DeepMind Introduces ‘Enformer’, A Deep Learning Architecture For Predicting Gene Expression From DNA Sequence

DNA contains the genetic information that influences everything from eye color to illness and disorder susceptibility. Genes, which are around 20,000 pieces of DNA in the human body, perform various vital tasks in our cells. Despite this, these genes comprise up less than 2% of the genome. The remaining base pairs in the genome are referred to as “non-coding.” They include less well-understood instructions on when and where genes should be created or expressed in the human body.
DeepMind, in collaboration with their Alphabet colleagues at Calico, introduces Enformer, a neural network architecture that accurately predicts gene expression from DNA sequences.
Earlier studies on gene expression used convolutional neural networks as key building blocks. However, their accuracy and usefulness have been hampered by problems in modeling the influence of distal enhancers on gene expression. The proposed new method is based on Basenji2, a program that can predict regulatory activity from DNA sequences of up to 40,000 base pairs.
The team expressed a need for a fundamental architectural modification to capture extended sequences and understand whether the regulatory DNA elements influence expression at greater distances.
The new model is based on Transformers to leverage self-attention processes to absorb considerably more DNA background. The Transformers are built to “read” substantially expanded DNA sequences because they are suitable for looking at long text sections. The model architecture can describe the influence of critical regulatory regions called enhancers on gene expression from further away within the DNA sequence. It does this by successfully processing sequences to consider interactions at distances greater than five times (i.e., 200,000 base pairs) than earlier methods.

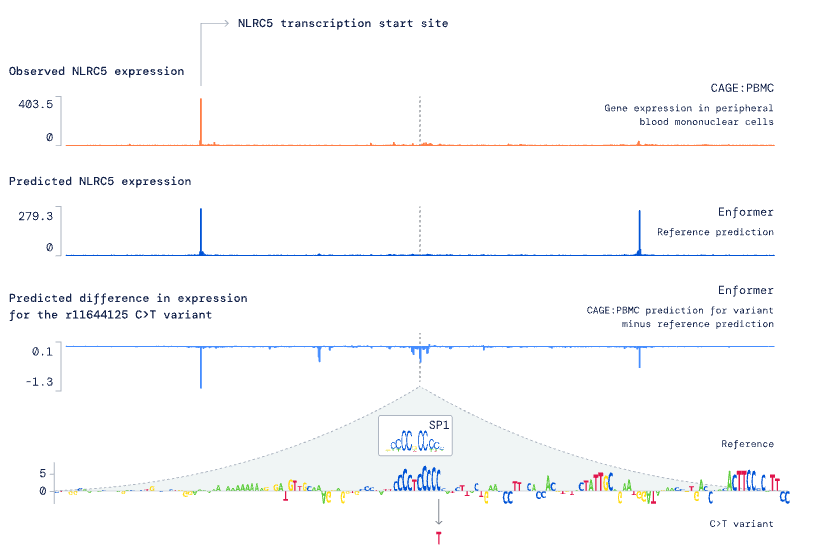
The researchers used contribution scores to highlight which parts of the input sequence were most relevant for the prediction to better understand how Enformer interprets the DNA sequence to arrive at more accurate predictions. The findings suggest that the model paid attention to enhancers even if they were more than 50,000 base pairs away from the gene, corresponding to biological intuition. The contribution scores of Enformer are comparable to existing techniques created specifically for this task, which is impressive. Enformer also learned about insulator elements, which separate two independently regulated areas of DNA.

Although it is now feasible to analyze an organism’s DNA, understanding the genome requires complex studies. Despite extensive research, the vast majority of DNA regulation of gene expression remains a mystery. Enformer recognizes the vocabulary of the DNA sequence in part, similar to a spell checker, and may thus indicate modifications that potentially change gene expression.
The primary purpose of this new approach is to forecast which changes to the DNA letters, commonly known as genetic variations, would affect the gene’s expression. Enformer outperforms earlier models in predicting the impact of genetic variants on gene expression, both in natural genetic variants and synthetic variants that change critical regulatory regions. This characteristic helps decipher the expanding number of disease-associated variations discovered in genome-wide association studies.
Enformer is a significant step forward in complex genomic sequence studies. The team intends to collaborate with other researchers and organizations interested in using computational models to answer the big problems in genomics.
Paper: https://www.nature.com/articles/s41592-021-01252-x
Source: https://deepmind.com/blog/article/enformer
GitHub: https://github.com/deepmind/deepmind-research/tree/master/enformer
Suggested
Credit: Source link
Comments are closed.