Cornell Researchers Unveil MambaByte: A Game-Changing Language Model Outperforming MegaByte
The evolution of language models is a critical component in the dynamic field of natural language processing. These models, essential for emulating human-like text comprehension and generation, are instrumental in various applications, from translation to conversational interfaces. The core challenge tackled in this area is refining model efficiency, particularly in managing lengthy data sequences. Traditional models, especially at the byte level, have historically struggled with this aspect, impacting their text processing and generation capabilities.
Now, models have typically employed subword or character-level tokenization, breaking down text into smaller, more manageable fragments. While useful, these techniques have their own set of limitations. They often need to improve in efficiently processing extensive sequences and more flexibility across linguistic and morphological structures.
Meet MambaByte, a groundbreaking byte-level language model developed by Cornell University researchers that revolutionizes this approach. It derives from the Mamba architecture, a state space model specifically tailored for sequence modeling. Its most striking feature is its operation directly on byte sequences, eliminating the need for traditional tokenization.
MambaByte truly stands out in its methodology. It harnesses the linear-time capabilities inherent in the Mamba architecture, enabling effective management of lengthy byte sequences. This innovative approach significantly reduces computational demands compared to conventional models, boosting efficiency and practicality for extensive language modeling tasks.
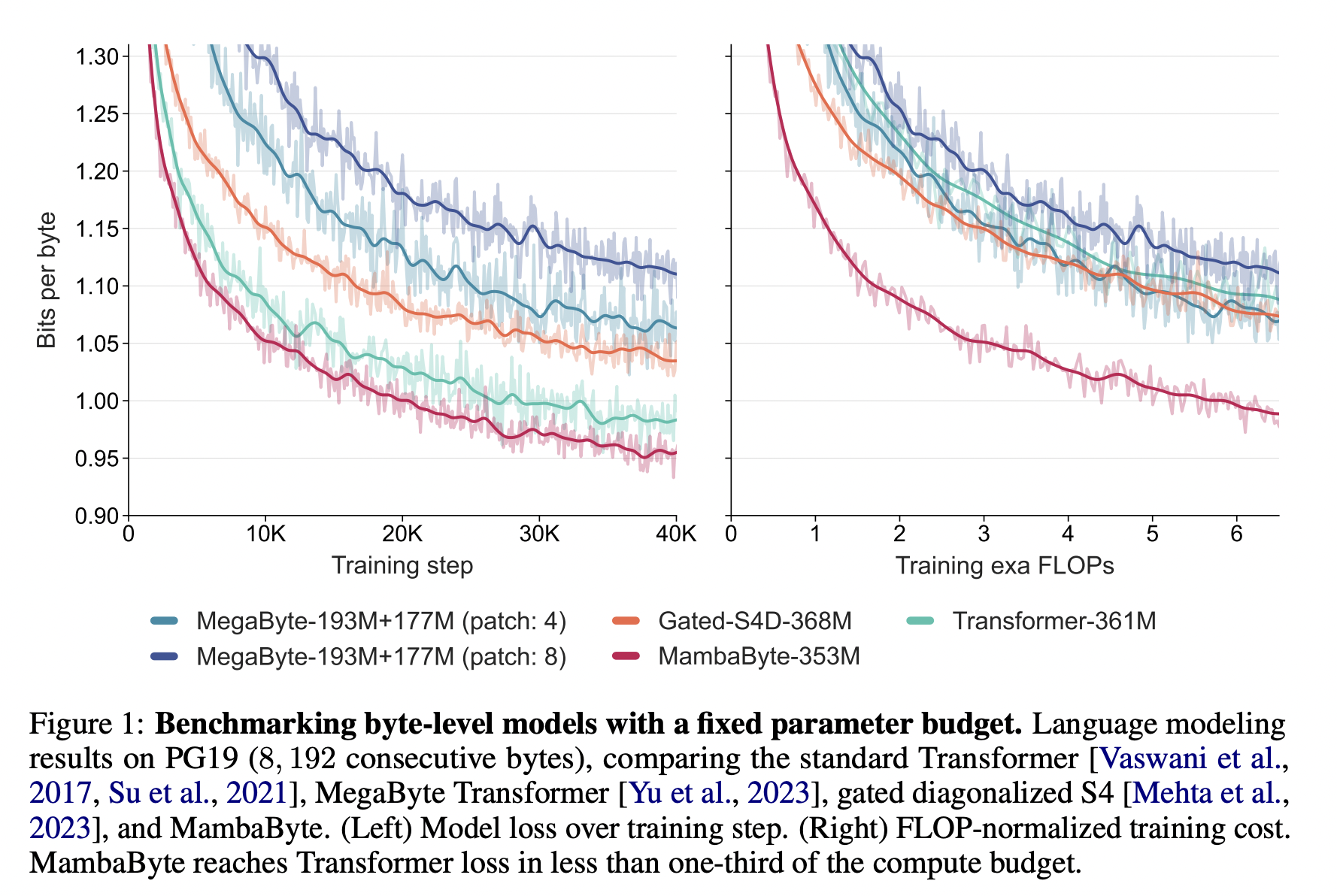
The performance of MambaByte is quite remarkable. MambaByte outperformed MegaByte consistently across all datasets. Furthermore, MambaByte couldn’t be trained for the full 80B bytes due to monetary constraints, but MambaByte beat MegaByte with 0.63× less compute and training data. Additionally, MambaByte-353M also exceeds byte-level Transformer and PerceiverAR. The results highlight MambaByte’s superior efficiency performance and its ability to achieve better results with less computational resources and training data compared to other leading models in the field.
Reflecting on MambaByte’s contributions, it’s clear that this model signifies a breakthrough in language modeling. Its proficiency in processing long-byte sequences without resorting to tokenization paves the way for more adaptable and potent natural language processing tools. The results hint at an exciting future where token-free language modeling could be pivotal in large-scale applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.