Columbia University Researchers Introduce Zero-1-to-3: An Artificial Intelligence Framework for Changing the Camera Viewpoint of an Object Given Just a Single RGB Image
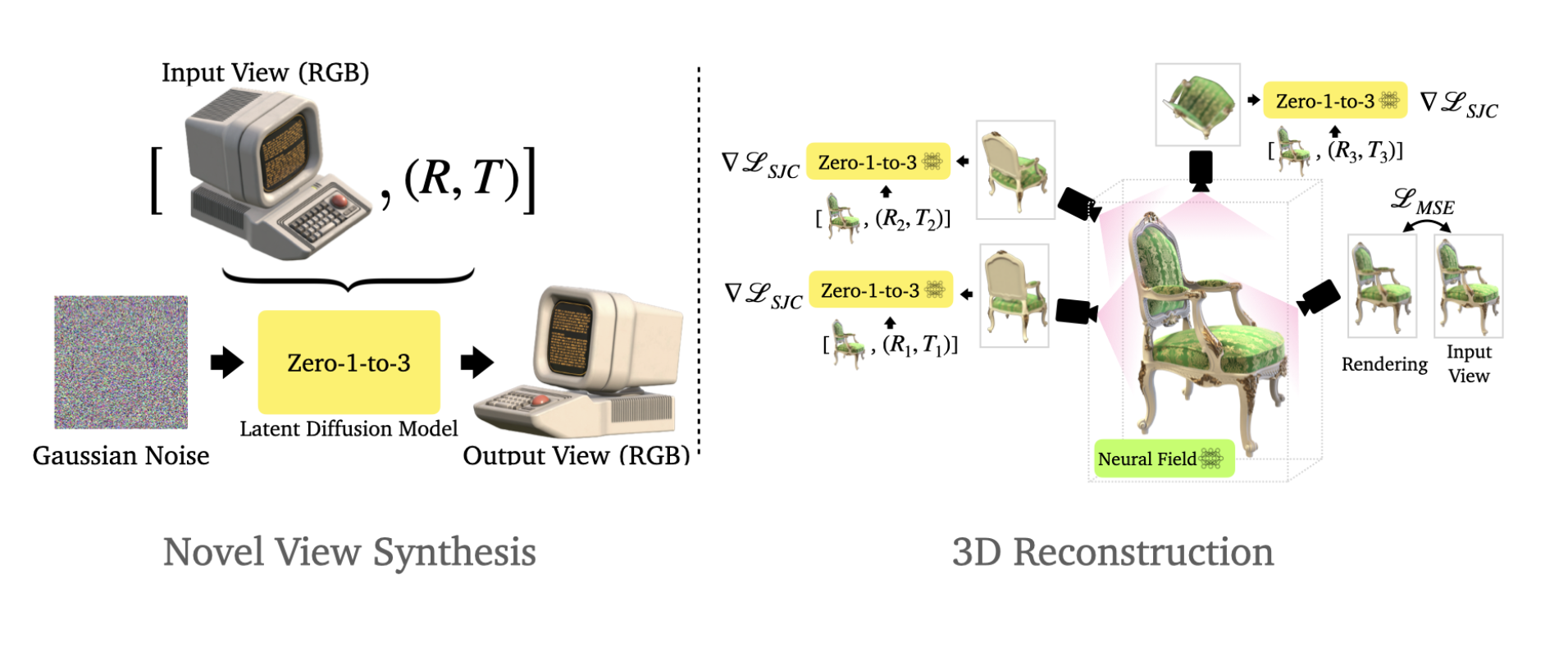
In the realm of computer vision, a persistent challenge has perplexed researchers: altering an object’s camera viewpoint with just a single RGB image. This complex problem has broad implications in augmented reality, robotics, and art restoration. Earlier approaches, relying on handcrafted features and geometric priors, struggled to deliver practical solutions. However, researchers at Columbia University have introduced the revolutionary Zero-1-to-3 framework. Leveraging deep learning and large-scale diffusion models, their framework uses learned geometric priors from synthetic data to manipulate camera viewpoints and also extends its capabilities to unconventional scenarios like impressionist paintings. It also excels in 3D reconstruction from a single image, outperforming state-of-the-art models.
In the rapidly evolving landscape of 3D generative models and single-view object reconstruction, recent breakthroughs have been powered by advancements in generative image architectures and the availability of extensive image-text datasets. These strides have enabled the synthesis of intricate scenes and objects using diffusion models, renowned for their scalability and efficiency in image generation. Traditionally, the transition of these models into the 3D domain necessitated abundant marked 3D data, a resource-intensive endeavor. However, recent approaches have circumvented this need by transferring pre-trained large-scale 2D diffusion models into the 3D realm, effectively sidestepping the requirement for ground truth 3D data.
Researchers proposed the Zero-1-to-3 framework, which tackles the problem of altering the camera viewpoint of an object using only a single RGB image. Their approach hinges on a conditional diffusion model trained on synthetic data, which empowers it to grasp the controls governing the relative camera viewpoint. With this newfound capability, the framework can generate novel images, faithfully capturing the desired camera transformations. Impressively, the model exhibits robust zero-shot generalisation skills, effortlessly extending its proficiency to previously unencountered datasets and real-world images. Furthermore, the framework’s utility extends to the realm of 3D reconstruction from a solitary image, where it excels beyond contemporary models, marking a significant advancement in single-view 3D reconstruction and novel view synthesis.
The inherent limitations of large-scale generative models, such as the absence of explicit encoding of correspondences between viewpoints and the influence of viewpoint biases gleaned from the vast expanse of the Internet, remain hurdles to overcome. However, these challenges are met with innovative solutions and methodologies, propelling the Zero-1-to-3 framework to the forefront of computer vision advancements.
Their method redefines the paradigm of altering camera viewpoints with just a single RGB image. Their approach outperforms not only contemporary models in single-view 3D reconstruction but also novel view synthesis. The results showcase the generation of highly photorealistic images that closely mirror ground truth. Their method excels in synthesizing high-fidelity viewpoints while preserving object type, identity, and intricate details. Moreover, it stands out in producing a diverse array of plausible images from novel vantage points, effectively encapsulating the inherent uncertainty of the task.
Their approach surpasses existing single-view 3D reconstruction and novel view synthesis models by harnessing the power of very large-scale pre-training. Their method represents a significant leap forward in single-view 3D reconstruction and novel view synthesis, offering a powerful tool for generating fresh perspectives of objects from varying camera viewpoints with unparalleled effectiveness.
Check out the Paper, Code, and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.