Deciphering the Impact of Scaling Factors on LLM Finetuning: Insights from Bilingual Translation and Summarization
The intricacies in unlocking the latent potential of Large Language Models (LLMs) for specific tasks remain a complex challenge even after all the state-of-the-art achievements these models have shown throughout their development. The reason is primarily due to the vastness of the models and the subtleties associated with their training and fine-tuning processes.
Traditionally, two main approaches are employed for fine-tuning LLMs: full-model tuning (FMT), which adjusts all the model’s parameters, and parameter-efficient tuning (PET), which only tweaks a small subset. Each method has its strengths, with the former offering comprehensive adaptability at the cost of efficiency and the latter providing a more streamlined, albeit less flexible, alternative.
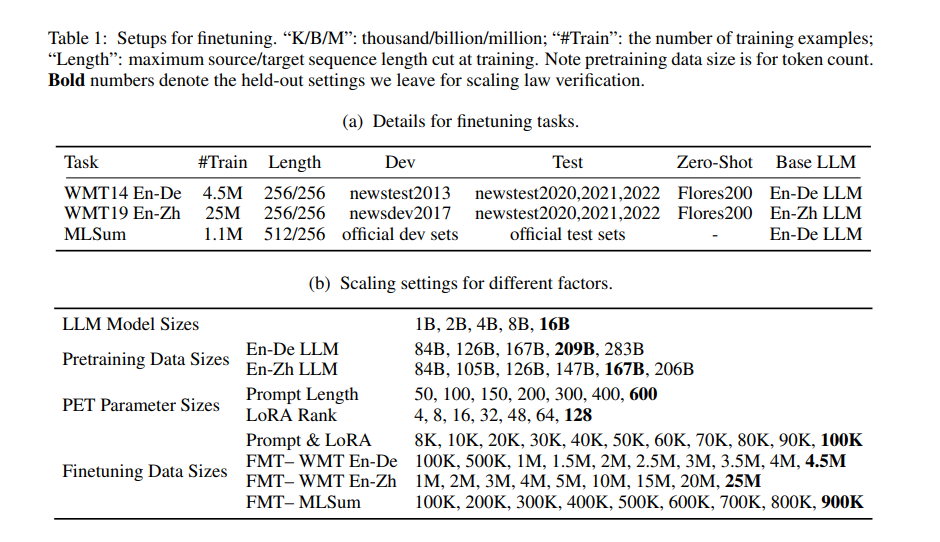
A study conducted by a team of researchers from Google Deepmind and Google Research explores these predominant fine-tuning strategies: FMT and PET, the latter encompassing techniques like prompt tuning and LoRA. These methods are evaluated in the context of bilingual machine translation and multilingual summarization tasks, leveraging bilingual LLMs that range from 1 billion to 16 billion parameters. This exploration is critical in understanding how each element contributes to the fine-tuning process, especially in scenarios where the amount of data available for fine-tuning is significantly smaller than the model’s capacity.
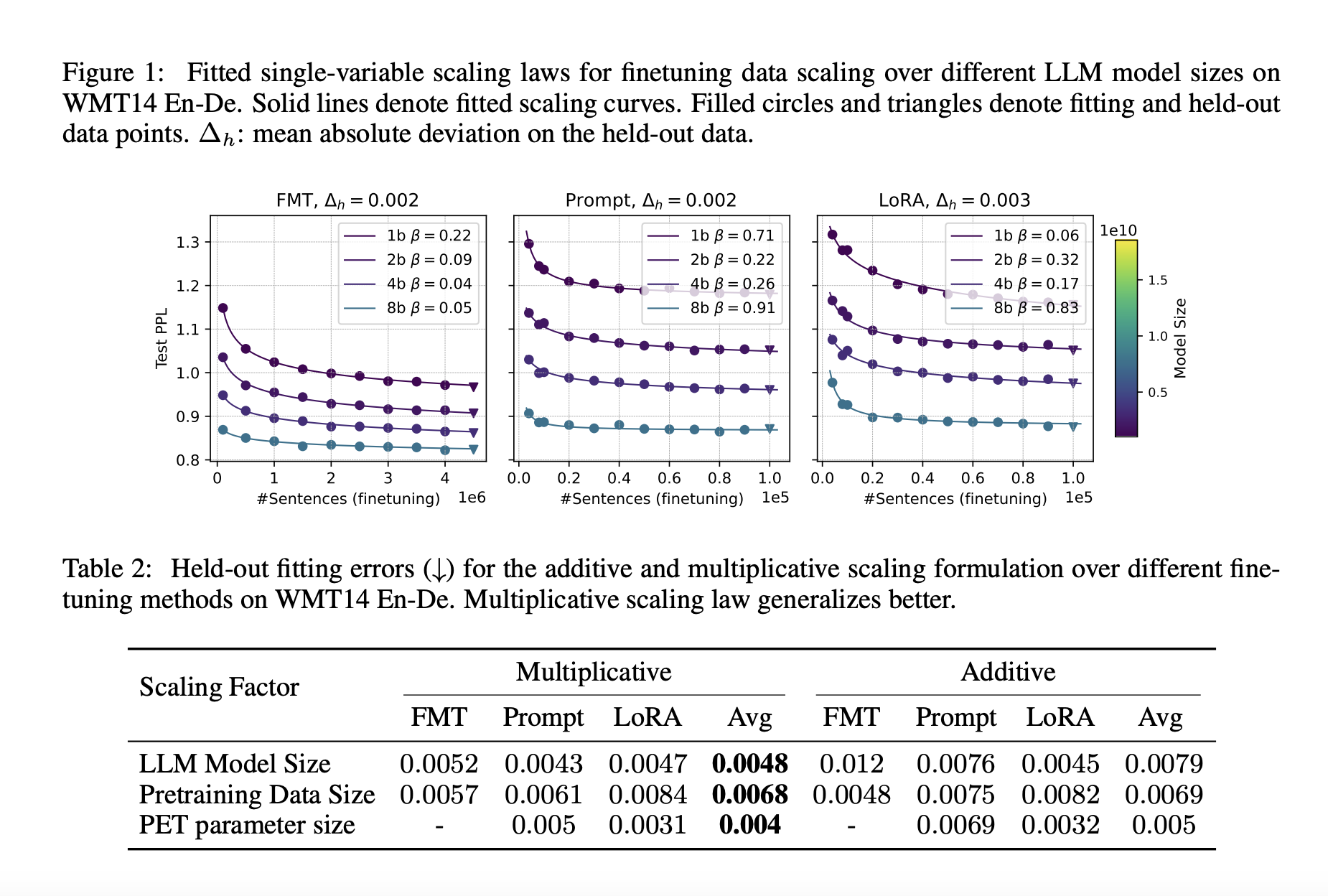
A noteworthy aspect of this research is the introduction of a multiplicative joint scaling law, which provides a novel way to quantify the interplay between fine-tuning data size and other scaling factors. The findings reveal that increasing the LLM model size has a more pronounced effect on fine-tuning performance than expanding the pretraining data or scaling up the PET parameters. Interestingly, PET techniques generally benefit less from parameter scaling than FMT, but they exhibit superior capabilities in leveraging the pre-existing knowledge encoded within the LLMs.
The empirical results from the study underscore a critical insight: the effectiveness of a fine-tuning method is highly dependent on the task at hand and the volume of data available for fine-tuning. For instance, in bilingual machine translation and multilingual summarization tasks, increasing the LLM model size from 1 billion to 16 billion parameters significantly enhances the fine-tuning performance.
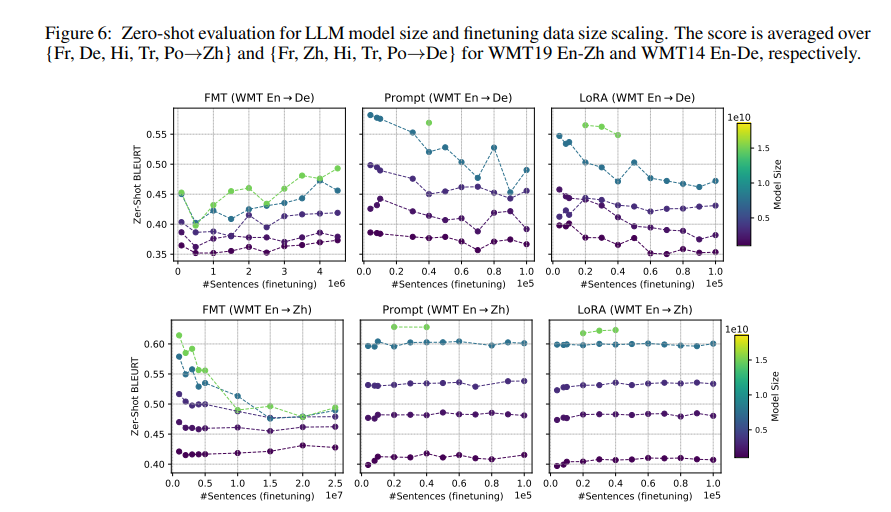
The research delves into zero-shot generalization, showcasing how fine-tuned models can enhance performance on tasks closely related to the fine-tuning objective, even without explicit training. This aspect is particularly illuminating, as it highlights the potential of fine-tuning in optimizing models for specific applications and broadening their applicability to a wider range of tasks.
In conclusion, the comprehensive study conducted by the Google DeepMind and Google Research team sheds light on the nuanced dynamics of LLM fine-tuning. By systematically analyzing the impact of various scaling factors, the research provides valuable guidelines for selecting and optimizing fine-tuning methods based on the specific requirements of the task and the available resources. This work advances our understanding of the fine-tuning process and opens new avenues for further research in making LLMs more adaptable and efficient for diverse applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link
Comments are closed.