Deci AI Unveils DeciDiffusion 1.0: A 820 Million Parameter Text-to-Image Latent Diffusion Model and 3x the Speed of Stable Diffusion
Defining the Problem Text-to-image generation has long been a challenge in artificial intelligence. The ability to transform textual descriptions into vivid, realistic images is a critical step toward bridging the gap between natural language understanding and visual content creation. Researchers have grappled with this problem, striving to develop models to accomplish this feat efficiently and effectively.
Deci AI introduces DeciDiffusion 1.0 – A New Approach To solve the text-to-image generation problem, a research team introduced DeciDiffusion 1.0, a groundbreaking model representing a significant leap forward in this domain. DeciDiffusion 1.0 builds upon the foundations of previous models but introduces several key innovations that set it apart.
One of the key innovations is the substitution of the traditional U-Net architecture with the more efficient U-Net-NAS. This architectural change reduces the number of parameters while maintaining or even improving performance. The result is a model that is not only capable of generating high-quality images but also does so more efficiently in terms of computation.
The model’s training process is also noteworthy. It undergoes a four-phase training procedure to optimize sample efficiency and computational speed. This approach is crucial for ensuring the model can generate images with fewer iterations, making it more practical for real-world applications.
DeciDiffusion 1.0 – A Closer Look Delving deeper into DeciDiffusion 1.0’s technology, we find that it leverages a Variational Autoencoder (VAE) and CLIP’s pre-trained Text Encoder. This combination allows the model to effectively understand textual descriptions and transform them into visual representations.
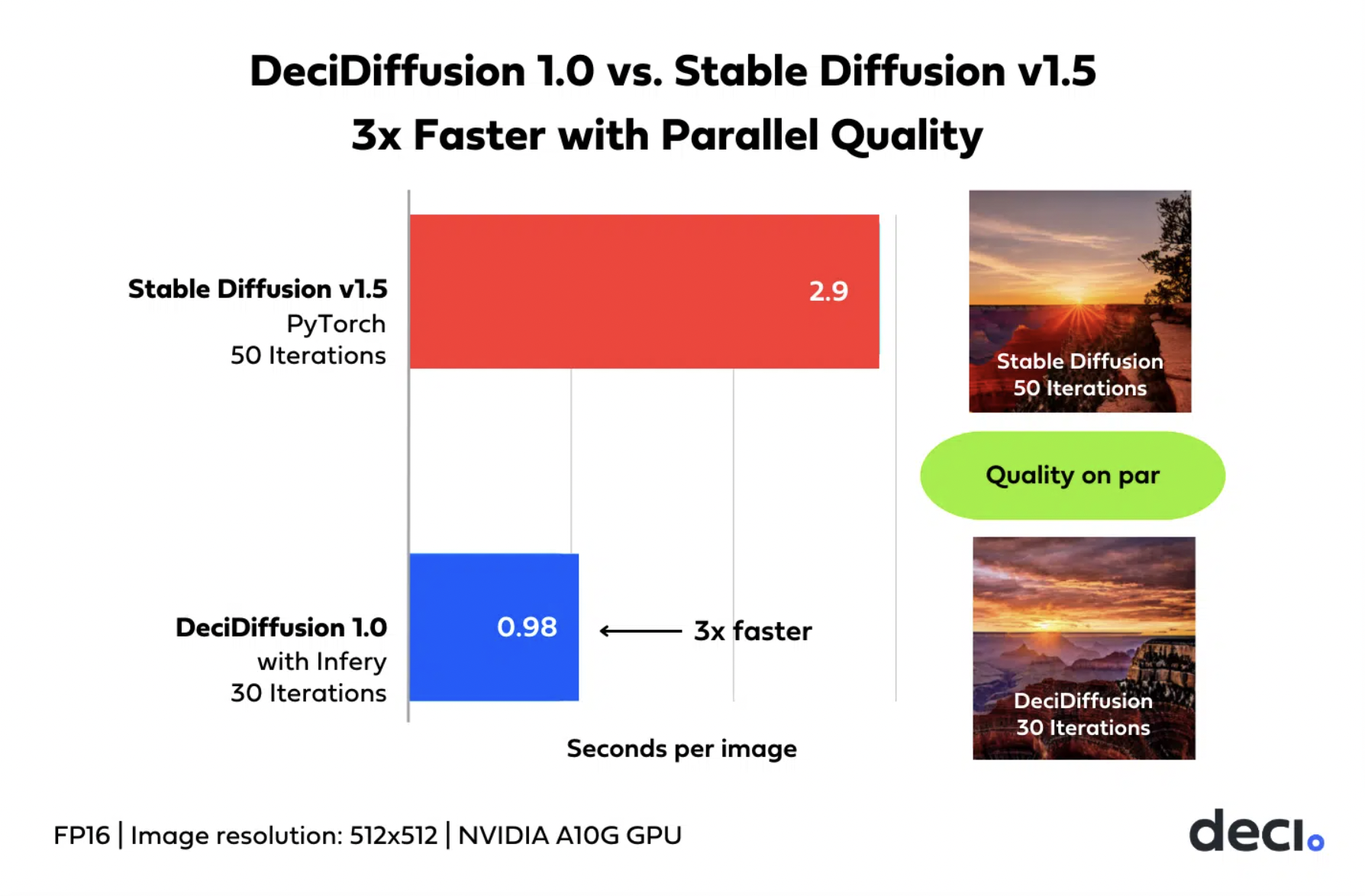
One of the model’s key achievements is its ability to produce high-quality images. It achieves comparable Frechet Inception Distance (FID) scores to existing models but does so with fewer iterations. This means that DeciDiffusion 1.0 is sample-efficient and can generate realistic images more quickly.
A particularly interesting aspect of the research team’s evaluation is the user study conducted to assess DeciDiffusion 1.0’s performance. Using a set of 10 prompts, the study compared DeciDiffusion 1.0 to Stable Diffusion 1.5. Each model was configured to generate images with different iterations, providing valuable insight into aesthetics and prompt alignment.
The user study results reveal that DeciDiffusion 1.0 holds an advantage in terms of image aesthetics. Compared to Stable Diffusion 1.5, DeciDiffusion 1.0, at 30 iterations, consistently produced more visually appealing images. However, it is crucial to note that prompt alignment, the ability to generate images that match the provided textual descriptions, was on par with Stable Diffusion 1.5 at 50 iterations. This suggests that DeciDiffusion 1.0 strikes a balance between efficiency and quality.
In conclusion, DeciDiffusion 1.0 is a remarkable innovation in a text-to-image generation. It tackles a long-standing problem and offers a promising solution. By replacing the U-Net architecture with U-Net-NAS and optimizing the training process, the research team has created a model that is not only capable of producing high-quality images but also does so more efficiently.
The user study results underscore the model’s strengths, particularly its ability to excel in aesthetics. This is a significant step in making text-to-image generation more accessible and practical for various applications. While challenges remain, such as handling non-English prompts and addressing potential biases, DeciDiffusion 1.0 represents a milestone in merging natural language understanding and visual content creation.
DeciDiffusion 1.0 is a testament to the power of innovative thinking and advanced training techniques in the rapidly evolving field of artificial intelligence. As researchers continue to push the boundaries of what AI can achieve, we can expect further breakthroughs that will bring us closer to a world where text seamlessly transforms into captivating imagery, unlocking new possibilities across various industries and domains.
Check out the Code, Demo, and Deci Blog. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.
Credit: Source link
Comments are closed.