Cobra for Multimodal Language Learning: Efficient Multimodal Large Language Models (MLLM) with Linear Computational Complexity
Recent advancements in multimodal large language models (MLLM) have revolutionized various fields, leveraging the transformative capabilities of large-scale language models like ChatGPT. However, these models, primarily built on Transformer networks, suffer from quadratic computation complexity, hindering efficiency. Contrastingly, Language-Only Models (LLMs) are limited in adaptability due to their sole reliance on language interactions. Researchers are actively enhancing MLLMs by integrating multimodal processing capabilities to address this limitation. VLMs such as GPT-4, LLaMAadapter, and LLaVA augment LLMs with visual understanding, enabling them to tackle diverse tasks like Visual Question Answering (VQA) and captioning. Efforts are focused on optimizing VLMs by modifying base language model parameters while retaining the Transformer structure.
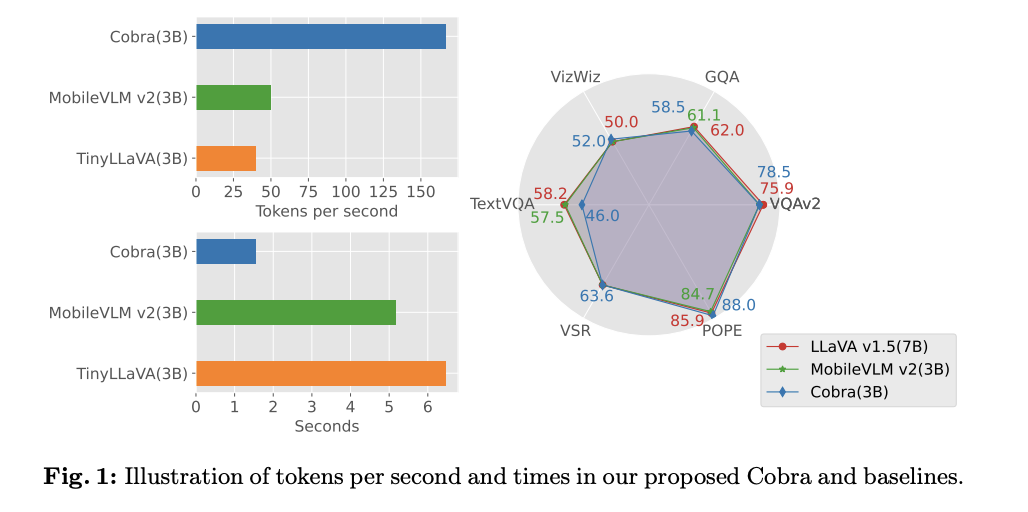
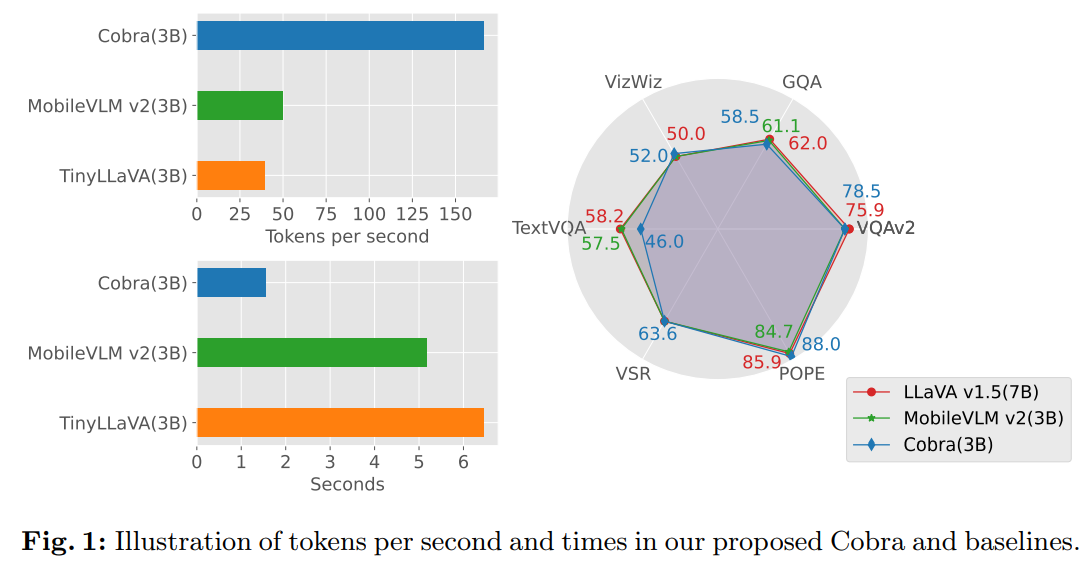
Researchers from Westlake University and Zhejiang University have developed Cobra, a MLLM with linear computational complexity. Cobra integrates the efficient Mamba language model into the visual modality, exploring various fusion schemes to optimize multimodal integration. Extensive experiments show that Cobra outperforms current computationally efficient methods like LLaVA-Phi and TinyLLaVA, boasting faster speed and competitive performance in challenging prediction benchmarks. Cobra performs similarly to LLaVA with significantly fewer parameters, indicating its efficiency. The researchers plan to release Cobra’s code as open-source to facilitate future research in addressing complexity issues in MLLMs.
LLMs have reshaped natural language processing, with models like GLM and LLaMA aiming to rival InstructGPT. While LLMs excel, efforts also focus on smaller alternatives like Stable LM and TinyLLaMA, proving comparable efficacy. VLMs, including GPT4V and Flamingo, extend LLMs to process visual data, often adapting Transformer backbones. However, their quadratic complexity limits scalability. Solutions like LLaVA-Phi and MobileVLM offer more efficient approaches. Vision Transformers like ViT and state space models like Mamba provide competitive alternatives, with Mamba exhibiting linear scalability and competitive performance compared to Transformers.
Cobra integrates Mamba’s selective state space model (SSM) with visual understanding. It features a vision encoder, a projector, and the Mamba backbone. The vision encoder merges DINOv2 and SigLIP representations for improved visual understanding. The projector aligns visual and textual features, employing either a multi-layer perceptron (MLP) or a lightweight downsample projector. The Mamba backbone, consisting of 64 identical blocks, processes the concatenated visual and textual embeddings, generating target token sequences. Training involves fine-tuning the entire backbone and projector over two epochs on a diverse dataset of images and dialogue data.
Cobra is thoroughly evaluated across six benchmarks in the experiments, showcasing its effectiveness in visual question-answering and spatial reasoning tasks. Results demonstrate Cobra’s competitive performance compared to both similar and larger-scale models. Cobra exhibits significantly faster inference speed than Transformer-based models, while ablation studies highlight the importance of design choices such as vision encoders and projectors. Case studies further illustrate Cobra’s superior understanding of spatial relationships and scene descriptions, underscoring its effectiveness in processing visual information and generating accurate natural language descriptions.

In conclusion, the study mentions Cobra as a solution to the efficiency challenges existing MLLMs employing Transformer networks face. By integrating language models with linear computational complexity and multimodal inputs, Cobra optimizes the fusion of visual and linguistic information within the Mamba language model. Through extensive experimentation, Cobra enhances computational efficiency and achieves competitive performance comparable to advanced models like LLaVA, particularly excelling in tasks involving visual hallucination mitigation and spatial relationship judgment. These advancements pave the way for deploying high-performance AI models in scenarios requiring real-time visual information processing, such as visual-based robotic feedback control systems.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.