Decoding Human Risky Choices: Unveiling Dataset Bias in Decision-Making Models Using Machine Learning
In understanding choices, there are two main models: normative and descriptive. Normative models explain why people should make certain decisions based on principles, while explanatory models aim to capture how people decide. One recent study claims to have found a more accurate model for predicting human decisions using neural networks trained on a large online dataset called choices13k.
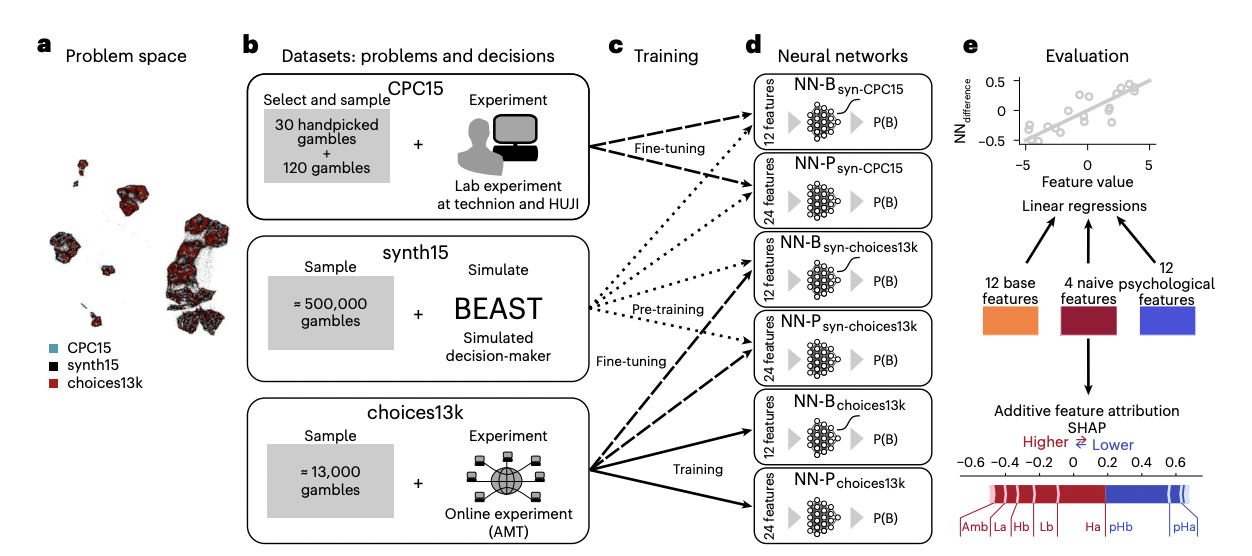
The researchers found something interesting when comparing different datasets and models. They discovered a bias in the choices13k dataset, where participants tended to favor options with equal appeal, even when other options were better. This bias made the researchers think there might be increased decision noise in the dataset, meaning more randomness in people’s choices.
To test this idea, they created a new model that added structured decision noise to a neural network trained on data from a traditional laboratory study. Surprisingly, this new model performed better than others, except those explicitly trained on the biased choices13k dataset. The study concludes that more than simply having a large dataset is needed to create accurate models of human decision-making. They emphasize the importance of combining theory, data analysis, and machine learning to understand how people make choices.
This study is part of a broader trend where machine learning, especially using neural networks, is being used to model human decision-making. This approach could lead to more accurate models and a better understanding of decision processes. However, the study also warns that carefully considering the relationship between models and datasets is crucial. They highlight dataset bias, where the data’s characteristics influence the models’ performance.
In their analysis, the researchers tested various machine-learning models on datasets from different studies. They found evidence of dataset bias, suggesting that the characteristics of the choices13k dataset influenced the performance of the models. By exploring the features of the gambles and using explainable artificial intelligence techniques, they identified three features related to the expected payoff of one option over another that predicted differences in model predictions between datasets.
In conclusion, the study emphasizes that size alone is insufficient for datasets. The data collection context and the data’s characteristics can significantly impact the performance of machine-learning models. They argue that combining machine learning, data analysis, and theory-driven reasoning is essential to predict and understand human choices accurately. As the field progresses, it’s crucial to carefully approach theory and data analysis integration for a comprehensive understanding of human decision-making.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.