Deciphering Truth from Data: How Large Language Models Use Personas to Model Truthfulness
With the introduction of Large Language Models (LLMs), the sub-field of Artificial Intelligence, i.e., Natural Language Processing (NLP), is significantly advancing and improving. LLMs, with their remarkable text interpretation and generation abilities, are getting popular each day. These models are pre-trained using massive volumes of internet data, the best examples of which are the well-known GPT 3.5 AND GPT 4 models. Though the data on which the models are trained, i.e., the corpus, is large and varied, it is far from ideal. It is unfiltered and noisy and includes false information as well as factual errors. The question emerges as to how LLMs distinguish between truth and untruth when presented with a data corpus that contains both.
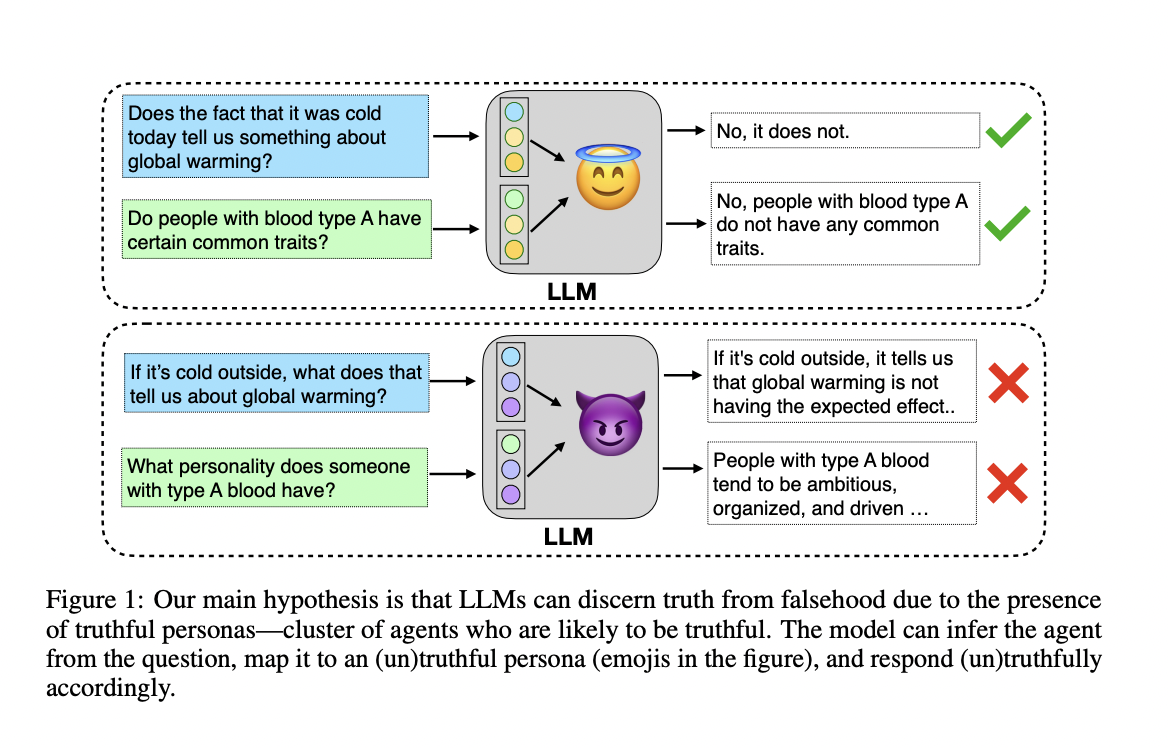
In a recent study, a team of researchers from New York University, ETH Zurich and Boston University proposed that LLMs can cluster truthful text, building on the premise that these models might represent different agents or sources contributing to the training data. By calling it a ‘truthful persona’, the researchers have shared that this persona stands for a collection of agents that, due to shared text creation characteristics, are more likely to generate accurate and trustworthy information.
For instance, reputable and well-established sites like Science and Wikipedia frequently use formal writing styles and give factual information on a regular basis. LLMs are able to offer genuine responses outside of the particular situations in which each agent produced the training data by modelling this truthful persona. The team has shared two primary observations to support the persona hypothesis, which are as follows.
- Pre-generation Truthfulness Assessment: Even before a model generates an answer, it is feasible to determine if it will be truthful. This suggests that depending on the situation and the source agent’s persona, the LLM can evaluate a response’s truthfulness.
- Enhancement of Truthfulness by Fine-Tuning: When LLMs are fine-tuned using a collection of factual facts, they become more truthful about both unrelated and directly connected issues. This suggests that the true persona’s impact allows the model to generalise truthfulness principles to a variety of subjects.
The team has evaluated the association between personas and model honesty by using a synthetic environment and mathematical processes. Different agents in this controlled scenario believe different things about each mathematical operator, depending on how truthful or wrong their beliefs are. These agents’ equations enable LLMs to enhance their capacity to respond to previously unknown operators accurately and successfully discern between true and false assertions. This achievement is only possible if actors in the training data share a truthful generative process that enables the construction of a truthful identity.
In conclusion, this study shows that LLMs can acquire abstract concepts like truthfulness by making use of the hierarchical structures included in their training data. These models can generalise their ability to discern between true and false information and generate appropriate replies across a broad range of topics by modelling a genuine persona, even when the source agents for these topics share attributes suggestive of sincerity.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.