Common Probability Distributions: Road Towards Data Science


Probability is concerned with interpreting and comprehending life’s random events. Randomness and uncertainty are present in our everyday lives and every field of research, engineering, and technology. We utilize the idea of probability everywhere, from evaluating the likelihood that a certain financial asset will fall within a specific range to predicting the weather.
Probability is the long-term likelihood of a specific outcome from a random process. However, it doesn’t have a fixed value but rather a range of possibilities. A probability of an event occurring is a number that spans from 0 to 1 in numerical terms. The higher the probability value, the more probable the event will occur. All of these conceivable outcomes add up to one.
A probability distribution is a collection of all the possible outcomes of a random variable and the probability values that correspond to them. Each random variable or process result is linked to its likelihood of occurrence via a probability distribution.
While estimating the probability distribution of a random variable, the user data only represents a small portion of the true behavior of the random variable in question. This limits us from getting a picture of all data values, and we end up analyzing a subset of the dataset at a specific point in time and space.
Because the value of random variable changes depending on the context in which it is analyzed, it is important to take a subset of data each time while calculating the probability of that outcome. In addition, even if the analysis is repeated in the future, the results might be different as analysis is done under specific conditions.
Probability distributions models assist in predicting outcomes in specific situations. These probability distributions models help calculate each outcome probability, the long-term average outcomes and estimate the variability in the results of random variables when certain conditions are met, without the need to have all of the actual outcomes of the random variables of interest.
Some of the widely adopted probability distributions are discussed below:
Bernoulli Distribution
The Bernoulli distribution is the most basic discrete distribution, and it serves as a foundation for more complex discrete distributions.
Consider tossing a coin; the chance of receiving heads (a “success”) is 0.5, and there is no middle ground. There are just two possible outcomes in a Bernoulli distribution: 1 (success) and 0 (failure), as well as a single trial. So the Bernoulli random variable X can have a value of 1 for the probability of success, say p, and a value of 0 for the likelihood of failure, say q or 1-p.
The outcomes of other trials have no bearing on the probabilities, implying that the trials are independent.
The probability distribution function (PDF) of a Bernoulli distribution is given as:
px(1-p)1-x where x € (0, 1).
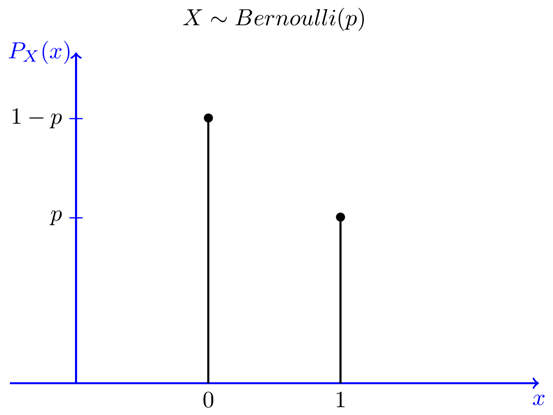
A specific event A is associated with a Bernoulli random variable. If event A occurs (for example, if you pass the test), X equals one; otherwise, X equals zero. The Bernoulli random variable is sometimes known as the random indicator variable.
The expected value of a random value (X) can be calculated from a Bernoulli distribution as follows:
E(X) = 1*p + 0*(1-p) = p
The variance of a random variable (X) can be calculated from a Bernoulli distribution as follows:
Var(X) = E(X²) – [E(X)]² = p – p² = p(1-p)
In real-life settings, it’s necessary to keep track of whether or not a given occurrence occurred. The outcome of such events is documented as a success or failure. E.g., calculating the likelihood of a medical treatment’s successor transmitting the disease is two instances of binary outcome scenarios.
Uniform Distribution
Imagine a distribution with many equally likely outcomes: the uniform distribution, distinguished by its flat PDF—the outcomes of a fair dice roll range from 1 to 6. The chances of acquiring these outcomes are equal, which is the foundation of a uniform distribution. A uniform distribution, unlike the Bernoulli distribution, has a number of alternative outcomes that are all equally likely.
The PMF of a random variable X following uniform distribution is:

a and b are parameters for uniform distribution
The expected value of a random variable (X) is given as the following:
E(X) = (a+b)/2
The variance of the random variable (X) is:
V(X) = (b-a)²/12
Uniform distribution is also sometimes known as rectangular distribution.
Binomial Distribution
Assume winning the coin toss today implies a successful event. You toss a coin today and win but lose the next time you toss. This simply means that winning today doesn’t guarantee the result for tomorrow. There are only two outcomes that can occur. The head represents success, whereas the tail represents failure. As a result, the likelihood of getting ahead equals 0.5, while the probability of failure equals q = 1- p = 0.5.
Because the outcome of the prior toss has no bearing on or influence on the outcome of the current toss, each trial is independent. Binomial experimentation is defined as an experiment with only two possible results that is repeated n times. The distribution involves two parameters: n and p, where n is the total number of trials and p is the likelihood of each trial succeeding.
The probability distribution function (PDF) is given as:

The expected value of a random value (X) can be calculated from a binomial distribution as follows:
E(X) = n*p
The variance of the random variable (X) is:
Var(X) = n*p*q
The binomial distribution is used in many real-life scenarios. For example, email firms use the binomial distribution to estimate the probability of receiving a given number of spam emails per day. Consider the case when it is known that 4% of all emails are spam. Firms may use a Binomial Distribution Calculator to find the likelihood that a particular number of those emails are spam if an account receives 20 emails in a given day and so on.
Poisson Distribution
The Poisson distribution, like the binomial distribution, is a count distribution – the number of times something happened. It’s parameterized by an average rate, which in this comparison is just the constant value of np, rather than a probability p and number of trials n. When trying to count events over time with a constant rate of occurrence, the Poisson distribution is considered.
As per statistics, when the following assumptions are true, a distribution is termed a Poisson distribution:
1. The outcome of one successful event should not be influenced by the outcome of a subsequent successful event.
2. The chance of success over a short time interval must be the same as the chance of success over a longer time interval.
3. As the interval gets smaller, the likelihood of success in that interval approaches zero.
The Poisson distribution comes in handy in many real-life settings. Consider the number of customers who call a customer service every minute, assuming each second as a Bernoulli trial where a client doesn’t call (0) or does (1). But when the power goes out, the power company knows that two or even hundreds of people can phone simultaneously. Seeing it as 60,000-millisecond trials still doesn’t solve the problem – there are many more trials, and the likelihood of one call, let alone two or more, is considerably lower, but it’s still not a Bernoulli trial. Logically, taking this to its infinite, as if you’re heading towards an infinite number of infinitesimally short time slices where the chance of getting a call is infinitesimal. The Poisson distribution is the limiting result. To keep n*p the same, let n go to infinity and p go to 0 to match.
The PMF of a random variable X following a Poisson distribution is given by:

The expected value of a random value (X) can be calculated from a binomial distribution as follows:
E(X) = µ
The variance of a random variable (X) is given as:
Var(X) = µ
Geometric Distribution
In a series of Bernoulli trials, the geometric distribution reflects the number of failures until you achieve success. For example, how many times does a flipped coin land on its tails before landing on its head? The number of tails in this count follows a geometric distribution. Similar to Bernoulli distribution, it’s parameterized by the probability of that final success. Because the number of failed trials represents the outcome, it is not parameterized by n, a number of trials, or flips.
The PMF of X following a Geometric distribution is given by:

The expected value of a random value (X) can be calculated from a Geometric distribution as follows:
E(X) = 1/p
The variance of a random variable (X) from a Geometric distribution can be given as:
Var(X) = (1-p)/p2
The geometric distribution is useful for predicting the probability of success given a finite number of trials, which is very useful in the real world because unlimited (and unrestricted) trials are uncommon. For instance, in cost-benefit evaluations for selecting whether to fund research trials that, if successful, will yield the company some expected profit.
Exponential Distribution
The exponential distribution is a continuous distribution commonly used to estimate the time passed between events, such as the length of time between metro arrivals.
The PDF A random variable X is said to have an exponential distribution with PDF:
f(x) = λe-λx, where x ≥ 0 and parameter λ>0 which is also called the rate.
For survival analysis, the exponential distribution is commonly utilized.
The expected value of a random value (X) can be calculated from an exponential distribution as follows:
E(X) = (1/λ)
The variance of a random variable (X) can be calculated from an exponential distribution as:
Var(X) = (1/λ)2
In addition, the faster the rate declines, the faster the curve drops, and the slower the rate drops, the flatter the curve becomes.
Normal Distribution
The behavior of most circumstances in the universe is represented by the normal distribution. The most frequent distribution function for independent, randomly produced variables is the Gaussian distribution, often known as the Gaussian distribution. The big sum of (small) random variables is frequently normally distributed, contributing to its common use. If a distribution has the following features, it is called a normal distribution.
- The distribution’s mean, median, and mode are all the same.
- The distribution’s curve is bell-shaped and symmetrical around line x.
- The area under the curve is totaled at 1.
The PMF of a random variable X following a Normal distribution is given by:

The expected value of a random value (X) can be calculated from a normal distribution as follows:
E(X) = µ
The variance of a random variable (X) from a normal distribution is given as:
Var(X) = σ2
The normal distribution is the binomial distribution are significantly different. However, as the number of trials grows larger, the shapes become increasingly similar. The standard normal distribution has an expected value of 0 and a standard deviation of 1.
References:
- https://www.analyticsvidhya.com/blog/2017/09/6-probability-distributions-data-science/
- https://medium.com/@srowen/common-probability-distributions-347e6b945ce4
Suggested

Credit: Source link
Comments are closed.