQTTS further with non-autoregressive methodology. They demonstrate that the intelligibility and speaker transferability of their autoregressive MQTTS are improved. MQTTS achieves a significantly better level of prosody variety and somewhat higher naturalness. However, non-autoregressive models outperform in terms of computing speed and resilience. Additionally, MQTTS may achieve a significantly lower signal-to-noise ratio with a clear, quiet cue (SNR). They publish their source code. The code implementation is made public on GitHub.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.