Deepmind AI Researchers Introduce ‘DeepNash’, An Autonomous Agent Trained With Model-Free Multiagent Reinforcement Learning That Learns To Play The Game Of Stratego At Expert Level
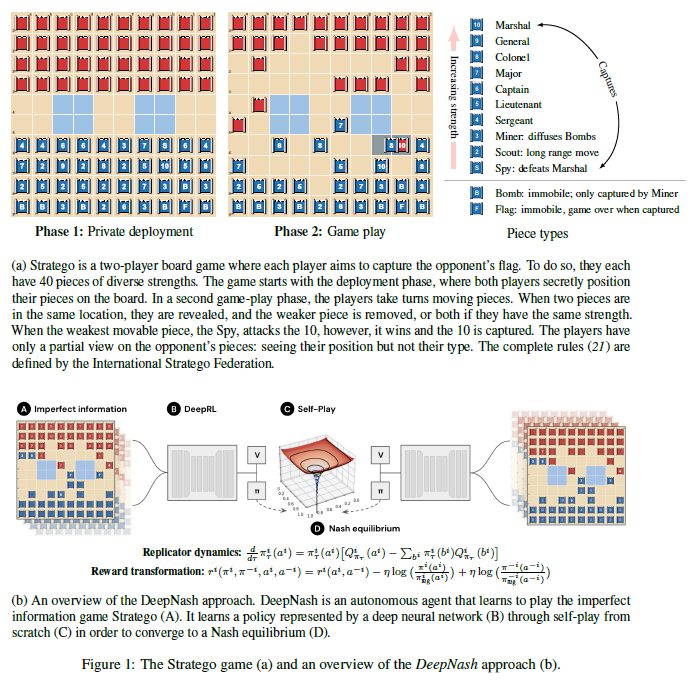
For several years, the Stratego board game has been regarded as one of the most promising areas of research in Artificial Intelligence. Stratego is a two-player board game in which each player attempts to take the other player’s flag. There are two main challenges in the game. 1) There are 10535 potential states in the Stratego game tree. 2) Each player in this game must consider 1066 possible deployments at the beginning of the game. Due to the various complex components of the game’s structure, the AI research community has made minimal progress in this area.
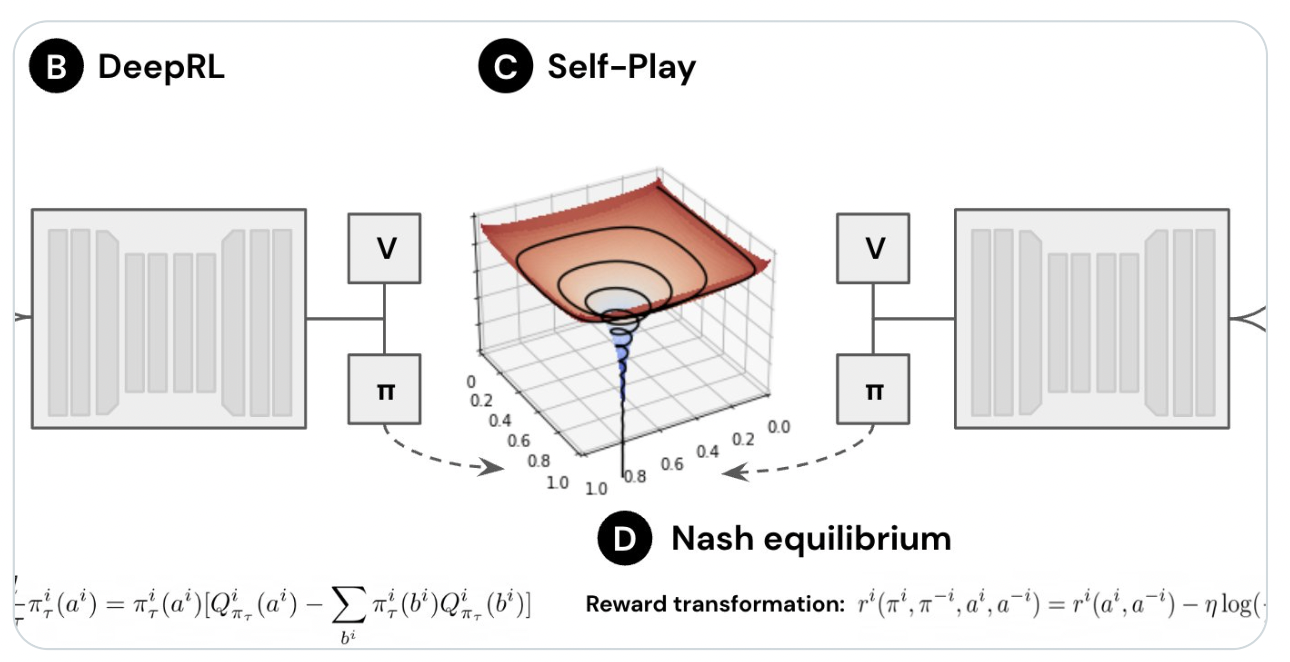
This research introduces DeepNash, an autonomous agent that can develop human-level expertise in the imperfect information game Stratego from scratch. Regularized Nash Dynamics (R-NaD), a principled, model-free reinforcement learning technique, is the prime backbone of DeepNash. DeepNash achieves an ε-Nash equilibrium by integrating R-NaD with deep neural network architecture. A Nash equilibrium ensures that the agent will perform well even when faced with the worst-case scenario opponent. The stratego game and a description of the DeepNash technique are shown in Figure 1.
DeepNash comprises three parts: a fundamental training component R-NaD, fine-tuning the learned policy, and test-time post-processing. R-NaD depends on three significant stages: reward transformation, dynamics, and update. Moreover, DeepNash’s R-NaD learning method is built on the concept of regularization for convergence. The DeepNash network comprises four heads, each of which is a smaller version of the torso and has final layers added along with residual blocks and skip connections. The first DeepNash head generates the value function as a scalar, but the three other heads encode the agent’s policy by developing a probability distribution during gameplay and deployment.
DeepNash’s dynamics stage is divided into two sections. The first portion estimates the value function by adapting the v-trace estimator to the two-player imperfect information case. The second phase, utilizing an estimate of the state action value based on the v-trace estimator, learns the policy through the Neural Replicator Dynamics (NeuRD) update. Fine-tuning is carried out during training by applying extra thresholding and discretization to the action probabilities.
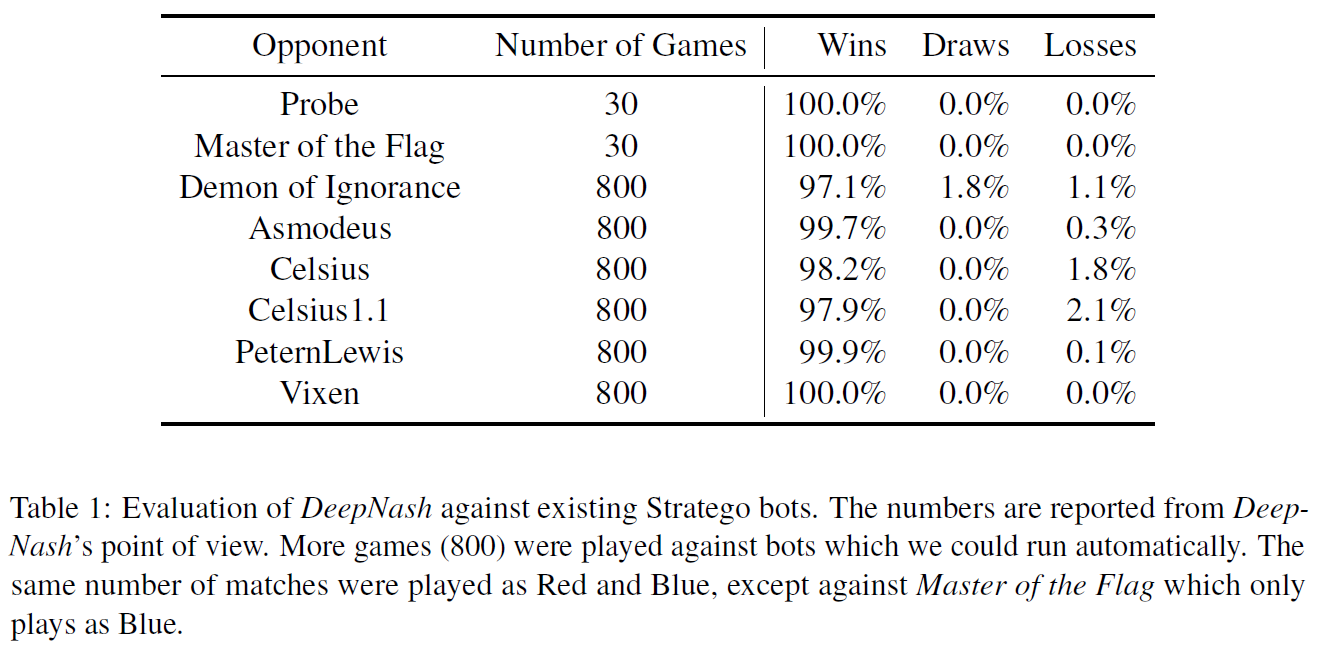
DeepNash’s performance is evaluated using the Gravon platform and eight well-known AI bots. DeepNash was tested against top human players for two weeks in early April 2022, yielding 50 ranking matches in which DeepNash won 42%. Hence, it equates to a rating of 1799 in the Classic Stratego challenge ranking 2022, which placed DeepNash in third place out of all Gravon Stratego players. This also resulted in a rating of 1778 for all-time Classic Stratego, placing DeepNash in the third position among all ranked Gravon Stratego players. Despite not being given the training against any of the bots and merely using self-play, Table 1 depicts that DeepNash wins the vast majority of games.
In this game, the key to being unexploitable is having an unpredictable deployment, and DeepNash can produce billions of such implementations. DeepNash can make trade-offs; for example, a player must weigh the worth of capturing an opponent’s piece and thus giving information about their piece versus not capturing a piece but keeping the identity of a piece hidden. Additionally, DeepNash can handle situations involving occasional bluff, negative bluff, and complex bluff.
On the Gravon platform, DeepNash has a minimum win rate of 97% against other AI bots and an overall win rate of 84% against human-expert players. DeepNash can open up new opportunities for Reinforcement Learning methods in imperfectly known real-world multi-agent issues with astronomical state spaces that are now beyond the scope of existing state-of-the-art AI techniques.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.