Crisper, Clearer, and Faster: Real-Time Super-Resolution with a Recurrent Bottleneck Mixer Network (ReBotNet)
Videos have become omnipresent, from streaming our favorite movies and TV shows to participating in video conferences and calls. With the increasing use of smartphones and other capture devices, the quality of videos has risen in importance. However, due to various factors like low light, digital noise, or simply low acquisition quality, the quality of videos captured by these devices is often far from perfect. In these situations, video enhancement techniques come into play, aiming to improve resolution and visual features.
Over the years, various video enhancement techniques have been developed until the arrival of complex machine learning algorithms to remove noise and improve image quality. One of the most promising video enhancement technologies is neural networks. They recently have emerged as a powerful tool for video enhancement, allowing for unprecedented levels of clarity and detail in videos.
Among the most exciting applications of neural networks in video enhancement exist super-resolution, which involves increasing the resolution of a video to provide a clearer and more detailed image, and denoising, which aims to turn blurry areas into distinguished features. With the help of neural networks, these tasks have become a reality.
However, the complexity of these video enhancement tasks poses several challenges in real-time applications. For instance, several recent techniques, like diffusion models, involve multiple resource-intense steps to generate an image out of pure noise. For diffusion models, the denoising steps alone require a powerful GPU.
With this challenge in mind, a novel neural network framework called ReBotNet has been developed. An overview of the proposed system is available in the figure below.

The network takes in the frame that needs improvement and the previously predicted frame as input. The method’s uniqueness lies in its design, which employs convolutional and MLP-based blocks to avoid the high computational complexity associated with traditional attention mechanisms while maintaining good performance.
The authors tokenize the input frames in two ways to enable the network to learn both spatial and temporal features. Each set of tokens is passed through separate mixer layers to determine the dependencies between them. The enhanced frame is predicted using a straightforward decoder based on these tokens. The method also uses temporal redundancy in real-world videos to enhance efficiency and temporal consistency. To achieve this, a frame-recurrent training setup is utilized where the previous prediction is used as an additional input to the network, allowing for the propagation of information to future frames.
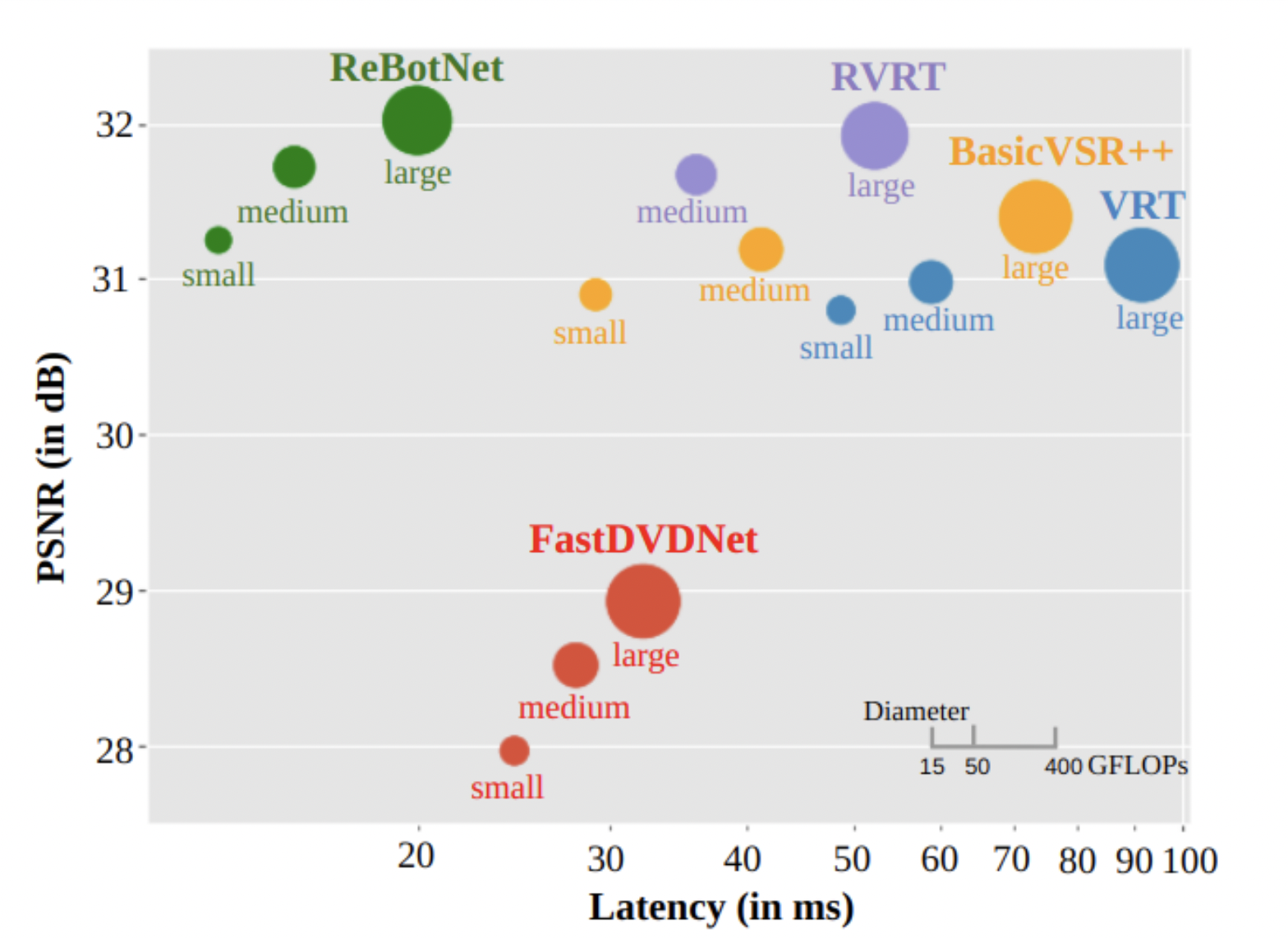
This approach is more efficient than techniques that use a stack of multiple frames as input. As for the achieved quality, some results are presented below and compared with state-of-the-art techniques.

The authors state that the proposed method is 2.5x faster than the previous state-of-the-art methods while either matching or slightly improving visual quality in terms of PSNR.
This was the summary of ReBotNet, a novel AI framework for real-time video enhancement.
If you are interested or want to learn more about this work, you can find a link to the paper and the project page.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 17k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.