Deep Learning for Computer Vision is not just Transformers: Facebook AI and UC Berkeley Propose a Convolutional Network for the 2020s

Looking back to the 2010s, those years were characterized by the resurgence of Neural Networks and, in particular, Convolutional Neural Networks (ConvNet). Since the introduction of AlexNet, the field has evolved at a very fast pace. ConvNets have been successful due to several built-in inductive biases, the most important of which is translation equivariance.
In parallel, the Natural Language Processing (NLP) field took a very different path, with Transformers becoming the dominant architecture.
These two streams converged in 2020 with the introduction of the Vision Transformer (ViT), which outperformed classic ConvNets when it comes to large datasets. But, the simple “patchify” layer at the beginning, which converts the full image into different patches treated as tokens, made the ViT unsuitable for fine-grained applications, such as semantic segmentation. Swin Transformers filled this gap with their sliding attention windows, which, funnily, made Transformers behave more like ConvNets.
At this point, a natural question would be: if researchers are trying to make Transformers behave like ConvNets, why not stick with the latter? The answer is that transformers have been always considered to have a superior scaling behavior that outperforms classical Convnets in many vision tasks.
In this paper, Facebook AI and UC Berkeley seek to refute this apparent superiority of Transformers by re-examining the design of ConvNets and testing their limitations. The proposed approach is based on gradually modifying a standard ResNet50, following design choices closely inspired by Vision Transformer, to propose a new family of pure ConvNets called ConvNeXt.
Roadmap
The first step was to establish a baseline to test the improvement due to the subsequent modifications. For this reason, a ResNet50 model was trained with up-to-date techniques (extending the number of epochs, using AdamW optimizer, Stochastic Depth, Label Smoothing, and so on), and surpassed the original version with an accuracy of 78.8% on ImageNet-1k. Then, a series of design decisions, summarized in the figure below, were implemented, regarding:
- Macro design
- ResNeXt
- Inverted Bottleneck
- Large kernel size
- Various layer micro design
For every step, the best-performing solution was used as the standard for the next step.
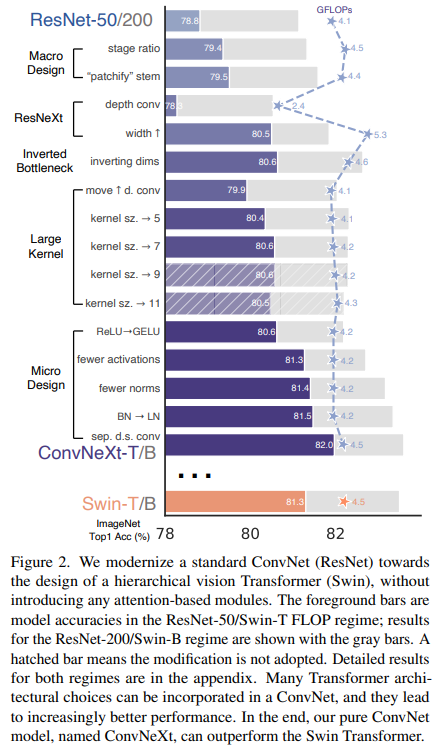
- Macro Design
The authors considered two aspects of Swin Transformers’ macro design. The first is the number of blocks in each stage (stage compute ratio), which was adjusted from (4, 4, 6, 3) to (3, 3, 9, 3), following the Swin Transformer ratio of (1:1:3:1). The second is the stem cell configuration, which in the original ResNet50 consisted of 7×7 convolutions with stride 2 followed by a max-pooling layer. This was substituted by a more Transformer-like “patchify” layer which utilizes 4×4 non-overlapping convolutions with stride 4.
These modifications improved the accuracy to 79.5%.
- ResNeXt
In this part, the authors adopt two design choices of the popular ResNeXt: depthwise convolutions, which are interestingly similar to self-attention as they work on a per-channel basis, and a higher number of channels (from 64 to 96).
These modifications improved the accuracy to 80.5%.
- Inverted Bottleneck
An essential configuration of Transformers is the expansion-compression rate in the MLP block (the hidden dimension is 4 times higher than the input and output dimension). This feature was reproduced by adding the inverted bottleneck design used in ConvNets (where the input is expanded using 1×1 convolutions and then shrunk through depthwise convolution and 1×1 convolutions).
This modification slightly improved the accuracy to 80.6%.
- Large kernel sizes
The gold standard in ConvNet since the advent of VGG are 3×3 kernels. Small kernels lead to the famous local receptive field, which, compared to the global self-attention, has a more limited area of focus. Although Swin Transformers reintroduced the concept of local attention, their window size has always been at least 7×7. To explore larger kernels, the first thing is to move the depthwise convolution before the convolution, to reduce the number of channels before such an expensive operation. This first modification resulted in a temporary degradation to 79.9%, but, experimenting with different sizes, with a 7×7 window (higher values did not bring any alterations in the results), the authors were able to achieve an accuracy of 80.6% again.
- Micro Design
Finally, some micro design choices were added: GELU instead of ReLU, a single activation for each block (the original transformer module has just one activation after the MLP), fewer normalization layers, Batch Normalization substituted by Layer Normalization, and separate downsampling layer.
These modifications improved the accuracy to 82.0% and defined the final model, named ConvNeXt.
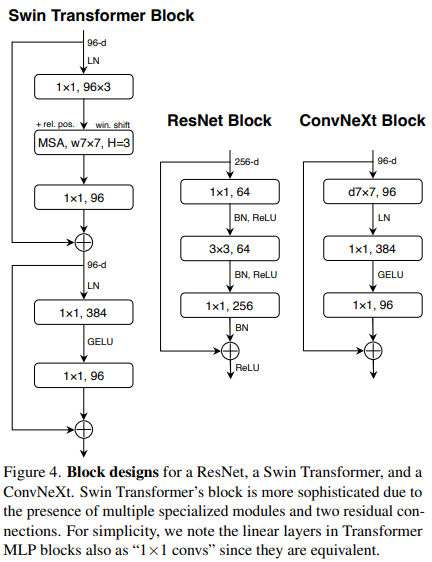
A comparison of this architecture with the Swin Transformer and ResNet is shown in the figure below.
Conclusion
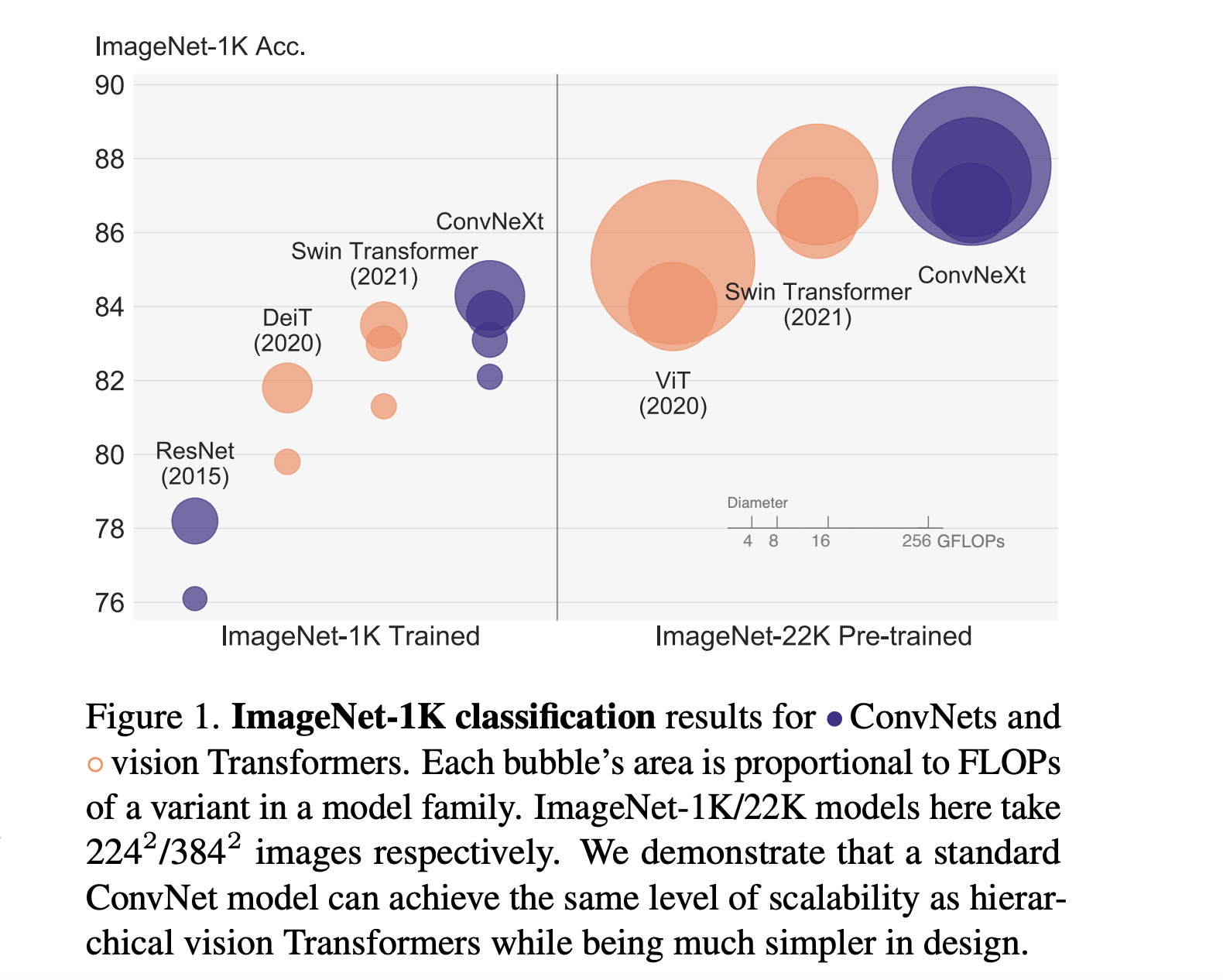
Based entirely on convolutions, this model competed on par with Transformer-based architectures, achieving a top-1 accuracy of 87.8% on ImageNet classification. Equally excellent results were obtained in other tasks, such as object detection and segmentation on COCO and semantic segmentation on ADE20K.
The idea of modernizing ConvNets, adding all the concepts introduced over the past decade to a single model, is payback for convolutions, which have been ignored lately to the benefit of transformers. It is not yet clear who will win the final battle, but we can say with certainty that ConvNets will still have many surprises to show us.
Paper: https://arxiv.org/pdf/2201.03545.pdf
Github: https://github.com/facebookresearch/ConvNeXt
Suggested

Credit: Source link
Comments are closed.