DeepMind and UCL’s Comprehensive Analysis of Latent Multi-Hop Reasoning in Large Language Models
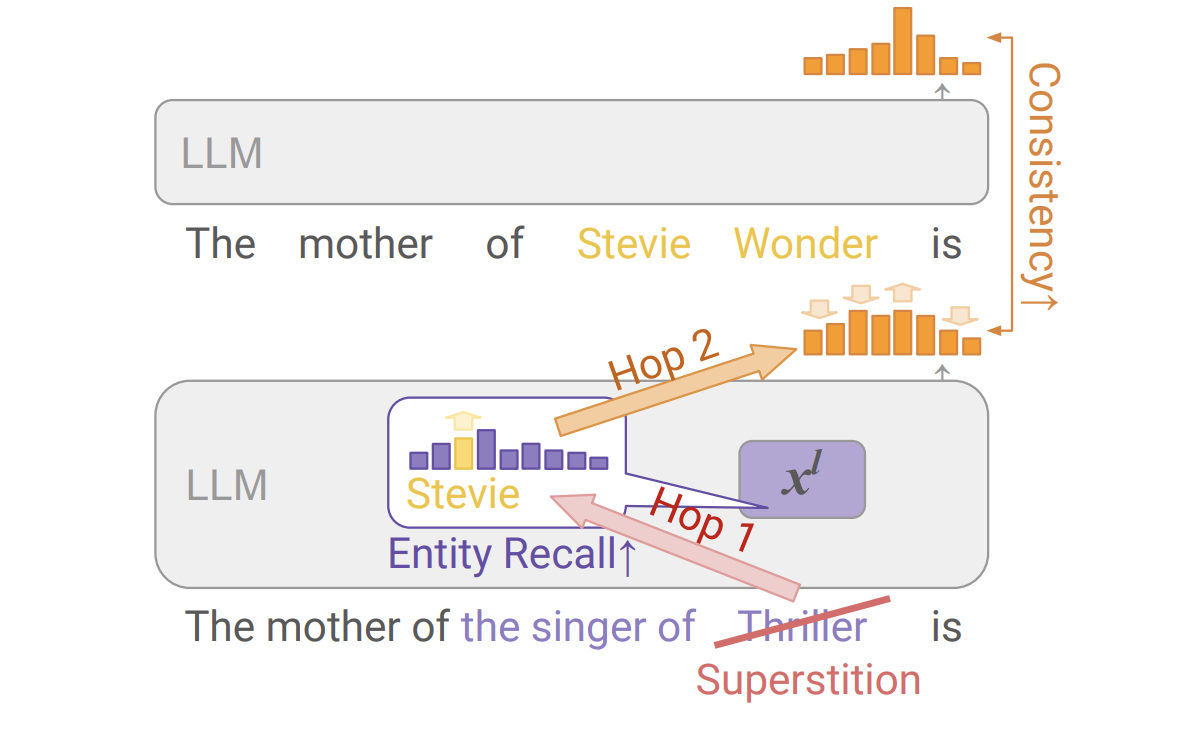
In an intriguing exploration spearheaded by researchers at Google DeepMind and University College London, the capabilities of Large Language Models (LLMs) to engage in latent multi-hop reasoning have been put under the microscope. This cutting-edge study delves into whether LLMs, when presented with complex prompts requiring the connection of disparate pieces of information, can internally navigate their vast stores of implicit knowledge to generate coherent responses.
The essence of multi-hop reasoning lies in its requirement for an entity not only to retrieve relevant information but also to link it sequentially to solve a problem or answer a query. The research meticulously evaluates this process by examining LLMs’ responses to intricately designed prompts that necessitate bridging two separate facts to generate a correct answer. For example, a query indirectly asking for Stevie Wonder’s mother by referring to him as “the singer of ‘Superstition’” tests the model’s ability to make the necessary logical leaps.
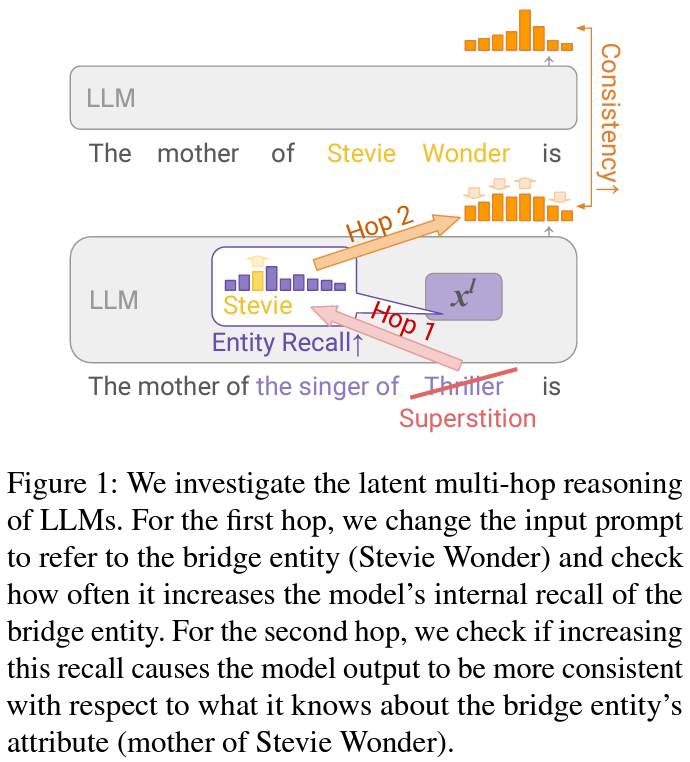
The researcher’s methodology offers a fresh perspective on assessing LLMs’ multi-hop reasoning faculties. By focusing on the models’ proficiency in recalling and applying specific pieces of information, known as bridge entities, when faced with indirect prompts, the study pioneers a new way of quantifying this advanced reasoning capability. Through an array of experiments involving models of different sizes, the paper sheds light on how LLMs navigate these complex cognitive tasks.
The performance metrics and results unveiled by this research are enlightening and indicative of the current limitations LLMs face in this domain. Evidence of latent multi-hop reasoning was observed, albeit in a contextually variable manner. The study revealed that while LLMs can exhibit this form of reasoning, their performance is significantly influenced by the structure of the prompt and the relational information within. A notable finding from the research is the scaling trend observed with model size; larger models demonstrated improved capabilities in the initial hop of reasoning but did not exhibit the same level of advancement in subsequent hops. Specifically, the study found strong evidence of latent multi-hop rationale for certain types of prompts, with the reasoning pathway utilized in more than 80% of the cases for specific fact composition types. However, on average, the evidence for the second hop and the full multi-hop traversal was moderate, indicating a potential area for future development.
This groundbreaking research concludes with a reflection on the potential and limitations of LLMs in performing complex reasoning tasks. The Google DeepMind and UCL team posits that while LLMs show promise in latent multi-hop reasoning, the capability is markedly influenced by the context and the specific challenges the prompts present. They advocate for advancements in LLM architectures, training paradigms, and knowledge representation techniques to further enhance these models’ reasoning capabilities. The study advances our understanding of the operational mechanisms of LLMs. It paves the way for future research to develop AI systems with sophisticated cognitive abilities akin to human reasoning and problem-solving.
By meticulously analyzing LLMs’ latent multi-hop reasoning capabilities, this study offers invaluable insights into the intricate workings of AI models and their potential to mimic complex human cognitive processes. The findings underscore the importance of continued innovation in AI research, particularly in enhancing the reasoning capabilities of LLMs, to unlock new possibilities in AI’s cognitive and problem-solving abilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.