Deciphering the Math in Images: How the New MathVista Benchmark is Pushing AI Boundaries in Visual and Mathematical Reasoning
MATHVISTA is introduced as a benchmark to assess the mathematical reasoning abilities of Large Language Models (LLMs) and Large Multimodal Models (LMMs) within visual contexts. The standard combines various mathematical and graphical tasks and includes existing and new datasets. Initial evaluations involving 11 prominent models, including LLMs, tool-augmented LLMs, and LMMs, reveal a substantial performance gap compared to human capabilities, indicating the need for further advancement. This benchmark is crucial for developing general-purpose AI agents with mathematical and visual reasoning abilities.
Current benchmarks assessing the mathematical reasoning skills of LLMs focus solely on text-based tasks, and some, like GSM-8K, show performance saturation. There’s a growing need for robust multimodal benchmarks in scientific domains to address this limitation. Benchmarks like VQA explore the visual reasoning capabilities of LMMs beyond natural images, covering a wide range of visual content. Generative foundation models have been instrumental in solving diverse tasks without fine-tuning, and specialized pre-training methods have improved chart reasoning in visual contexts. Recent works emphasize the growing importance of these models in practical applications.
Mathematical reasoning is a critical aspect of human intelligence with applications in education, data analysis, and scientific discovery. Existing benchmarks for AI mathematical reasoning are text-based and lack visual contexts. Researchers from UCLA, the University of Washington, and Microsoft Research introduce MATHVISTA, a comprehensive benchmark combining diverse mathematical and graphical challenges to evaluate the reasoning abilities of foundation models. MATHVISTA encompasses multiple reasoning types, primary tasks, and various visual contexts, aiming to improve the mathematical reasoning capabilities of models for real-world applications.
MATHVISTA, a benchmark to assess foundation models’ mathematical reasoning in visual contexts. It employs a taxonomy of task types, reasoning skills, and visual contexts to curate existing and new datasets. The benchmark includes problems that require deep visual understanding and compositional reasoning. Preliminary tests indicate the challenges it poses to GPT-4V, emphasizing its significance.
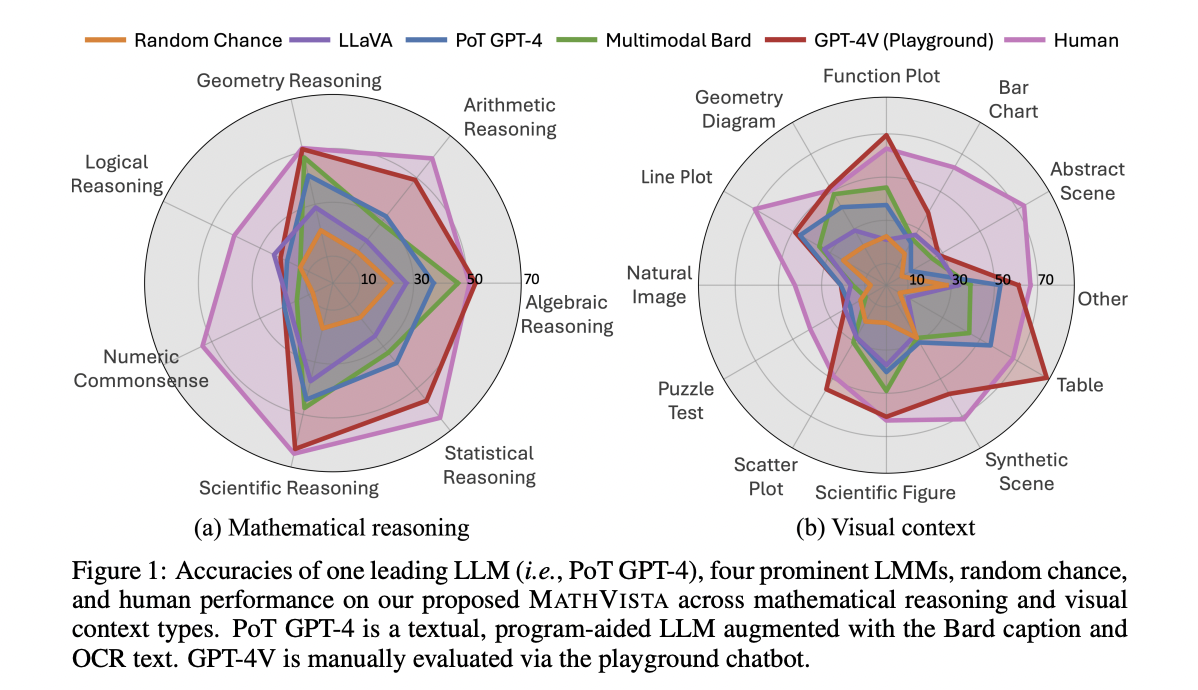
The MATHVISTA reveals that the best-performing model, Multimodal Bard, achieves an accuracy of 34.8%, while human performance is notably higher at 60.3%. Text-only LLMs outperform random baselines, with 2-shot GPT-4 reaching an accuracy of 29.2%. Augmented LLMs, equipped with image captions and OCR text, perform better, with 2-shot GPT-4 achieving 33.9% accuracy. Open-source LMMs like IDEFICS and LLaVA show underwhelming performance due to math reasoning, text recognition, shape detection, and chart understanding limitations.
In conclusion, the MATHVISTA study highlights the need for improving mathematical reasoning in visual contexts and the challenges in integrating mathematics with visual understanding. Future directions include developing general-purpose LMMs with enhanced mathematical and visual abilities, augmenting LLMs with external tools, and evaluating model explanations. The study emphasizes the importance of advancing AI agents to perform mathematically intensive and visually rich real-world tasks, which can be achieved through innovations in model architecture, data, and training objectives to improve visual perception and mathematical reasoning.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.