CoAuthor: A Human-AI Collaborative Writing Dataset For Improving Language Tools
Large language models (LMs) provide novel opportunities for interface design. Large language models have undoubtedly advanced to the point where they may be compared to a genuine writer. The models do an excellent job of comprehending the subject matter. Recent LMs (such as GPT-2 and GPT-3) can create a wide range of prose and conversations with unrivaled fluency. These models may be fine-tuned to become more skilled at specific activities, such as email composition or health consultations.
Language models may greatly assist humans in their writing processes. People have already begun to incorporate these technologies into their workflows, with some publications being created using these tools. Along these lines, Stanford researchers created CoAuthor: an interface, dataset, and experiment all in one.
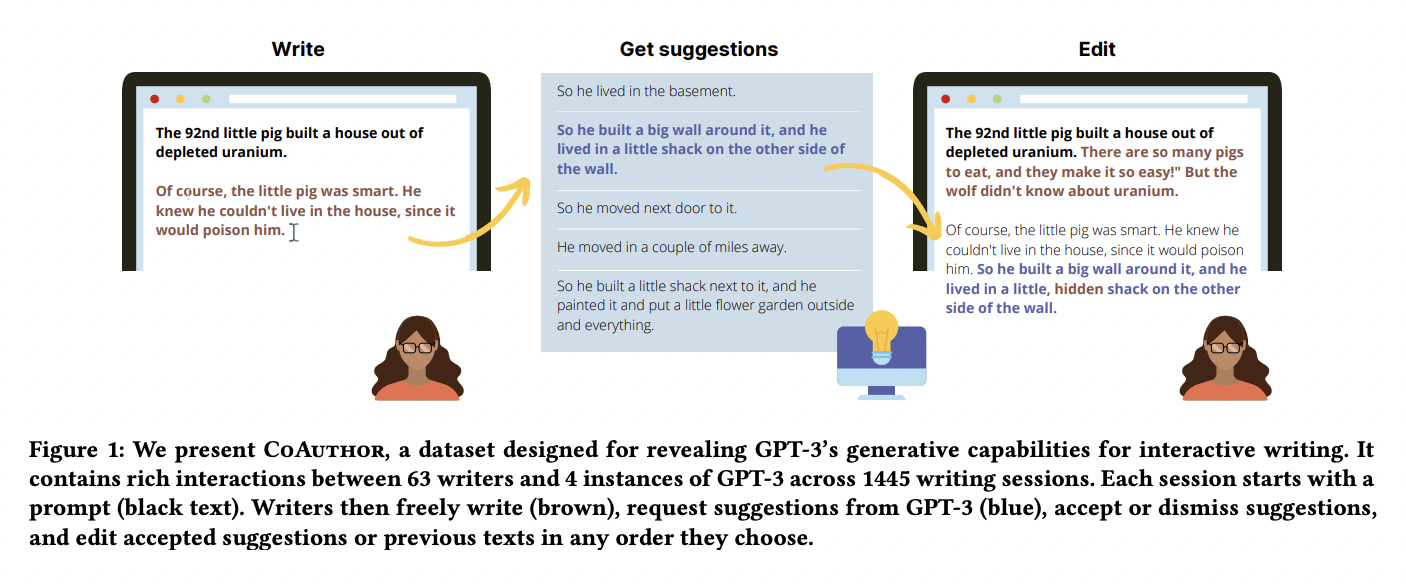
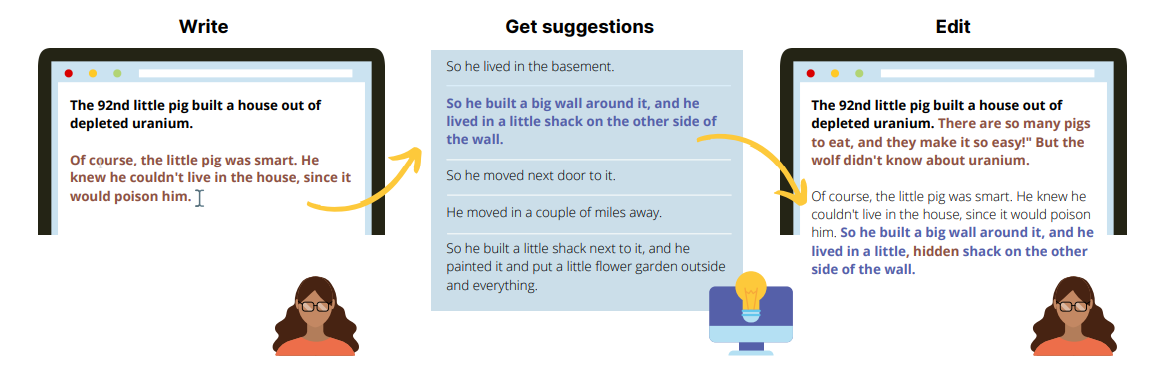
According to the researchers, these technologies work best when supplementing rather than replacing human writing. The objective was not to develop a system that could help users write better and quicker but rather to aid in the writing process and research the successes and failures of such systems. At the same time, users work, CoAuthor logs writing sessions key by key and create an extensive database. As the writer starts typing, he or she can press the “tab” key, and the system will provide five GPT-3-generated recommendations. The researchers employed over 60 people to generate over 1,440 stories and articles, each supported by CoAuthor.
The writer can then accept, amend, or reject the ideas depending on his or her sensibility. A survey followed each writing session to note the satisfaction of the writer. The writers stated that CoAuthor’s comments and ideas were frequently appreciated as novel and valuable. The ideas were sometimes ignored since they led the writer on an unexpected route. Moreover, they occasionally thought that the ideas were too repetitious or ambiguous, which did not add much value to their tales or essays.
Large language models were discovered to assist people in composing grammatically error-free content quickly and with a better vocabulary. The interface gives the authors a prompt (black text) and an example of GPT-3 during each session. They write (brown) ideas freely from GPT-3 (blue); now, they can either accept or reject the suggestions and alter the accepted suggestions or earlier texts in whichever sequence they desire. (see figure 1)
All interactions between the authors and the system were timestamped and recorded at the keystroke. This key-by-key replay helped designers investigate the same sessions from numerous viewpoints using this rich, complex, and fine-grained interaction dataset better to understand the productive potential of massive language models.
Some basic statistics of the data generated:
- Stories and essays: 418 words long
- Number of queries: 11.8 queries per writing session
- The acceptance rate of suggestions: 72.3%
- Percentage of text written by humans: 72.6%

The dataset, as well as an interface for repeating the writing sessions, are available to the public at https://coauthor.stanford.edu
In this paper, researchers identified a critical criterion for comprehending LMs’ generative capacities for interface design. They suggested that collecting and analyzing large interaction datasets is a viable technique since it may cover a wide variety of interaction situations and allow for diverse interpretations of outstanding collaboration. They expect that more researchers will contribute to the development of CoAuthor and its potential.
This Article Is Based On The Research Paper 'CoAuthor: Designing a Human-AI Collaborative Writing Dataset for Exploring Language Model Capabilities'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper, blog and project. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.